Advanced Machine Learning 4 | Neural Networks

1. Introduction of Neural Networks
(1) Recall: Logistic Regression
Remember we have a logistic model which is a linear model with a sigmoid function in the end. The loss function of this model is,
Recall the reason why we use a sigmoid function in the end is that we would like to make the final decision function differentiable compared with a indication function.
(2) Recall: Backpropagation
Recall in the section 2, we have talked about the backpropagation and it is used for computing the gradient of the loss function on parameters. It is actually a special case of a more general algorithm called reversemode automatic differentiation that can compute the gradient of any differentiable function efficiently.
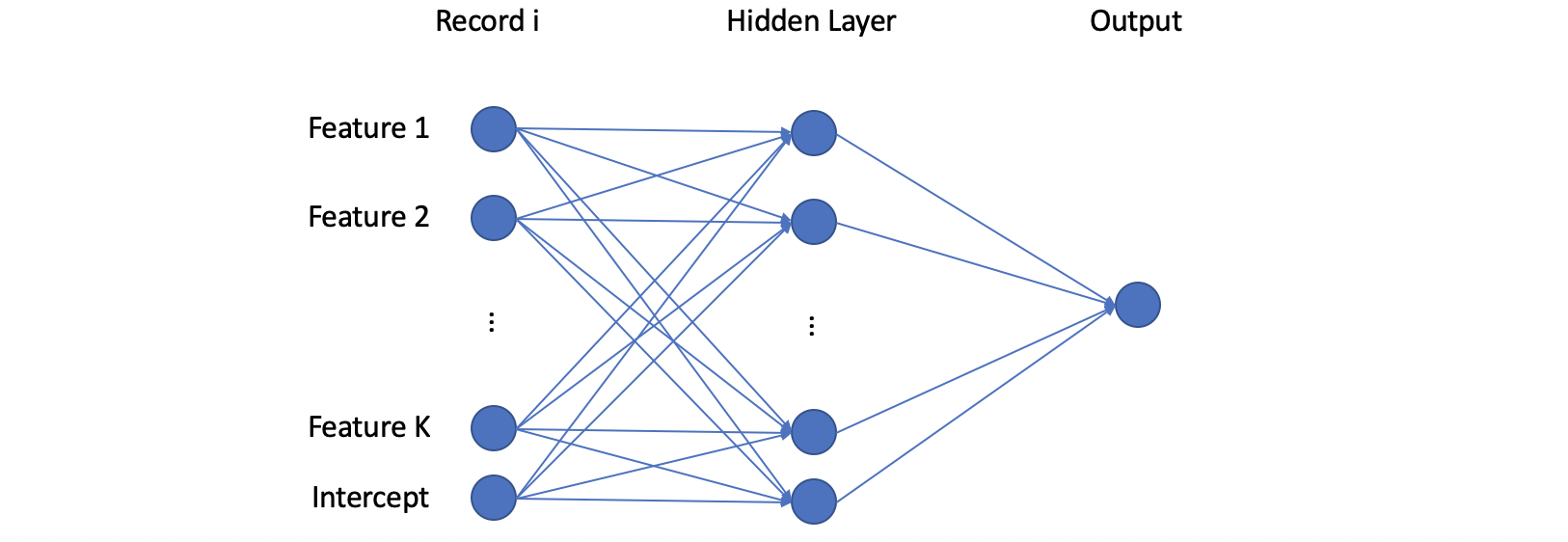
(3) Basic Model of Neural Network
Now, let's see the basic model of the neural network. Suppose we have the training set with shape with records, and is the record in that training set with length . Then the first layer in the network is defined as the linear layer,
Then we take the activation function of the result from the first layer, and we have,
Suppose we have a hidden layer with M neurons, then we have,
And the final output of this network is,
We can plot this network as follows.
(4) Matrix Form of Neural Network
We have talked about the one record neural network, and now it's time to go through the matrix expressions. It is quite trick that the dataset is a matrix and we have to transpose this matrix to before fitting it into the layer.
Where, is a matrix of shape and is a column vector with length . As a result, the output in this layer has a shape of .
The activation layer then takes place to transform to with the same shape. Then in the hidden layer, the is a matrix with shape because we have only one node in the output layer.
(5) Number of Parameters in a Neural Network
Let's continue to see the parameters we have in the network above. The number of the parameters equals the number of elements in all the matrics and vectors. Suppose in one layer we have the weights parameter matrix and the intercept vector . Then the shape of will be,
And the length of vector should be,
So in a layer with the # of neurons in the last layer as and the # of neurons in the next layer as , we will have the total number of parameters as,
(6) Example of Neural Network Parameters
Now, let's see a real case example. Suppose we have a dataset X with N records and D features, and we have two hidden layers with M_1 neurons and M_2 neurons, respectively. Suppose we have a multiple classification problem with the number of classes as n_classes. Then how many parameters do we have in the model with the following PyTorch definition?
1model = nn.Sequential(2nn.Linear(D, M_1),3nn.ReLU(),4nn.Linear(M_1, M_2),5nn.ReLU(),6nn.Linear(M_2, n_classes),7nn.Softmax()8)
So based on the conclusion we have above,
xxxxxxxxxx41# of params in the first layer = (D + 1) * M_12# of params in the second layer = (M_1 + 1) * M_23# of params in the last layer = (M_2 + 1) * n_classes4total # of params = (D + 1) * M_1 + (M_1 + 1) * M_2 + (M_2 + 1) * n_classes
Note that this result is totally irrelevant to , so the number of the records we used to fit the neural network won't affect the number of parameters we have in that model.
2. Categorical Embedding
(1) Problems of Traditional Encoding Methods
For categorical variables, we usually encode them with one-hot encoding or hash encoding. But are these traditional techniques good for deep learning models? Nope, because there are several problems.
For one-hot encoding,
- Too many features: even though we can perform PCA for dimension reduction, this also means that we will lose some information
- Lose some information: if we see these informations as completely discrete variables, we will lose some information. For example, the state
californiaandnevadais close to each other but if we encode them as discrete variables with the same distance, we will lose the position information.
For hash encoding,
- Hard to find hyperparameter : we don't actually know how many hyperparameters we should use for this encoding
- Conflicts between elements
However, is there a technique that can encode categorical variables from the information it learn from the model?
(2) The Definition of Categorical Embedding
For categorical embedding, we map each value of a categorical variable to a dimensional vector. So for a class value , the embedded value of this class has a length of ,
Suppose we have classes for a categorical variable, then the size of the embedding matrix is,
If we want to embed a specific class , the first step is to find that class in the embeddding matrix by its rows. And then extract that corresponding row as the embedded vector of the class .
(3) Case Study: Pinterest Related Pins
Please refer to the following article Related Pins at Pinterest for more information.
- Pins: Pins are bookmarks that people use to save content they love on Pinterest.
- Boards: A Pinterest board is a collection where users save specific pins.
Suppose we have the pin ids and we would like to know which pins are related to each other, then what should we do is to, first embedding pins to pin vectors. Consider a pin ID encoded by one-hot encoding with size , where the value is the maximum ID we have for a pin. Then, we will use the embedding matrix with size (where is the embedding size) for embeding this ,
We can also compute this on a related pin ID and then make it as our target,
Then we will fit the following softmax model,
For this model, we can also write it as a matrix form. Suppose we have a dataset with shape , where is the number of records in our dataset and is the maximum number pin ID (we can also call it as vocabulary size). So the model should be,
So in this model we have the number of parameters as,
We do not use this model for predictions. Intead, we will extract the final embedding matrix in this model because it perfectly contains the information we need for each pin ID. So in this case, we can then use the transpose of this embedding matrix of as our training set to fit another KNN model. And the result of that K-nearest neighbourhood model will tell us that the pins that are clustered together are supposed to have strong relations.