High-Performance Computer Architecture 16 | Unified Reservation Stations, Weakest Link…
High-Performance Computer Architecture 16 | Unified Reservation Stations, Weakest Link, Terminology Confusion, and In-order Processor
- Unified Reservation Stations
Now that you have seen how the ROB based processor works when we have a reservation station for separate ALUs. For example,

We have seen that in at least one of our examples that we can run these reservation stations while we still have plenty of these left. However, we still couldn’t issue instructions because we don’t have the reservation station left for the type of instruction we want. Because we have talked that the issues must happen in order, we have to wait until the reservation we need to become available.
Note that these reservation stations are exactly the same and actually we want to use some idle reservation stations for some other ALUs because an idle reservation can be expensive for us. So in practice, we will have a unified reservation station where all of the reservation stations are in one big array.
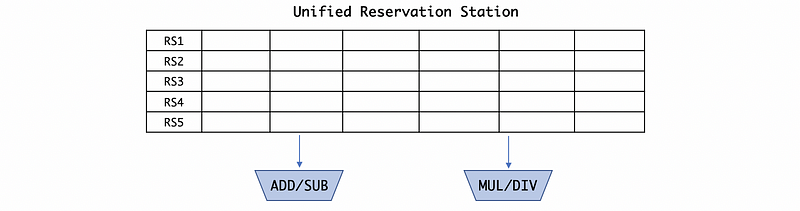
Now, because we have to supervise more reservation stations and we also have to choose which ALU we are going to dispatch. So the dispatchings are becoming more complicated. However, to think about the expensive idle reservation station, this still sounds like a fair trade-off. So usually, processors will use some variants of the unified reservation station rather than the separate unified reservation stations.
2. Weakest Link Rule for Superscalar
We have seen our raw based processor, which is not a superscalar processor. A real superscalar processor requires the following features,
- it needs to fetch more than 1 instruction per cycle (i.e. we need 8 bytes for our fetch if we want to fetch two 4-byte instructions per cycle)
- it needs to decode more than 1 instruction per cycle (i.e. we need to have more than 1 decoder)
- it needs to issue more than 1 instruction per cycle (i.e. we can try to issue instructions as much as possible in a cycle)
- it needs to dispatch more than 1 instruction per cycle (i.e. we need more than 1 execution unit for each type of instructions)
- it needs to broadcast more than 1 result per cycle (i.e. this involves not only having 2 broadcast buses or 3 broadcast buses, but also each of the register stations has to compare with all of the values on these buses)
- it needs to commit more than 1 instruction per cycle (so the commit logic needs to be capable of committing more than 1 instruction per cycle)
For all of these requirements, what finally determines our general processor’s performance weakest link. Suppose all of them are very very large (like 500 instructions per cycle :)! ) and one of them is very small with only 1 instruction per cycle, then we will not be able to reach an overall performance of more than 1 instruction per cycle no matter how well the program matches this organization.
3. Terminology Confusion for OOO Execution
We have been calling the stage of execution as issue, dispatch, write results/broadcast, and commit. These terminologies came from Tomasulo’s algorithm and also introduced in the first paper talked about the ROB. So most academics will use the terminologies like that in most of the research papers. However, some companies will use the following terminologies,
allocate/dispatchforissueexecute/issuefordispatchcomplete/retire/graduateforcommit
Note there is a joke because some papers are written by the students, so they would be more likely to call the commit as graduate for good luck.
4. ROB Vs. Without ROB
Now, let’s discuss what we have changed to in-order execution with ROB.
For a system without ROB,
- In-order: fetch, decode, issue, commit
- Out-of-order: execute, write result/broadcast
For a system with ROB,
- In-order: fetch, decode, issue
- Out-of-order: execute, write result/broadcast, commit
So even if we have an OOO processor, we actually do a lot of things in order. However, if we have an in-order processor, we must do all the stages in order.