Distributed Computing 2 | Introduction to Spark and Basic Spark Examples
Distributed Computing 2 | Introduction to Spark and Basic Spark Examples

- Introduction to Spark
(1) The Introduction to Spark
Apache Spark is a fast and general-purpose cluster computing system and it is intended to handle large-scale data. Spark is built on top of the Scala language.
(2) Spark Vs. Hadoop
Hadoop is entirely dependent on MapReduce, which is designed to solve the issues of,
- Distribution: Distribute the data.
- Parallelism: Perform subsets of the computation simultaneously.
- Fault Tolerance: Handle component failure.
However, it can be very slow because MapReduce needs to store results in HDFS (i.e. Hadoop file system) before they can be used by another job. The HDFS is related to the disk, and it can be really slow on file I/O.
Spark is faster than Hadoop because Spark uses only the memory for file I/O. This means Spark can also hide the low-level interfaces and languages which can be difficult for the users.
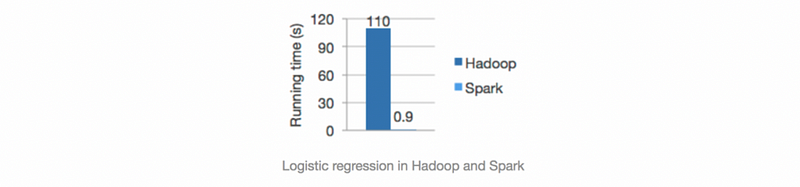
(3) Benefits of Using Spark
- Fast Speed: Spark has an advanced directed acyclic graph (i.e. DAC) execution engine that supports cyclic data flow and in-memory computing.
- Ease of Use: We can quickly write Spark applications in Java, Scala, Python, R.
- Generality: Spark powers a stack of libraries including SQL, streaming, and complex analytic tools.
- Compatibility: Spark can run on different platforms like Hadoop, Mesos, standalone, or in the cloud.
- Accessibility: Spark can access diverse data sources including HDFS, Cassandra, HBase, and S3.
(4) The Structure of Spark
The structure of Spack is called a Spark stack, which has three layers,
- Applications Layer: Including Spark SQL (used to treat the data with the data frame based on the RDD), Spark MLlib (the Spark machine learning library and it will not be covered in this series), Spark Streaming, and Spark GraphX
- Processing Engine Layer: This layer refers to the Spark core which manages to distribute the job, store fundamental functions, and manage RDD objects.
- Cluster Resource Management Layer: This can be either the Standalone Scheduler cluster manager, the Hadoop YARN cluster manager, or the Apache Mesos cluster manager. In this series, we will only talk about the Standalone Scheduler cluster manager.
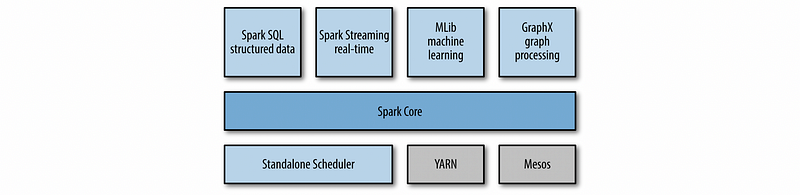
There is also another layer of the distributed file system we need to support the whole distributed system, which can be,
- Hadoop Distributed File System (HDFS)
- Cassandra
- Amazon S3
- HBase
- OpenStack Swift
- etc.
(5) The Definition of Resilient Distributed Dataset (RDD)
The RDDs are abstractions of distributed collections of items with operations and transformations applicable to the dataset. RDD is a new object type supported by Spark and it is not a list type.
It is called resilient because if it failed, it is going to rebuild itself instead of recover from the latest version, so we are actually not going to store the data somewhere in the disk and copy them back after failures. Because of this reason, RDD is immutable, and we can only store the result after conducting some operations on the RDD to some new RDDs.
(6) Spark Core
Spark core contains Spark functionalities required for running jobs and needed by other components. It contains
- All the RDDs
- Fundamental functions: file I/O, scheduling, shuffling, security, networking, etc.
(7) Spark SQL
The Spark SQL provides functions for manipulating large sets of distributed, structured data using an SQL subset. It transforms operations on DataFrames to operations on RDDs so that it can support a variety of data sources,
- Hive
- JSON
- Relational databases
- NoSQL databases
- Parquet files
(8) Spark MLlib
Spark MLlib is the library of machine learning algorithms. It includes logistic regression, naïve Bayes, support vector machine, decision trees, random forests, linear regression, and k-mean clustering. The API of this library is based on the DataFrames and the RDD-based API is now in maintenance mode, which means it will probably not be supported in the future. You can find some reasons why MLlib switches to the DataFrame-based API here.
(9) Spark Streaming
Spark Streaming is used to ingest real-time streaming data from various sources including HDFS, Kafka, Flume, Twitter, ZeroMQ, and etc.
(10) Spark GraphX
Spark GraphX provides functions for building graphs, represented as graph RDDs : EdgeRDD and VertexRDD. It also contains important algorithms of graph theory such as page rank, connected components, shortest paths, SVD++.
(11) The Applications of Spark
There are applications of Spark and here is a list of them,
- Extract-Transformation-Load (i.e. ETL) operations and processing: building the data pipeline
- Predictive analytics
- Machine learning
- Data access operation (SQL queries and visualizations)
- Text mining and text processing
- Real-time event processing
- Graph applications
- Pattern recognition
- Recommendation engines
- etc.
2. Spark Components
(1) The Definition of Spark Context
Spark Context is the entry gate of Apache Spark functionality. The most important step of any Spark driver application is to generate SparkContext. It allows your Spark application to access Spark clusters with the help of the resource manager (Standalone/YARN/Mesos). Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program (called the driver program).
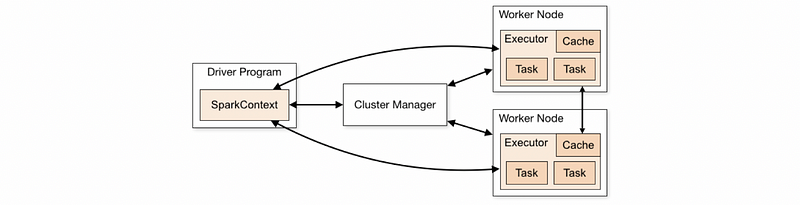
- Step 1: SparkContext connect to cluster manager
- Step 2: Spark acquires executors on nodes in the cluster
- Step 3: Spark sends the application code to the executors
- Step 4: SparkContext sends tasks to the executors to run
(2) Example of Spark Context
To try the SparkContext , let’s first write a program for testing.
- Let’s first import the Spark,
import pyspark
- To initialize a
SparkContextobject withappNameofTest, we should call
sc = pyspark.SparkContext(appName='Test').getOrCreate()
Now we have a Spark Context assigned to the variable sc and the current program used to generate this Spark Context is called a driver program.
- If we want to stop running a Spark Context, we should call,
sc.stop()
- To show the general Spark Context information, we can call,
sc.getConf().getAll()
(3) Spark UI
Spark has a UI that we can check states of jobs, storage, and executors. To assign a typical port for UI, we have to call SparkConf() before we call getOrCreate().
- Set APP name
conf = pyspark.SparkConf().setAppName("Test")- Set IP to
localhost
conf = pyspark.SparkConf().set("spark.driver.host", "localhost")- Set port to
4050
conf = pyspark.SparkConf().set("spark.ui.port", "4050")- Assign the configurations
confto theSparkContext
sc = pyspark.SparkContext(conf=conf)
- Open the Spark UI
# GOTO:
http://localhost:4050
(4) Spark I/O
Now, let’s use Spark for reading a local file.
- Create a
CSVfile namedTest.csv
file = open("Test.csv", "w")
for i in range(20):
file.write(str(i) + ',' + str(i+1) + "\n")
file.write(str(0) + ',' + str(1))
file.close()- Read from this
Test.csvfile by Spark
rdd = sc.textFile("Test.csv", minPartitions=8)- Or we can read the data from a
listor annp.array
rdd = sc.parallelize(data)- Print all the data in RDD
print(rdd.collect())
The output should be,
['0,1', '1,2', '2,3', '3,4', '4,5', '5,6', '6,7', '7,8', '8,9', '9,10', '10,11', '11,12', '12,13', '13,14', '14,15', '15,16', '16,17', '17,18', '18,19', '19,20', '0,1']
- Print the data in each partition of that RDD
nulls = [print(i) for i in rdd.glom().collect()]
The output should be,
['0,1', '1,2', '2,3', '3,4']
['4,5', '5,6', '6,7']
['7,8', '8,9', '9,10']
['10,11', '11,12']
['12,13', '13,14', '14,15']
['15,16', '16,17']
['17,18', '18,19']
['19,20', '0,1']
(5) Spark Data Processing
- Split the data (we have to assign the result to a new RDD because it is immutable)
rdd_split = rdd.map(lambda x: [int(x.split(",")[0]), int(x.split(",")[1])])
print(rdd_split.collect())The result should be,
[[0, 1], [1, 2], [2, 3], [3, 4], [4, 5], [5, 6], [6, 7], [7, 8], [8, 9], [9, 10], [10, 11], [11, 12], [12, 13], [13, 14], [14, 15], [15, 16], [16, 17], [17, 18], [18, 19], [19, 20], [0, 1]]
- Filtering the data
rdd_reduced = rdd_split.filter(lambda x: x[0] < 5)
nulls = [print(i) for i in rdd_reduced.glom().collect()]
The result should be,
[[0, 1], [1, 2], [2, 3], [3, 4]]
[[4, 5]]
[]
[]
[]
[]
[]
[[0, 1]]
- Flat Map the list result
rdd_flat = rdd_reduced.flatMap(lambda x: x)
nulls = [print(i) for i in rdd_flat.glom().collect()]
The result should be,
[0, 1, 1, 2, 2, 3, 3, 4]
[4, 5]
[]
[]
[]
[]
[]
[0, 1]
- Get the unique result in all the numbers
rdd_0 = rdd_flat.distinct()
nulls = [print(i) for i in rdd_0.glom().collect()]
The result should be,
[0]
[1]
[2]
[3]
[4]
[5]
[]
[]
- Sort the result by descending
rdd_sort = rdd_split.sortBy(lambda x: x[0], ascending=False)
nulls = [print(i) for i in rdd_split.glom().collect()]
print("\n========================= After Sorting ========================")
nulls = [print(i) for i in rdd_sort.glom().collect()]
The result should be,
[[0, 1], [1, 2], [2, 3], [3, 4]]
[[4, 5], [5, 6], [6, 7]]
[[7, 8], [8, 9], [9, 10]]
[[10, 11], [11, 12]]
[[12, 13], [13, 14], [14, 15]]
[[15, 16], [16, 17]]
[[17, 18], [18, 19]]
[[19, 20], [0, 1]]
========================= After Sorting ========================
[[19, 20], [18, 19]]
[[17, 18], [16, 17], [15, 16]]
[[14, 15], [13, 14]]
[[12, 13], [11, 12], [10, 11]]
[[9, 10], [8, 9], [7, 8]]
[[6, 7], [5, 6]]
[[4, 5], [3, 4], [2, 3]]
[[1, 2], [0, 1], [0, 1]]