Data Acquisition 4 | Term Frequency — Inverse Document Frequency
Data Acquisition 4 | Term Frequency — Inverse Document Frequency

- Tokenization
(1) The Definition of Tokenization
Given a character sequence (string) or a defined document unit, tokenization is the task of chopping it up into pieces (smaller chunks), called tokens. For example, we can tokenize the following string,
'He can can a can.'
By,
then,
['He', 'can', 'can', 'a', 'can', '.']
If you are meeting a punkt error, please refer to the article,
We can also at the same time throwing away certain characters, such as punctuation.
Note that the process of tokenization is one step in preparing for NLP.
(2) String Split vs. Tokenizing
Someone may think that the tokenizing is similar to split. However, this is not right. The tokenizing method achieves tokens in the linguistics sense, while the string split based only on the specific character. We can see the following example,
By tokenizing,
word_tokenize('I\'m not split.')then, we are going to have,
['I', "'m", 'not', 'split', '.']
By string split,
'I\'m not split.'.split(' ')then, we are going to have,
["I'm", 'not', 'split.']
(3) Word Token vs. Word Type
See Wikipedia for more information.
The main difference between token and type is the type of a string only includes distinct tokens. For example, we can get the type by,
then,
['He', 'can', 'a']
2. TFIDF
(1) The Definition of the Term Frequency
People always talking about the term frequency and the term means token. It is defined by,
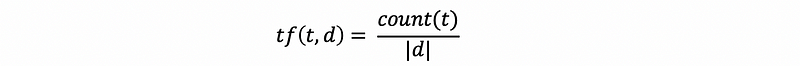
where d is a specific document and |d| means the number of terms in this d file.
Suppose we are given three documents,
d1 = "in the new york times in"
d2 = "the new york post"
d3 = "the los angeles times"
docstrs = [d1,d2,d3]
then we can calculate the term frequency of each document by,
the output is,
[[('in', 0.3333333333333333),
('the', 0.16666666666666666),
('new', 0.16666666666666666),
('york', 0.16666666666666666),
('times', 0.16666666666666666)],
[('the', 0.25), ('new', 0.25), ('york', 0.25), ('post', 0.25)],
[('the', 0.25), ('los', 0.25), ('angeles', 0.25), ('times', 0.25)]](2) The Definition of the Document Frequency
The document frequency is defined by the number of documents with a specific term divided by the number of all terms of all documents, which is,
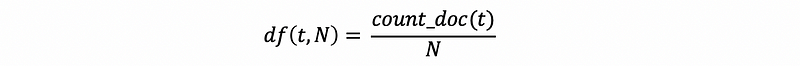
where N is the number of all the terms in all the documents.
then we can calculate the document frequency of each document by,
the output is,
[('in', 0.3333333333333333),
('the', 1.0),
('new', 0.6666666666666666),
('york', 0.6666666666666666),
('times', 0.6666666666666666),
('post', 0.3333333333333333),
('los', 0.3333333333333333),
('angeles', 0.3333333333333333)](3) Additive Smoothing Document Frequency
To use the additive smoothing method (we don’t have to understand this) onto the document frequency, we are supposed to get a better result,
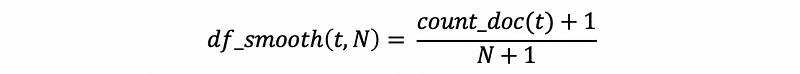
The program of the additive smoothing document frequency is,
The output of this program is,
[('in', 0.5),
('the', 1.0),
('new', 0.75),
('york', 0.75),
('times', 0.75),
('post', 0.5),
('los', 0.5),
('angeles', 0.5)](4) Inverse Additive Smoothing Document Frequency
The IDF is the inverse document frequency, it can be calculated by,
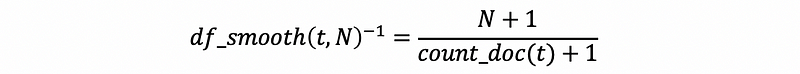
Then the program is,
The output of this program is,
[('in', 2.0),
('the', 1.0),
('new', 1.3333333333333333),
('york', 1.3333333333333333),
('times', 1.3333333333333333),
('post', 2.0),
('los', 2.0),
('angeles', 2.0)](5) Log Inverse Additive Smoothing Document Frequency
The log IDF is the log result of the inverse document frequency, it can be calculated by,
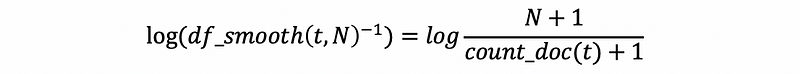
it doesn’t matter whether you are using 2, e, or 10 for the basement of the log because it won’t change the overall rank of this document frequency. We choose to use 10 as our basement but you can also replace this with some other values,
The output of this program is,
[('in', 0.3010299956639812),
('the', 0.0),
('new', 0.12493873660829993),
('york', 0.12493873660829993),
('times', 0.12493873660829993),
('post', 0.3010299956639812),
('los', 0.3010299956639812),
('angeles', 0.3010299956639812)](6) Combine All the Results
We have calculated TFs and IDF, then we want to combine them in a data frame. The program should be,
The output is,
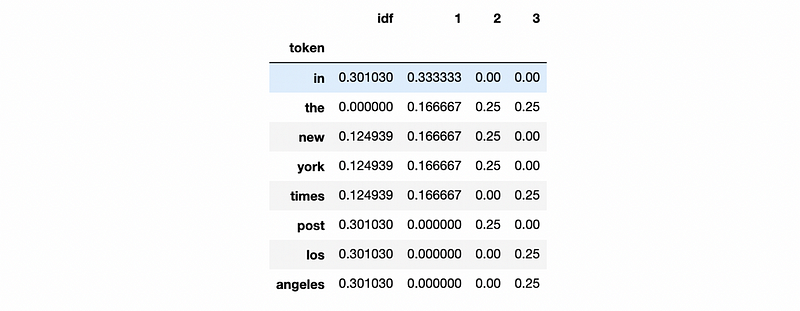
(7) Calculate TF-IDF
The TFIDF can be calculated by,
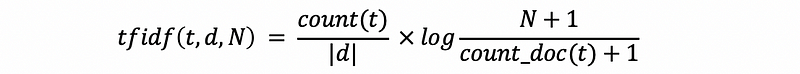
The program is,
The output is,
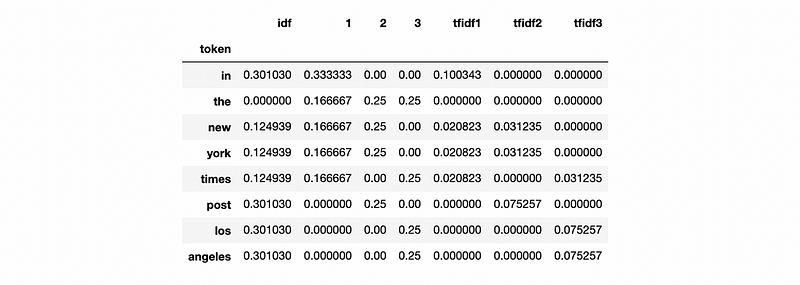
3. TFIDF with Sklearn
(1) Count Vectorizer
We can calculate the following matrix by sklearn, this matrix is called the count vectorizer,
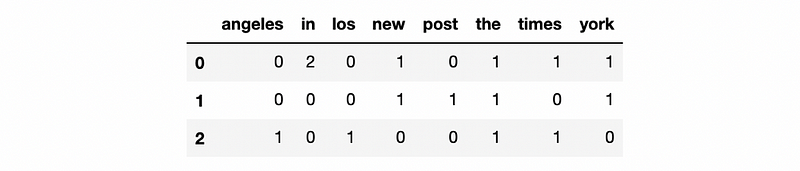
This table counts terms in each document and it provides us all the information that we have to collect in order to calculate TFIDF. The program is,
(2) TFIDF by Sklearn
Because count vectorizer X gives us all the information that we need to calculate TFIDF, then we can calculate TFIDF by this matrix,
the output of this program is,

Note that we have a different result of TFIDF, this is because the formula that sklearn uses to calculate IDF has a sight difference from our formula. In general, it won’t change our final conclusion because of this difference.