High-Performance Computer Architecture 12 | Data Dependency Problems, Register Renaming, and…
High-Performance Computer Architecture 12 | Data Dependency Problems, Register Renaming, and Instruction Level Parallelism
- Data Dependency Problems
(1) Recall: Problems for Data Dependencies
Branch prediction and if-conversion help us eliminate most of the pipeline problems caused by hazards. But data dependencies can also prevent us from finishing 1 instruction per cycle. So now we are going to discuss what can we do about data dependencies and why we stop at only 1 instruction per cycle.
(2) Recall: Ideal Condition
Suppose we have infinite instructions that do not have any data dependency or control dependencies. When we run them simultaneously in a 5-stage pipeline, then all of them can be finished within 5 stages.
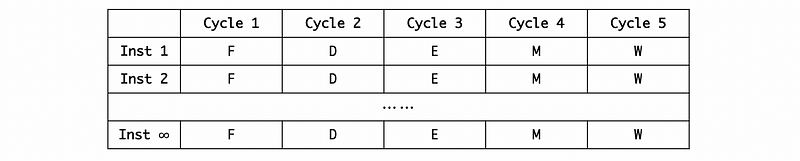
Thus, the CPI for this is CPI = 5/∞ = 0 and that’s really wonderful. However, in reality, because we have finite registers, that means we must reuse (read/write) some of them in order to execute all the instructions and this causes data dependencies. The problem will be caused if we read a value from the register before it is written by the last instruction. So the CPI can not be 0 in practice.
(3) Recall: Forwarding
We have seen the problem of reading a value from the register before it is written by the last instruction (RAW data dependency). Recall that the forwarding is defined as that we can directly use the result from ALU or some other stage instead of waiting for the writing stage. Suppose we have two instructions I1 and I2, then the forwarding would work if I1 reaches the executing stage (ALU stage) in the first place and then I2 reaches the executing stage in the next cycle.
Let’s now imagine that if I1 and I2 works simultaneously on a pipeline. If they execute at the same time, the forwarding no longer works! In order to make this work, we have to stall the I2 for 1 cycle so that the forwarding works for I2 because it will be executed after I1 is executed.
Suppose we run five instructions simultaneously in a 5-stage pipeline, and the instruction I2 has to be stalled for 1 cycle because of the forwarding. Regardless of the initial filling problem of this pipeline, the overall CPI of these 5 instructions is CPI = 2/5 = 0.4.
So even the ideal processor that can execute any number of instructions per cycle (like infinite), it still has to obey the RAW dependencies.
(4) Forwarding: An Example
Suppose we have 5 instruction I1 to I5.
If I2 is RAW dep. to I1, I4 is RAW dep. to I3, and I5 is RAW dep. to I4. Regardless of the initial filling problem of this pipeline, the overall CPI is supposed to be CPI = 3/5 = 0.6.
If I2 is RAW dep. to I1, I3 is RAW dep. to I2, I4 is RAW dep. to I3, and I5 is RAW dep. to I4. Regardless of the initial filling problem of this pipeline, the overall CPI is supposed to be CPI = 5/5 = 1.
(5) WAW Dependencies Problems
Even though the WAW data dependency doesn’t seem to be as serious as the RAW dependency, it can be a problem especially when two writing instructions executing simultaneously.
Let’s imagine a situation of 5 instructions. Suppose both I2 and I5 is going to write the register R4 and I2 has a RAW dependency to I1. Then I2 should be stalled by 1 cycle because it needs to wait for the result of I1 by forwarding. Because all these instructions are running simultaneously at the beginning, then I5 will write R4 first and then the value of R4 will be replaced by the result of I2 in the next cycle. However, this is not the right order because we want to keep the result of I5 in R4.
In order to maintain the correct order of the I2 and I5, two stalls have to be inserted before the writing stage for I5. Then the R4 will be firstly written by I2 and then be written by I5.
(6) True Dependencies Vs. False Dependencies
We have talked about the true dependencies (RAW) and the false (name) dependencies (WAW or WAR). The true dependencies are called so because we actually have to obey them in order to compute the true values. In contrast, the false (name) dependencies are called so because there’s actually nothing fundamental about them. They are dependencies just because we are using the same register for two different results. If we can use another register to write a value, then there will be no dependency.
(7) Removing False Dependencies #1: Duplicating Register Values
One of the methods that can be used to remove the false dependencies is to duplicate the register values. The basic idea of duplication is to keep multiple versions of a register and find the latest version if an instruction reads from this register. The latest version means the first instruction that is writing to this register before our reading instruction.
Even though all the things will be correct for the false dependencies, it requires us to create multiple versions of each register that we wrote, and this can be really complicated.
(8) Removing False Dependencies #2: Register Renaming
The register renaming is another scheme that can provide relief from false dependencies but in a way that is more manageable compared with duplications. Register renaming separates the concept of registers to architecture registers and physical registers,
- Architecture registers: the registers that the programmers and the compilers use
- Physical registers: the physical registers that we actually put the value in
As the processor reads the instructions and figures out which registers (architecture register) they are using, it also does the register renaming, and this means that it rewrites the program to the physical registers. To implement this renaming feature, it uses a table called register allocate table (aka. RAT).
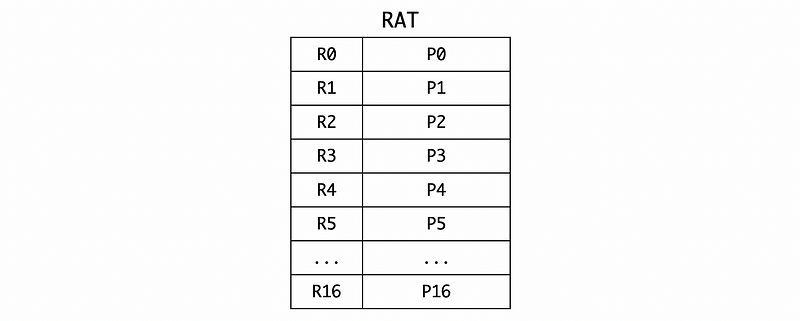
The RAT is a table that shows which physical register has value for which architecture register. So for each of the architecture registers, there will be a corresponding entry in this table and it will say what is the current location in the physical registers where the value for that architecture register can be found.
So why it works? Let’s see an example here. Suppose we have the following code,
I1: ADD R1, R2, R3
I2: SUB R4, R1, R5
I3: XOR R6, R7, R8
I4: MUL R5, R8, R9
I5: ADD R4, R8, R9
And we also have a RAT on which P1, P2 … means the physical registers we have. In the starting state, architecture registers R1 to R16 (say we have 16 registers) are mapped to P1 to P16 as follows,
The renaming means that the processor has to rewrite the origin assembly program so that they will be using the physical registers. Because we have more than 16 physical registers, we can allocate more physical registers to the same architecture register. Thus, there will not be any register reusing problems for false dependencies. The code should be rewritten to,
I1: ADD P17, P2, P3
I2: SUB P18, P17, P5
I3: XOR R19, P7, P8
I4: MUL R20, P8, P9
I5: ADD R21, P8, P9
So the final RAT should be,

You should be able to find out that all the false dependencies no longer exist in this program. However, all the true dependencies are maintained even after the renaming.
For our origin program, if we run these 5 instructions simultaneously, I2 is RAW dep. to I1, I4 is WAR dep. to I2, I5 is WAW dep. to I2. Thus, I2 should be one cycle after I1, I4 should be one cycle after I2, and I5 should be one cycle after I2. Thus, in total there will be 3 cycles and the CPI is CPI = 3/5 = 0.6 cycle/inst.
For the program after renaming, if we run these 5 instructions simultaneously, although I2 is still RAW dep. to I1, there will be no more false dependencies so that I1, I3, I4, I5 can be executed at the same time. Thus, in total there will be 2 cycles and the CPI is CPI = 2/5 = 0.4 cycle/inst.
2. Instruction Level Parallelism (ILP)
(1) The Definition of Instruction Level Parallelism
The instruction-level parallelism (ILP) can be actually defined as the instruction per cycle (IPC) for an ideal processor. This ideal processor must have two properties,
- the processor does the entire instruction (FDEMW) in 1 cycle
- the processor can do any number of instructions in the same cycle, but it still has to obey the true dependencies
So the conclusion is that the ILP is a property of the program and we can calculate with the assumption of an ideal processor. The processor, however, doesn't matter for ILP in any cases.
(2) Steps for Calculating the ILP
Step 1. Register renaming: rename all the registers
Step 2. Execute: In the first cycle, we have instructions that don’t depend on anything. In the second cycle, we have the instructions that depend only on the results from the first cycle, and so on. And finally, we can figure out how many cycles we need for this program.
Step 3. Calculate: thus the ILP can be calculated by ILP = IPC = # of instructions / # of cycles
In practice, we can save our time of calculation by counting only the true dependencies of the original program so that we don’t have to get the program after renaming while calculating.
(3) ILP: An Example
Suppose we have the following program after renaming,
ADD P10, P2, P3
XOR P6, P7, P8
MUL P5, P8, P9
ADD P4, P8, P9
SUB P11, P10, P5
then we have the following true dependencies of I5 depend on both I1 and I3,

So we can figure out that we need 2 cycles for this program and the ILP should be ILP = 5/2 = 2.5.
(4) ILP with Structural Dependencies
The structural dependencies occur when we don’t have enough hardware to do things in the same cycle. However, for the ILP, we are assuming that we have ideal hardware that can do any number of instructions in the same cycle. So the answer is that there will be NO structural dependencies for the ILP. So any instructions that could possibly be executed in the same cycle will be executed in the same cycle.
(4) ILP with Control Dependencies
For the control dependencies, we assume we have perfect same-cycle branch prediction meaning that the branches are successfully predicted in the same cycle when we fetch them. Thus, we are supposed to see all correct predictions after the branch in the same cycle.
Now let’s see an example. Suppose we have the following program,
ADD R1, R2, R3
MUL R1, R1, R1
BNE R5, R1, Label
ADD R5, R1, R2
...
Label:
MUL R5, R7, R8
We can know that the I2 is RAW dep. to I1, I3 is Raw dep to I2. Suppose the branch will work for us, then based on the perfect same-cycle branch prediction, the instruction MUL R5, R7, R8 will be executed in the first cycle. So,
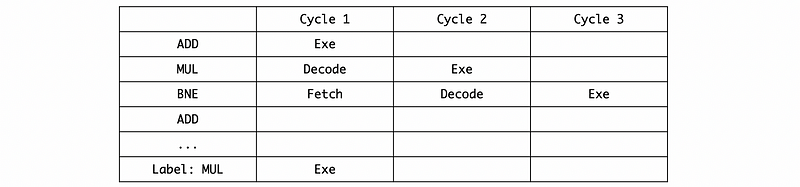
Thus, even the branch instructions are delayed, but its control dependencies on that branch will have no impact on what ILP will be because we are assuming perfect branch prediction where all the branches in the program are perfectly predicted in the same cycle.
(5) ILP and IPC for Real Processors
The ILP is the IPC for an ideal processor that has perfect branch predictions and only true data dependencies. In fact, because there are no ideal processors, the IPC of a program on a real processor is not equal to the ILP of this program.
Suppose we are given three processors, processor A, processor B, and processor C.
Processor A is,
- an infinite-issue processor
- with an out-of-order superscalar (means that it doesn't need to execute instructions exactly in the program order)
- with 1 ALU for
MULand 2 ALUs forADD/SUB/XOR
Processor B is,
- a 2-issue processor
- with an out-of-order superscalar (means that it doesn’t need to execute instructions exactly in the program order)
- with 1 ALU for
MULand 2 ALUs forADD/SUB/XOR
Processor C is,
- a 2-issue processor
- with an out-of-order superscalar (means that it doesn’t need to execute instructions exactly in the program order)
- with 1 ALU for
MULand 1 ALUs forADD/SUB/XOR
Processor D is,
- a 2-issue processor
- with an in-order superscalar (means that it needs to execute instructions exactly in the program order)
- with 1 ALU for
MULand 1 ALUs forADD/SUB/XOR
Also, suppose we are given the following program (which has only 1 true dependency of I2 and I1),
ADD R1, R2, R3
SUB R4, R1, R5
XOR R6, R7, R8
MUL R5, R8, R9
ADD R4, R8, R9
For processor A, there should be 2 cycles, so the IPC = 5/2 = 2.5 ,
------------------ C1 ------ C2 ------ C3 ------ C4 ------ C5
ADD R1, R2, R3 **
SUB R4, R1, R5 **
XOR R6, R7, R8 **
MUL R5, R8, R9 **
ADD R4, R8, R9 **
For processor B, there should be 3 cycles, so the IPC = 5/3 = 1.67 ,
------------------ C1 ------ C2 ------ C3 ------ C4 ------ C5
ADD R1, R2, R3 **
SUB R4, R1, R5 **
XOR R6, R7, R8 **
MUL R5, R8, R9 **
ADD R4, R8, R9 **
For processor C, there should be 4 cycles, so the IPC = 5/4 = 1.25 ,
------------------ C1 ------ C2 ------ C3 ------ C4 ------ C5
ADD R1, R2, R3 **
SUB R4, R1, R5 **
XOR R6, R7, R8 **
MUL R5, R8, R9 **
ADD R4, R8, R9 **
For processor D, there should be 4 cycles, so the IPC = 5/4 = 1.25 ,
------------------ C1 ------ C2 ------ C3 ------ C4 ------ C5
ADD R1, R2, R3 **
SUB R4, R1, R5 **
XOR R6, R7, R8 **
MUL R5, R8, R9 **
ADD R4, R8, R9 **
(6) Properties of ILP and IPC
- Property #1: ILP ≥ IPC
- Property #2: given a narrow issue in-order processor, the IPC is mostly limited by the narrow issue
- Property #3: given a wide issue in-order processor, the IPC is mostly limited by the in-order superscalar
If we want to get a higher IPC, we have to use a wide-issue out-of-order processor. This processor requires us to have a lot more than 1 instructions per cycle (wide-issue), eliminate all the false dependencies (probably by register renaming), and reorder the instructions (out-of-order).