Advanced Machine Learning 3 | Boosting, AdaBoosting, and Gradient Boosting

1. Adaboosting For Binary Classification
(1) The Definition of Boosting
The idea behind boosting is that if we can combone many weak learners, we can become a strong learner as a whole. If we recall bagging, what we want are some models with low bias and high variance, and we take weighted average for reducing the variance. But for boosting, what we want are models with high bias, and we call these models as weak learners.
(2) Decision Boundary with Tree Classifiers
Suppose we have a binary classification tree defined as,
Then the result of of a forest with trees should be,
Where is the weight of the tree .
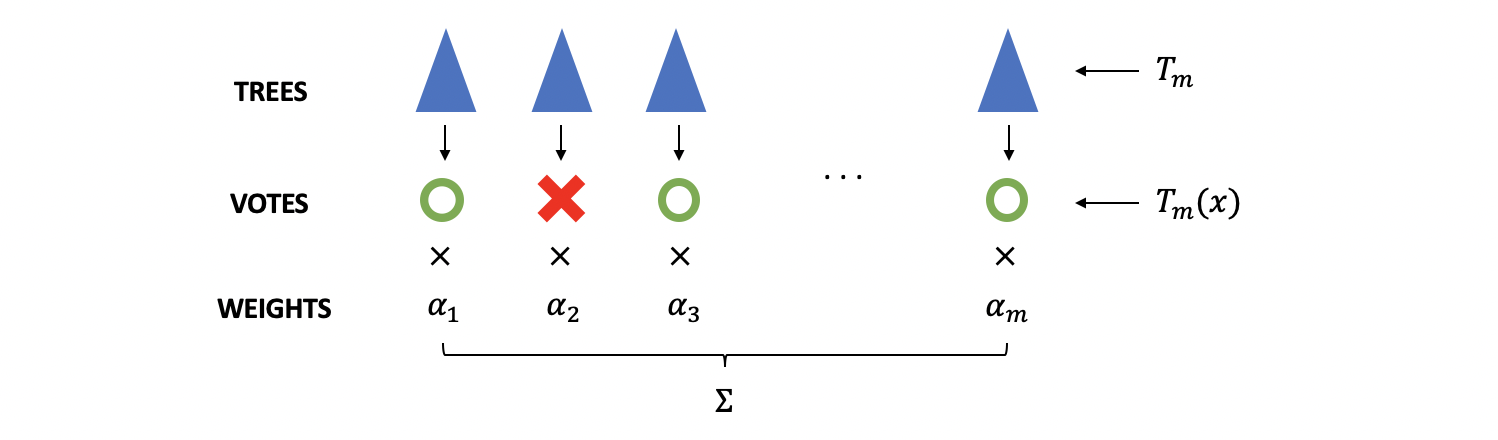
Because we have,
And if and are correctly classified, we have,
Which is equivalent to,
Because the sign won't impact this inequation, then
If we note the prediction as a function named , then we can write the inequation above as,
The left term in the binary classification problem is called the margin. Therefore, we can write,
But there remains one condition, and let's see what happens when we have . This is equivalent to,
Because,
we must have,
In this case, we have equal votes from both sides by M trees, so we can not make a clear classification on which class to predict. Because of that, is actually defined as the decision boundary of the two classes.
(3) Recall: Log Loss For Binary Classification
Suppose we have the true value and the predicted values as . Recall we have discussed that the log loss for binary classification defined as,
Note that we assume predicts the cluster of and predicts the cluster of . Then the equation above can be written as,
Suppose we take soft prediction of compared with the hard prediction in (1) with , we have, in this case,
Which is,
Then we have when ,
And when ,
Thus, with soft prediction of , we have,
So this can also be written as,
Where .
If we use the term for this loss function, we can have,
(4) Exponential Loss and Hinge Loss
Here, we are going to introduce two more loss functions. The exponential loss function is defined as,
And thee Hinge loss is defined as,
If we plot these three loss functions (i.e. log loss, exponential loss, and hinge loss) together, we can have,
171import matplotlib.pyplot as plt2import numpy as np34x = np.linspace(-2,5,100)56y1 = np.log(1 + np.exp(-x))7y2 = np.exp(-x)8y3 = np.maximum(0, 1-x)910fig, ax = plt.subplots(1,1,figsize=(10,5))11ax.plot(x, y1, label="logloss")12ax.plot(x, y2, label="exponential")13ax.plot(x, y3, label="hinge")14ax.axhline(0, c='r', ls="--", alpha=.5)1516plt.legend()17plt.show()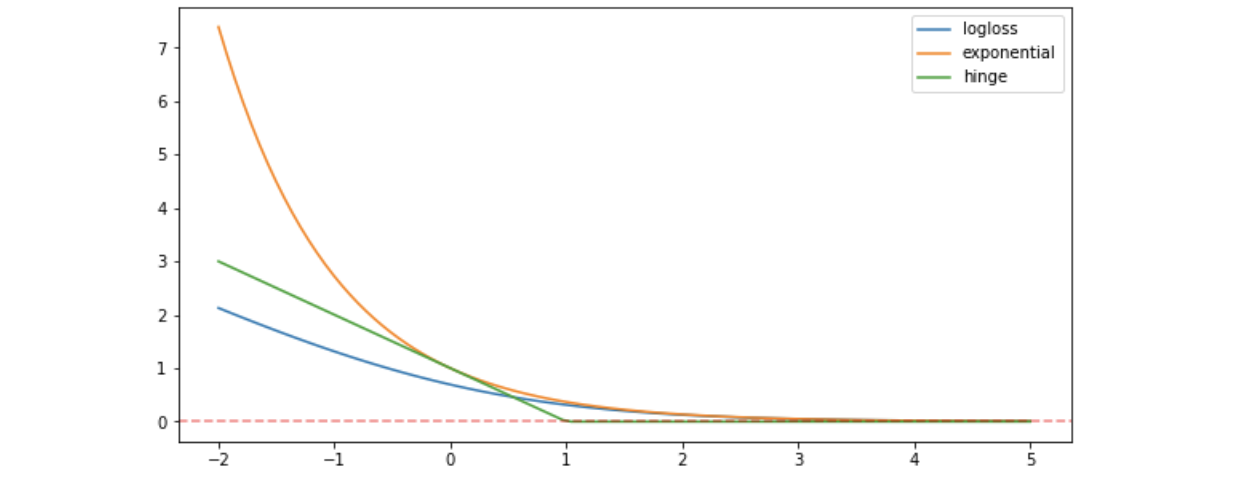
From this plot, we can know that the loss function penalize much on the negative margins but less on the positive margins.
(5) Loss Function for AdaBoosting
AdaBoosting is using exponential loss function as defined because it classify instead of . And because exponential loss penalizes much more than the other loss functions, AdaBoosting is less robust to outliers.
For AdaBoosting, we have the overall loss function is,
Assume our AdaBoosting model is an additive model as follows,
Where is the weight for each tree as our parameters. So we have the loss function as,
Or we can write the expression above in a vectorized way,
Using the indicator function , we can write the expression above as,
In order to optimize this AdaBoosting model, we have to minimize this loss function for trees and their weights,
So for a specific tree , suppose the weight of this tree is , then its loss can be written as,
This is also,
If we define the error rate as,
Then we have,
To minize the loss for this tree, we have,
So,
Solve and then we can have,
Then,
We can also note , and this will be useful in the following discussions. So is
(6) Training AdaBoosting
For training the AdaBoosting, let's first denote the weight for each point as , and the weight of each point means how much we care about this point if it is misclassified. Initially, the weights should be set evenly as .
Then in the iteration , we have the weight of point updated by the result of tree , so,
When , this means we do not misclassify the result, and the expression above should be,
When , this means we do misclassify the result, and the expression above should be,
We can rewrite this problem by multiply to both conditions,
For the fact that,
We then have,
Where,
So the predictions after iterations should be,
Since we have a binary classification problem, then the hard predictions are,
Note that can be ignored in this equation.
(7) Pseudo Code for AdaBoosting

2. Gradient Boosting
(1) Idea of Gradient Boosting
The idea behind gradient boosting is that we adding weak learners for approaching the true value . Suppose we have weak learners and the prediction after learners is,
Therefore, we can define the loss function between the prediction and the true value as their difference. We can use MSE, MAE, log loss, or some other loss functions to represent this difference.
Note that this loss fuction is a forward stepwise loss that requires us to define a starting point ,
Where is some constant we select for this optimization.
In order to reach the optimized model, we have to minimize the loss function by steps. So in step 0, we have to solve,
And then in each step, we have to find a model that minimize the loss function,
So the idea of gradient boosting is quite similar to gradient descent because we have,
Note that because we don't know the gradient here, we have to use a model to fit the difference between two iterations, and this difference is called the pseudo residual, which is defined as,
Which is also,
(2) Best Initial Constant
We have discussed that our model must start with a constant that minimize the loss function in step 0. So the best initial constant is selected based on the loss function.
- For MSE: we select
- For MAE: we select
We can easily prove why these two constants are the best for MSE and MAE. But for the log loss, it can be tricky for calculating the best initial constant. Let's suppose we have a loss function,
So the best constant should be found by,
Then,
So,
Because , and we can define as the number of and as the number of . So we have,
Therefore,
So,
Then,
So,
And,
Note that we have,
So is also,
(3) General Tree Gradient Boosting
As we have already defined the pseudo residual is,
Within each iteration, we can fit a regression tree model with to ,
And then we can derive several terminal regions from this tree . Then for each , make new predictions by minizing the loss fuction,
And then we should update with the new predictions,
(4) Pseudo Residual For Logloss
Since we have the definition of pseudo residual as,
And the logloss is defined by,
Then,
This is also,
So,
(5) Pseudo Residual For MSE and MAE
For MSE, the pseudo residual is quite simple with,
Then,
For MAE, the loss function is,
Then,
This is to say we have,
Then,
So that we can conclude that, for MAE, the pseudo result can be written as,
(6) Pseudo Residual for Exponential Loss
We can continue to derive the pseudo residual for exponential loss. The loss function is defined as,
So for the definition of pseudo residual,
(7) Pseudo Residual for Hinge Loss
The last pseudo residual we are going to have a look at is with the hinge loss. Suppose the loss function is,
It can also be written as,
Then the gradient of to is,
So we have,
(8) Best Constant Per Region for Logloss
After getting the pseudo residual and fitting the model , then, the next step is to find the optimal constant per region. For logloss, that is,
Then the derivative is,
Because doesn't have a closed form solution, we will use the following rule for estimating
So, firstly, is ,
Note that,
And,
So,
Therefore,
(9) General Pseudo Code for Gradient Tree Boosting

(10) Pseudo Code for Gradient Tree Boosting with MAE Loss

(11) Pseudo Code for Gradient Tree Boosting with MSE Loss
