High-Performance Computer Architecture 15 | Exceptions for Tomasulo’s Algorithm and Reorder…
High-Performance Computer Architecture 15 | Exceptions for Tomasulo’s Algorithm and Reorder Buffer (ROB)
- Exceptions for Tomasulo’s Algorithm
(1) Review
We have known that the out-of-order execution (aka. OOO Execution) is implemented by Tomasulo’s algorithm from the last section and the overall performance can be improved a lot by such an algorithm.
- the control dependencies by branch prediction
- the WAR or WAW data dependencies (false data dependencies) by register renaming
- the RAW data dependencies (true data dependencies) by out-of-order execution => Tomasulo’s algorithm
- the structural dependencies by invest in a processor that has a wider issue
However, things can be more complicated in reality because sometimes we must maintain the order of the execution. If we don’t follow the execution in order, the program will be messed up. We will talk about this exception in this section.
(2) Another Timing Example
Now let’s do another example about timing. Suppose we have the following code,
DIV F10, F0, F6
L.D F2, 45(R3)
MUL F0, F2, F4
SUB F8, F2, F6
Let’s now start our calculations for timing (cycles) of issuing, dispatching, and writing results. Suppose we have an infinite instruction queue, so the issuing cycles will be,
Inst ISSUE DISPATCH WRITE_RESULTS
DIV F10, F0, F6 1
L.D F2, 45(R3) 2
MUL F0, F2, F4 3
SUB F8, F2, F6 4
Let’s say that a DIV is going to take 40 cycles for execution, then,
Inst ISSUE DISPATCH WRITE_RESULTS
DIV F10, F0, F6 1 2 42
L.D F2, 45(R3) 2
MUL F0, F2, F4 3
SUB F8, F2, F6 4
Suppose we have 1 Load ALU, 2 MUL/DIV ALUs, and 1 ADD/SUB ALU. In addition, it takes 10 cycles for a load execution to finish and 5 cycles for MUL, and 1 cycle for ADD/SUB. Then
Inst ISSUE DISPATCH WRITE_RESULTS
DIV F10, F0, F6 1 2 42
L.D F2, 45(R3) 2 2 12
MUL F0, F2, F4 3 13 18
SUB F8, F2, F6 4 13 14
(3) Exception of Out-Of-Order Execution: A Divided-by-0 Example
Now, we have already got the timing for the given program above. And let’s say that the first instruction get a 0 value of F6, so the value in F0 will be divided by 0 in cycle 40 (this is a value that we assume for this case) and this will result in an error.
If a value is divided by 0, what should happen in this processor is that the program counter (PC) of this instruction should be saved and we should jump to an exception handler (because we meet an error). If the exception handler comes back, we should be back to this instruction and continue executing.
However, what really happens is that we have already executed the instruction L.D , MUL , and SUB in cycle 40. If we now go to the handler and then come back, the DIV instruction will use the F0 value produced by the MUL instruction. As a result, the DIV instruction can never get a correct result even if we fix the F6 with a relatively small value.
(4) Exception of Out-Of-Order Execution: A Page Fault Example
The out-of-order exception can also happen when we have a page fault for a load instruction. If we page back from the disk and then go back to execute the load, some instructions that after the load instruction might have executed and there is no way to proceed.
(5) Exception of Out-Of-Order Execution: Branch Mispredictions
Suppose we have the following program,
DIV R1, R3, R4
BEQ R1, R2, Label
ADD R3, R4, R5
Label:
...
we have a DIV which needs 40 cycles for execution and once we get the result of R1, we can resolve the branch instruction BEQ. Meanwhile, we have fetched the instruction ADD although the branch should have been taken. The ADD instruction can finish in 1 cycle and then R3 will be written.
However, when about 40 cycles later, we finally realize that we have mispredicted the branch. The branch should be taken and we should behave as we have never executed the ADD instruction. But that becomes impossible because R3 by that time has already been updated.
(6) Exception of Out-Of-Order Execution: Phantom Exceptions
Suppose we have the following program
DIV R1, R3, R4
BEQ R1, R2, Label
ADD R3, R4, R5
DIV ...
Label:
...
with a DIV instruction after the ADD instruction. If we mispredicted the taken branch we are going to execute the DIV instruction before we know that the branch is mispredicted. If the second DIV generates an exception and then this exception will be triggered even though this DIV is never supposed to be executed. This is called a phantom exception.
So we have to somehow care about not having exceptions until we are sure that they should happen.
(7) Correct Out-of-Order Execution
In order to keep Tomasulo’s algorithm, we should execute out-of-order and we should also broadcast out-of-order. But to deal with the exceptions, we have to deposit values to registers in order. This is needed because if we write values to the registers out-of-order when some earlier instructions shouldn’t have been done, we will get some exceptions.
In order to implement this in-order feature for writing to the registers, we have to use a structure called reorder buffer (ROB).
2. Reorder Buffer
(1) The Definition of Reorder Buffer (ROB)
A reorder buffer is used in Tomasulo’s algorithm for avoiding the exceptions of the out-of-order instruction execution. It allows the instructions to be committed in-order. The ROB remembers the program order even after issuing and it keeps the results of the instructions until they are safe to write to the registers.
(2) The Implement of Reorder Buffer
Now, let’s see how does the ROB looks like. The ROB is a table of entries and in each entry, we keep at least 3 fields. For example, suppose we have a ROB that can hold up to 8 instructions
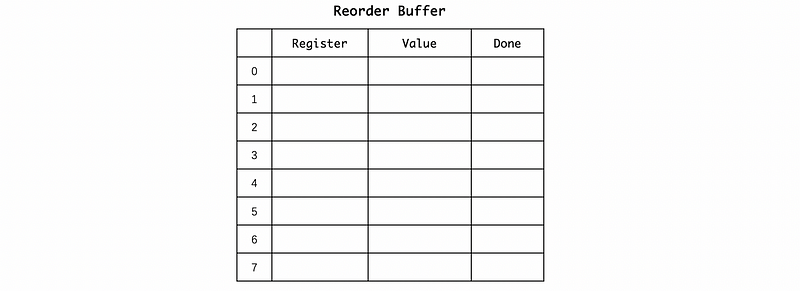
We need a bit for the Done, which is a signal that tells us whether has a valid value or not. Because in the end, we have to write the value to a specific register, thus we should know what register are we going to write to. This destination information of writing is stored in the register field.
We also need two pointers in order to keep the program instructions in the program order. The issue pointer tells us when we issue the next instruction, where does it go. Another pointer (called commit pointer) tells us when we have the in-order instructions complete, which value we can assign to the register.
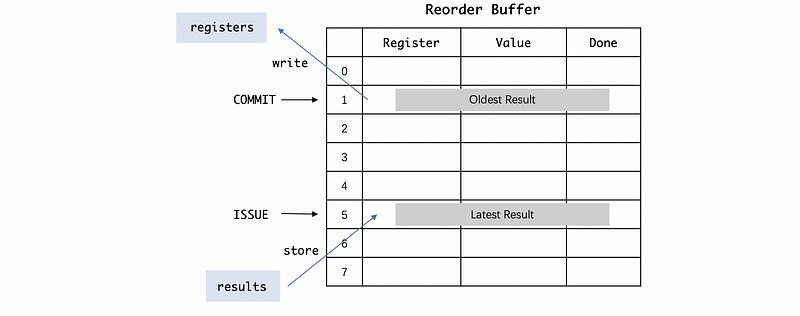
(3) ROB for Tomasulo’s Algorithm
Now, let’s have a look at what really happens for Tomasulo’s algorithm. Suppose we have the instruction ADD R1, R2, R3 waiting in the instruction queue at the beginning,
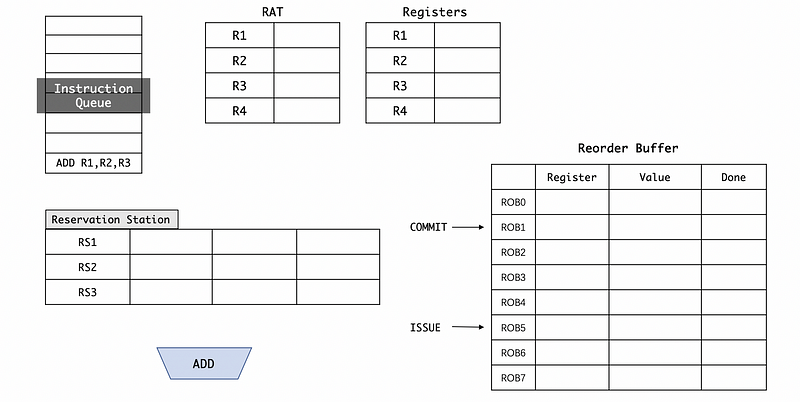
When we issue the ADD R1, R2, R3 instruction, it will not only be issued to the reservation station (out-of-order) but also it will be assigned to the ROB (in-order). After it is assigned to the next instruction in the ROB, remember that we have to move the issue pointer. Note that because now we haven’t got the result of this instruction yet, we have to set the Done field to 0.
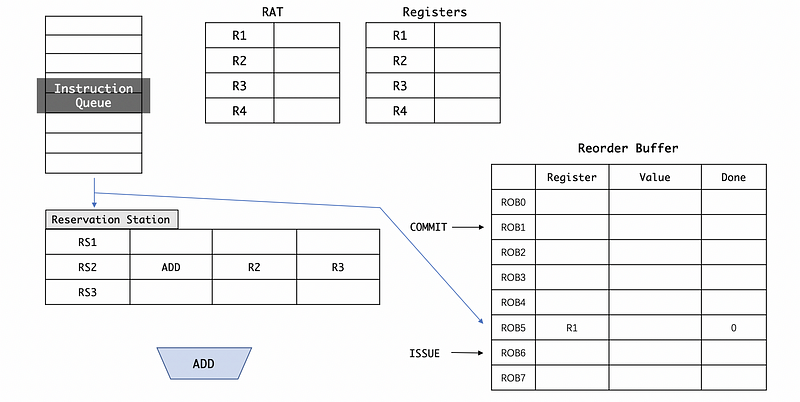
When we rename the registers, we are not going to map R1 to RS2 in RAT. Instead, we will map R1 to ROB5 so that the final assignments to the registers are in-order.
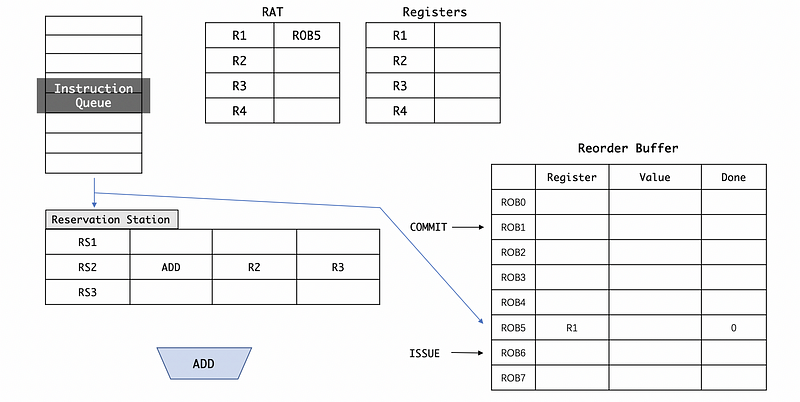
Now the RS2 may need to wait for some operands to continue execution. When it is dispatched to the ALU, the RS2 will be freed and we will generate a result val from the ALU. Because now the computation has down, we can change the Done field to 1,
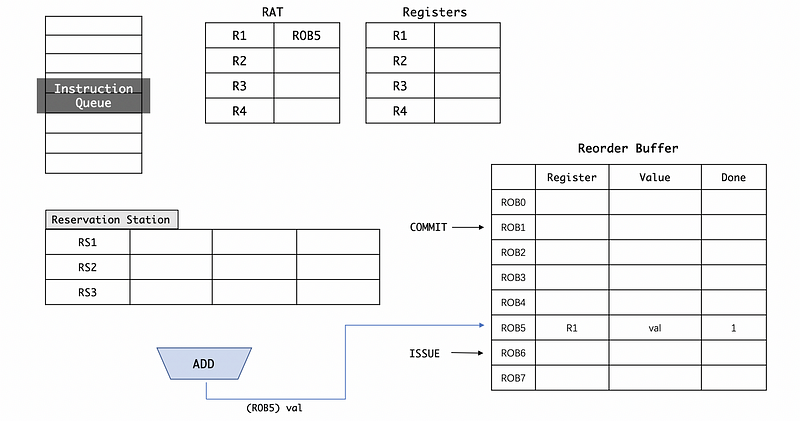
After we commit all the instruction results before the ROB5 , the commit pointer will point to the ROB5 and check the Done field (it need to see Done == 1 for committing a result),
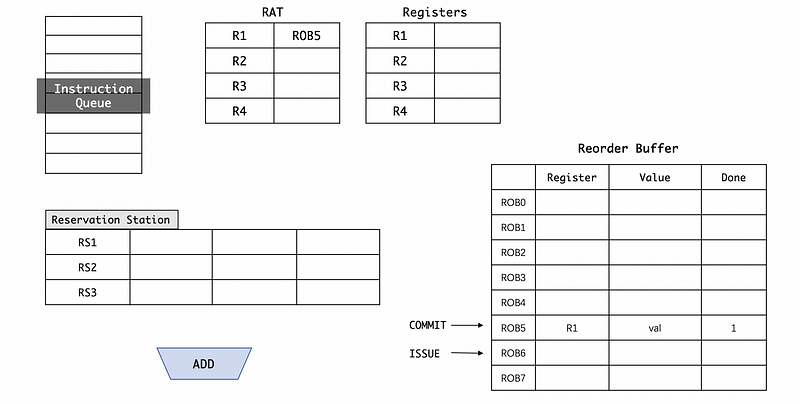
Then finally, this result will be committed to RAT and the registers,
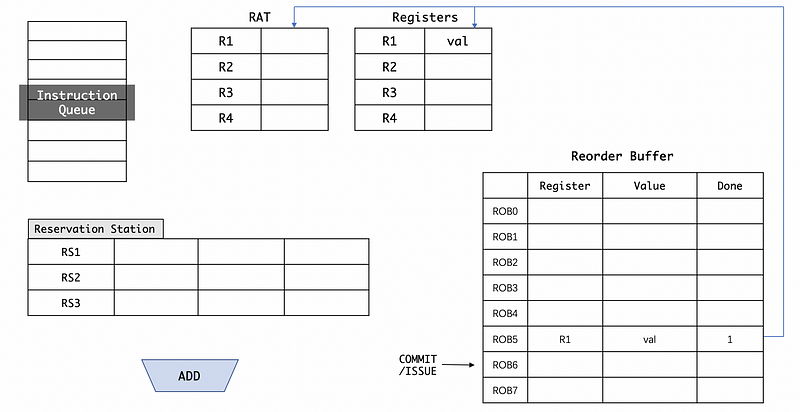
(4) Branch Misprediction Recovery by ROB
We have said that we need ROB in order to have precise exceptions and also to be easily recover from branch mispredictions. Let’s now see how it works. Suppose we have the following program,
L.D R1, 0(R1)
BNE R1, R2, Label
ADD R2, R1, R1
MUL R3, R3, R4
DIV R2, R3, R3
Label:
And the branch will be taken in the end. So if we make the misprediction, the three instructions ADD, MUL, and DIV will be fetched. After the misprediction is done, we will have the following situation,
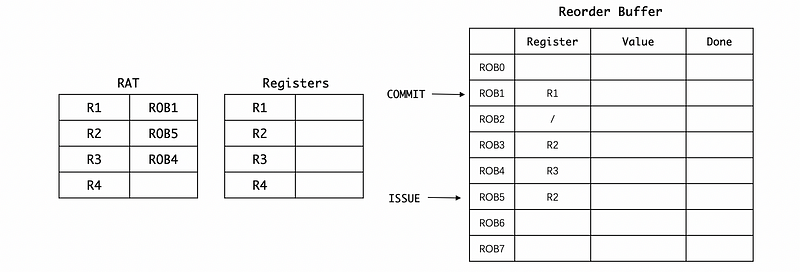
Let’s say that we have to run L.D for a long time (maybe because of the cold cache), then because BNE and ADD rely on the result of R1 , they can not be dispatched. However, because MUL and DIV don’t rely on anything, they will be dispatched and the register will be updated by the new result of R2 and R3 because of the misprediction.

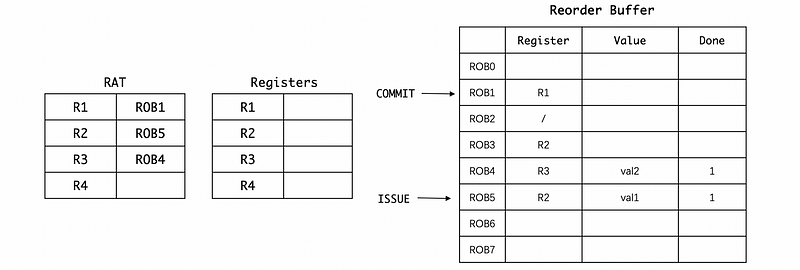
However, if we have the ROB, the RAT and RF will not be modified if we execute the result of these MUL and DIV instructions,
After a while when L.D instruction finishes, we can finally get the value of R1. Let’s say the loaded value from the memory is 700. Then the ROB will have this new value,
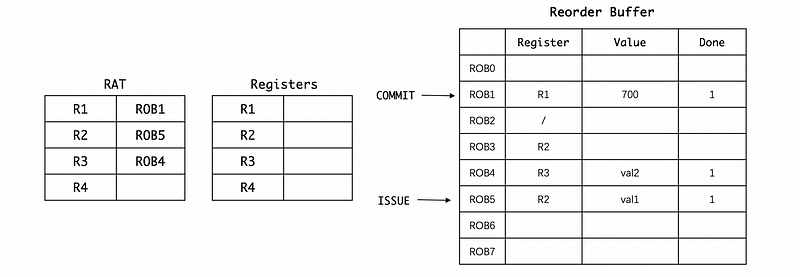
Then we are going to commit this instruction because it is marked as done. So,
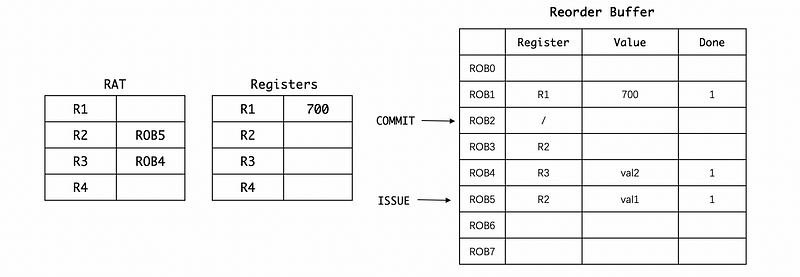
Because the BNE branch instruction is much slower than ADD , so the ROB2 will get the result value val3 before we know whether can branch or not.
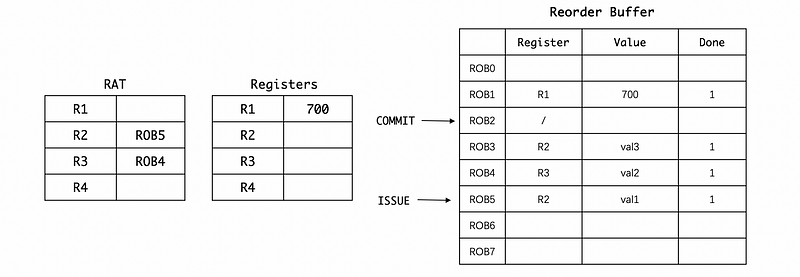
Eventually, we get to resolve this branch BNE and then figure out it’s been mispredicted. So now the branch will be marked as done, but we don’t have to assign a value. But what we do is to annotate to ROB2 so when it is committed, we can know there is a misprediction problem.
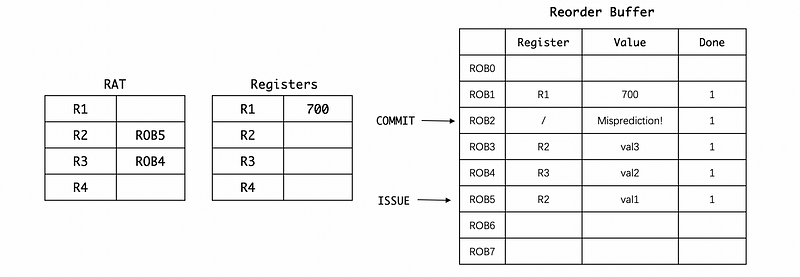
After committing the ROB2, we now know that we should branch to the Label , but how can we get rid of the mispredictions?
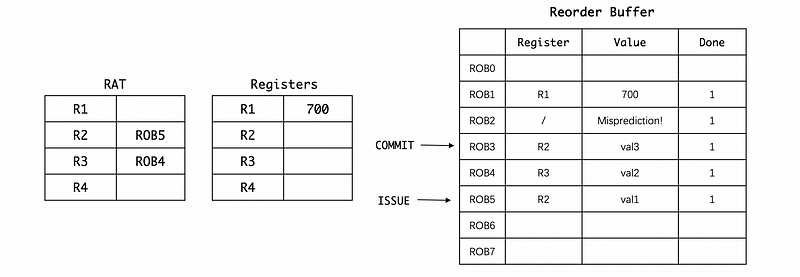
In order to recover from the misprediction, we have to do the following two steps. The first step is to move back the issue pointer. This step will get rid of all the results after the BNE instruction,
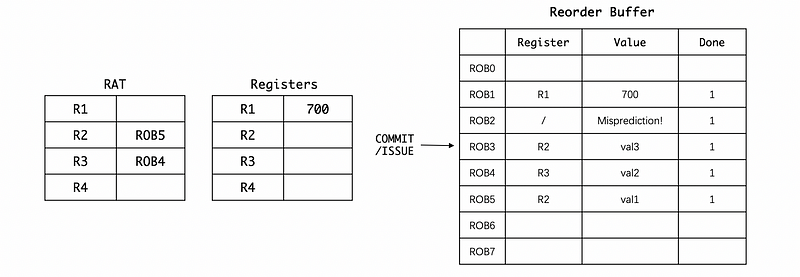
The second step is that we can then clear the values in the RAT because all the correct values are now already stored in the register file. So we don’t need those mappings,
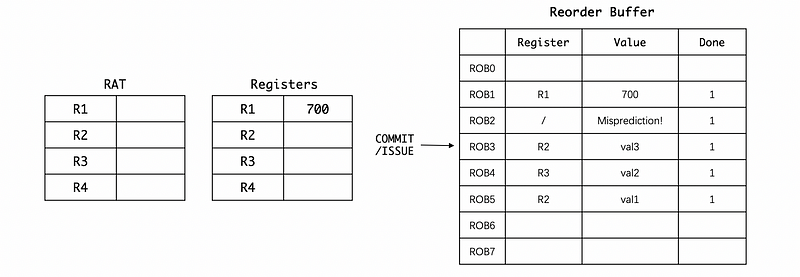
Since then, we have already recovered from the misprediction. And after this, we can fetch from the right instruction.
(5) Branch Misprediction Recovery Summary
- Making the RAT mapping to all the corresponding registers so we can erase all of the renamings
- Emptying whatever in the ROB after we commit the offending branch instruction
- Emptying whatever in the RS and ALU
(6) RAT Updates on Commit
Suppose we have already had the following situation, and then we would like to commit the results in ROB. So what will happen?
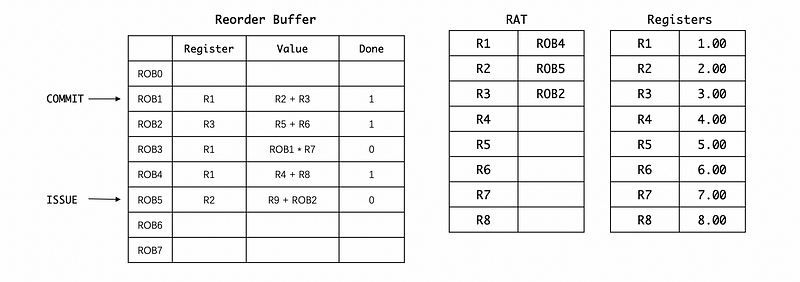
First, we will commit ROB1. Each time we commit an instruction, we will deposit its result in the registers no matter what the RAT really says about it. So we will add R2 and R3 values directly from the register file even though the renaming in the RAT says that the value in the register file is not the latest value for R1. However, we are then going to check whether we have the latest rename (in this case, ROB4) and if we haven’t got the latest value yet, we will not change the RAT. Remember we have to move the commit pointer after we commit the ROB1 instruction. However, because the RS gets the value of ROB1 now, it will then dispatch the ROB1 * R7 instruction and then broadcast the result,
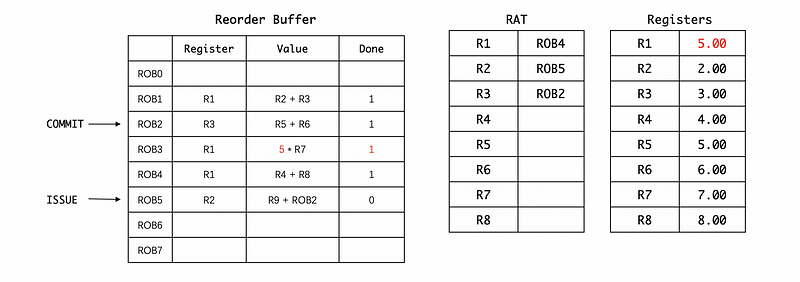
Second, we will commit ROB2. Again, we will add the value of R5 and R6 directly from the RF. Because we now commit the result of ROB2, he R9 + ROB2 instruction will be dispatched and its result will then be broadcasted. Meanwhile, the ROB2 will also be eliminated from the RAT because we get the latest value of the R3 register.
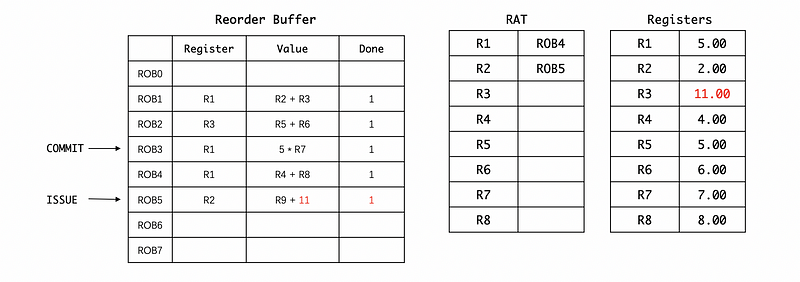
Third, the result of 5 * R7 will be committed and then stored in R1. Because ROB3 is once again, not the latest value for R1, the RAT will not change,
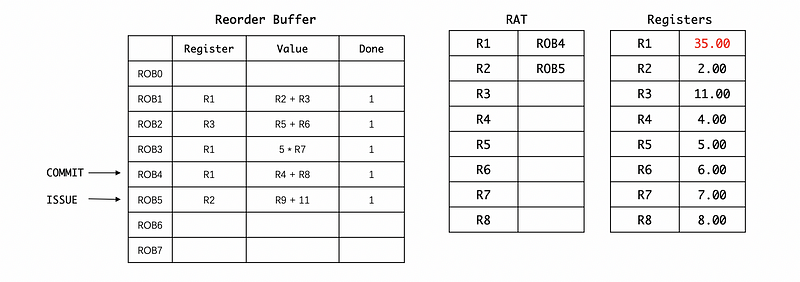
Fourth, the result of R4 + R8 will be committed directly by adding the results in RF. Because now the ROB4 is the latest value for R1, we can now eliminate the corresponding value in RAT.
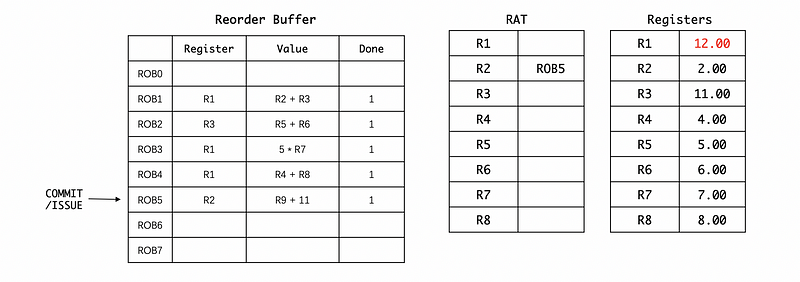
Finally, let’s commit to the last one. We will finally write the result to R2 and then (suppose in this case the register value of R9 is 9).
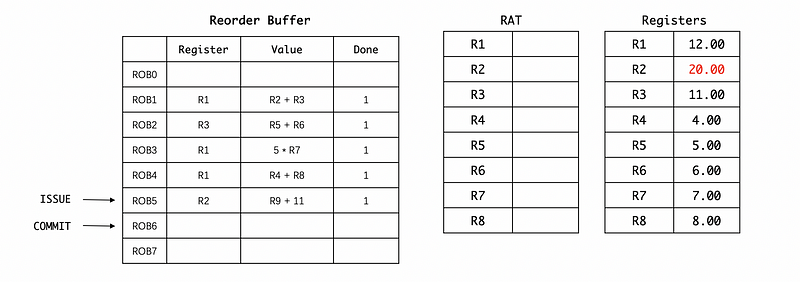
In the end, we can find out that the RAT and the ROB are actually empty, and the register file has all the values of the registers up to date.
3. A Long ROB Example
(0) Basic Setups
Suppose we have the following program,
DIV R2,R3,R4
MUL R1,R5,R8
ADD R3,R7,R8
MUL R1,R1,R3
SUB R4,R1,R5
ADD R1,R4,R2
And the initial state of the hardware is,
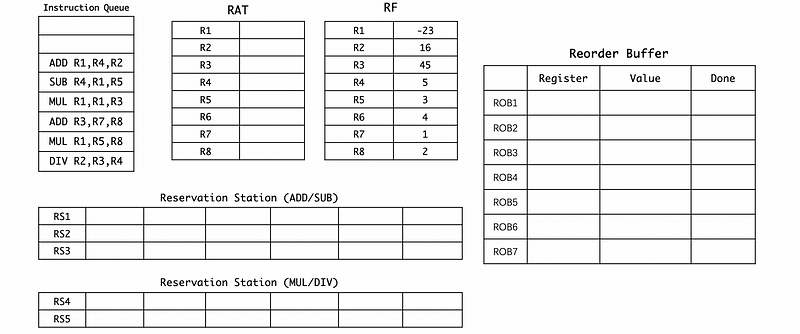
The cycles we need for each type of executions are,
ADD: 1 cycle
MUL: 10 cycles
DIV: 40 cycles
Also, we assume that we can have infinite ALUs for MUL/DIV/ADD/SUB.
(1) Cycle 1
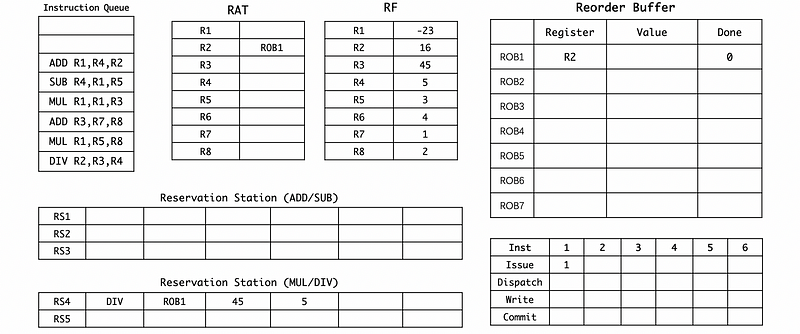
(2) Cycle 2
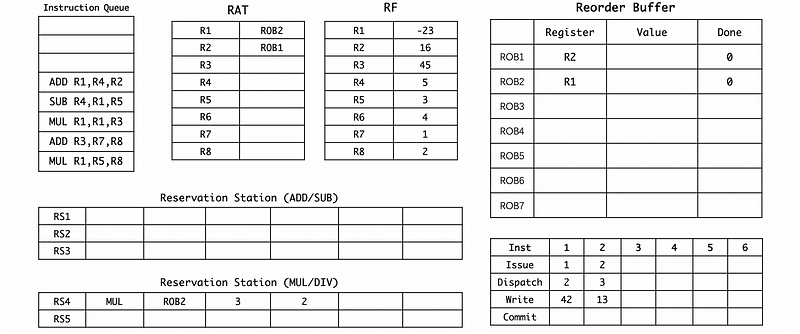
(3) Cycle 3
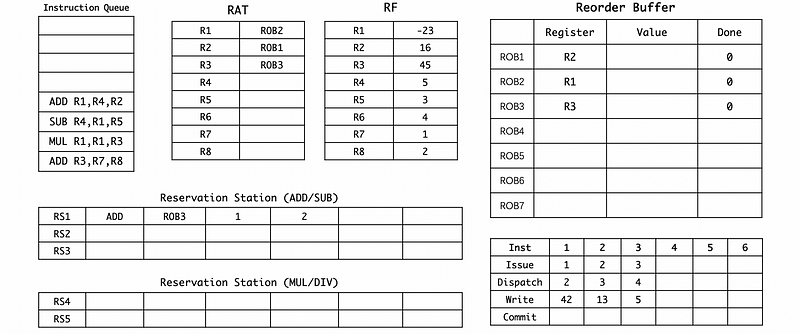
(4) Cycle 4
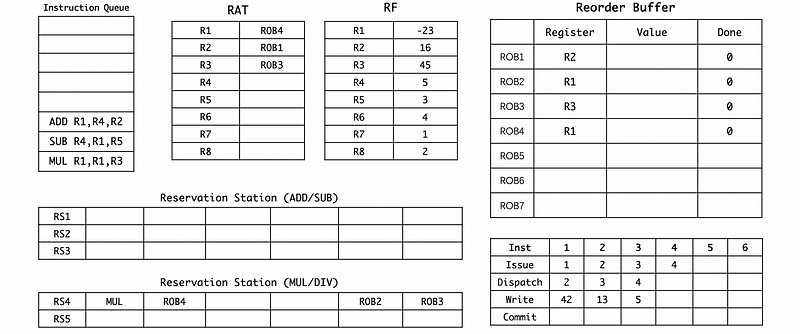
(5) Cycle 5
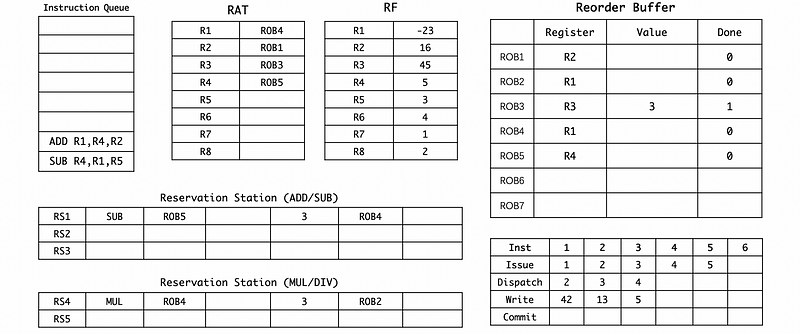
(6) Cycle 6
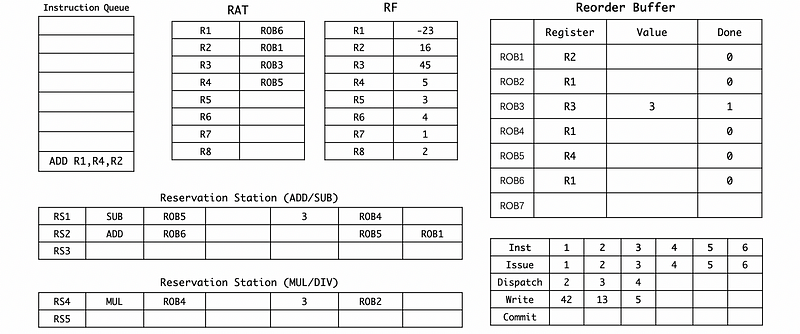
(7) Cycle 13
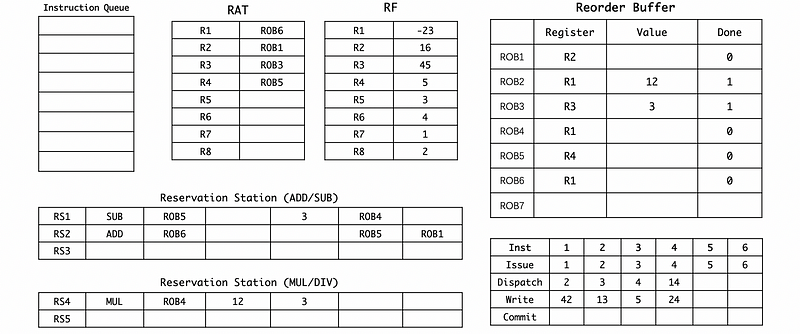
(8) Cycle 14
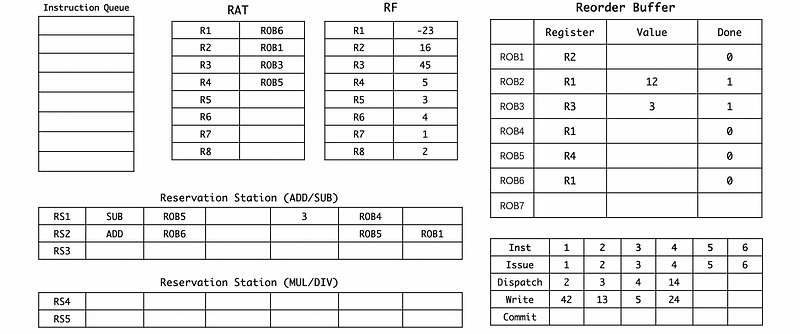
(9) Cycle 24
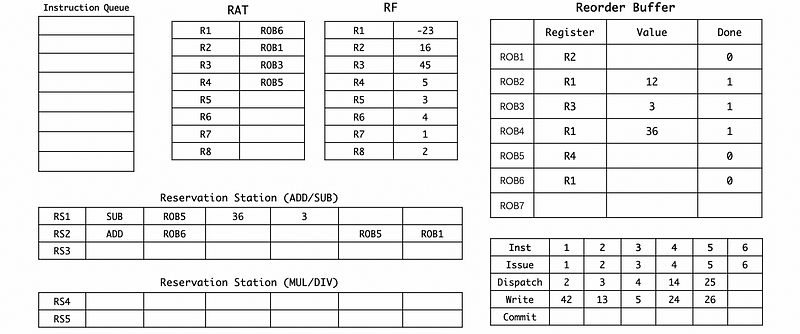
(10) Cycle 25
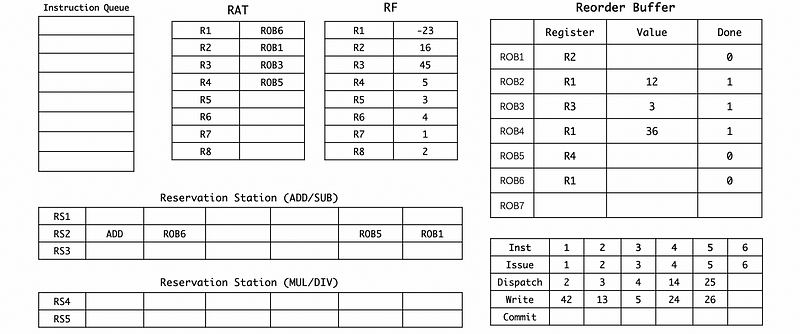
(11) Cycle 26
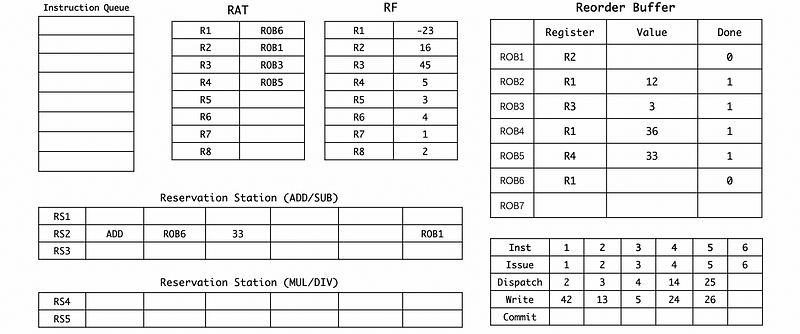
(12) Cycle 42
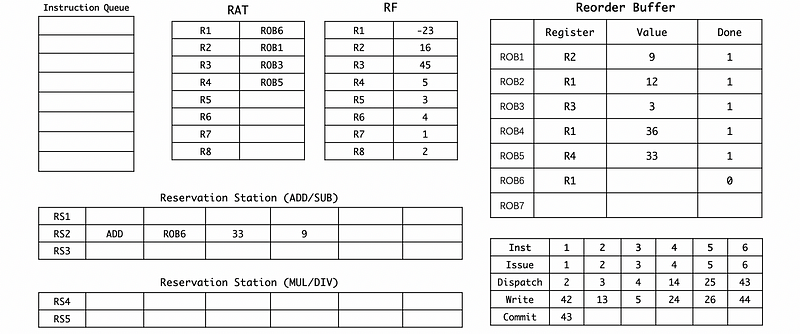
(13) Cycle 43
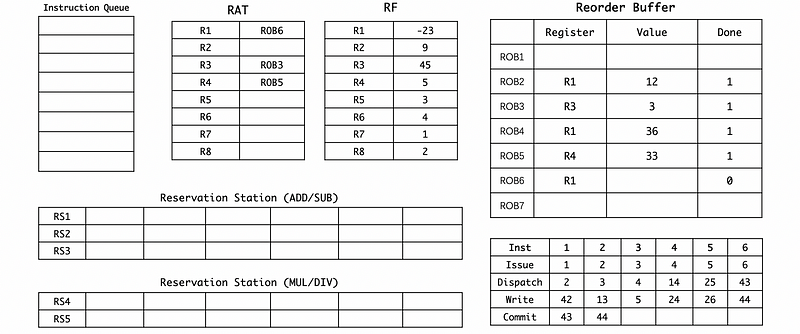
(14) Cycle 44
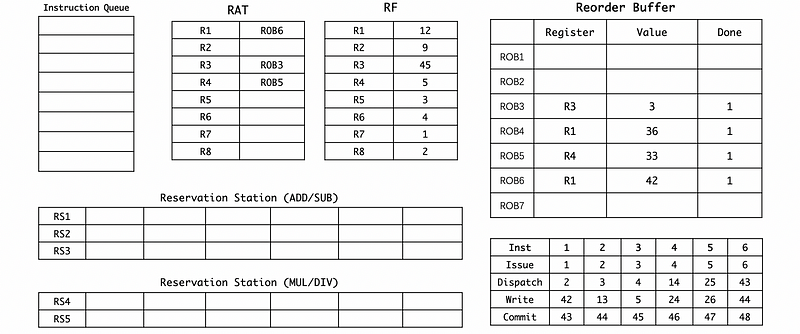
(15) Cycle 45
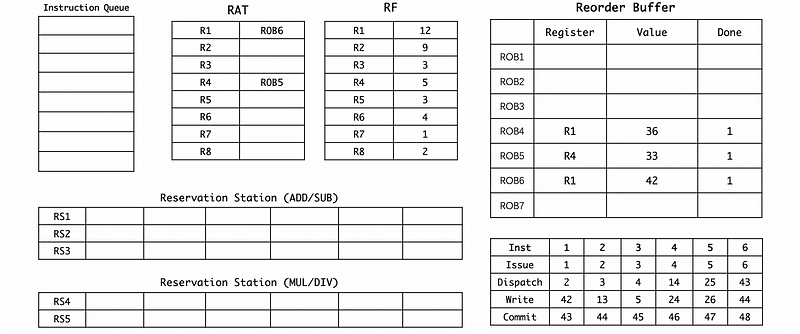
(16) Cycle 46
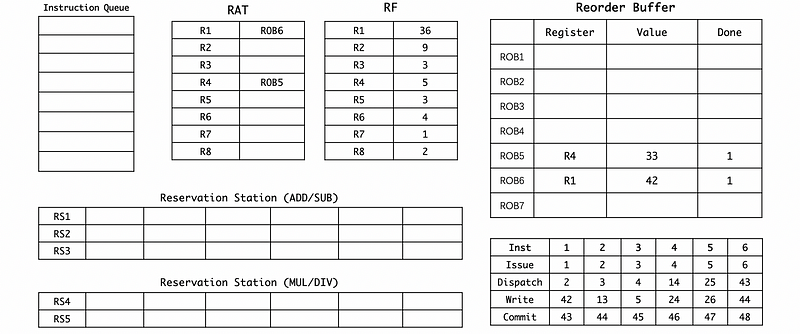
(17) Cycle 47
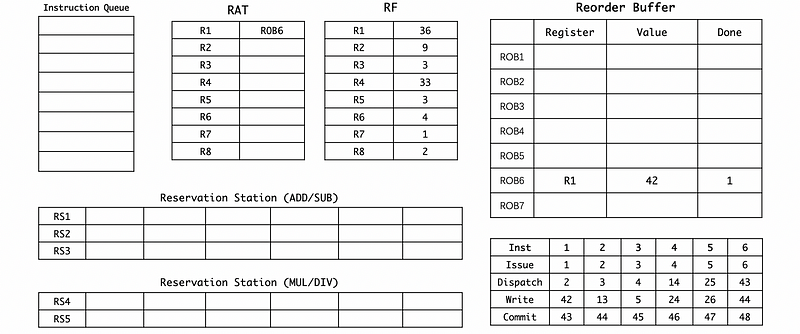
(18) Cycle 48
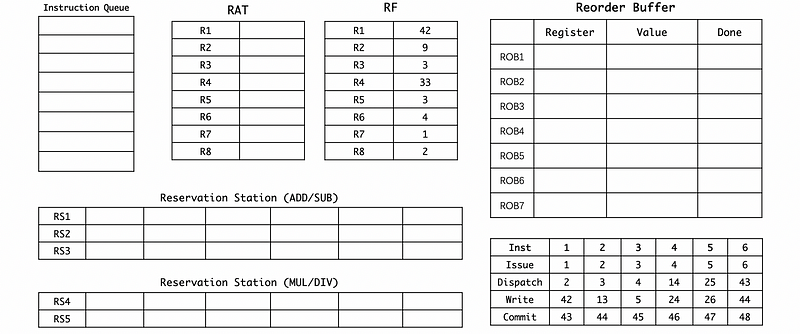
4. A Useful Tool
If you want to simulate the ROB in a more simple way, check out this simulator for ROB and Tomasulo’s algorithm.