High-Performance Computer Architecture 29 | Introduction to Multi-Processing and Multi-Threading…
High-Performance Computer Architecture 29 | Introduction to Multi-Processing and Multi-Threading, UMA, NUMA, and SMT
- Introduction to Multi-Processing
(1) Flynn’s Taxonomy of Parallel Machines
We can distinguish different types of parallel machines according to how many instruction streams they have and how many data streams these instructions operate on.
- Single Instruction, Single Data (SISD): logically, this type of machine executes one instruction stream (single program counter), and each operation operates on one data stream. This is really a normal uniprocessor.
- Single Instruction, Multiple Data (SIMD): this type of machine executes one instruction stream, but there is more than one data stream they operate on. These are commonly so-called vector processors. Modern processors also have multimedia extension instruction such as MMX or SSE 1, 2, 3 and they are also an example of limited SIMD.
- Multiple Instruction, Single Data (MISD): this type is weird because we have multiple instruction streams means that there are several different programs executing at the same time, but they are all operating on the same stream of data. We don’t use this quite often but something like a stream processor
- Multiple Instruction, Multiple Data (MIMD): this one is also common with more than 1 instruction stream and more than 1 data stream. These would be the normal processor where each processor has its own program that is running with its own program counter, and each of them operates on the same data. These are always our normal multiprocessors.
(2) Reasons for Multiprocessors
There is one common confusion that could we just using the uniprocessor and improving its performance without using the multi-cores? The answer is that we can still do that. The reason why we have multi-cores is that there are actually some limits to the uniprocessor system.
One reason is that we can not improve the performance after we reach a threshold of width. Let’s suppose we have a 4-issue wide uniprocessor, which can execute up to 4 independent instructions parallelly. However, if we make this wider to 6 or 8 issues, although the performance will be improved, we will see diminishing returns because the dependent instructions will not be improved.
The other reason is that by Moore’s law, we have twice transistors in the same area every 18 months. To make the uniprocessor faster, we have to jack up the frequency and the voltage. Therefore, when we do this stuff, the power consumption grows up cubically and we may end up burning up the processor.
A better idea is to use a multicore system and approximately, it will have a performance similar to we have improved the unicore system. However, if we have only 1 program with only 1 thread, we can not benefit from the multiprocessors. So we need programs that are parallel in order to fully exploit the multiprocessor.
(3) Downsides for Parallel Programs
As we have talked about, if we want to benefit from the multiprocessor system, what we must have are parallel programs. However, because there are some downsides of the parallel programs,
- single-threaded codes are much easier to develop than parallel programs
- debugging parallel programs can be much more difficult
- performance scaling can be very hard to get. This means that we need a lot more work (always years of hard works) if we want to achieve a result of a higher utility of the multiprocess resources
(4) Centralized Shared Memory (UMA)
One type of multiprocessors is called the centralized shared memory. Let’s say we have 4 cores and their own caches are all connected to the same bus, so they can all access the same main memory and the same I/O devices. Different cores can share data by simply reading or writing to the main memory.
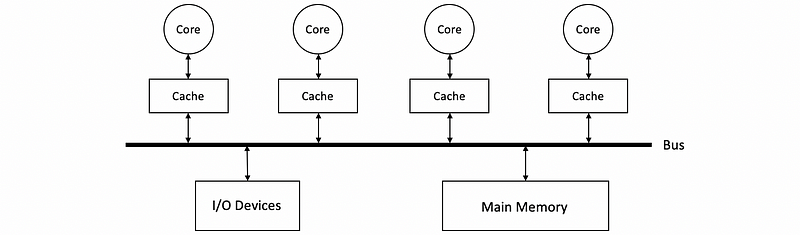
This kind of multiprocessor is really what today’s multi-processors look like and it is also called uniform memory access time (aka. UMA) because all the cores are connected to the main memory in the same way. Interestingly, you are able to find this term on Apple’s latest M1 chip. This type is also called symmetric multiprocessor (aka. SMP).
However, there are some problems related to the centralized shared memory,
- we have to keep a larger memory size: because more processes can be running at the same time and they are likely to contain different data. This also makes the memory access/read/write slow.
- we have to improve the memory bandwidth: because now we have multiprocessors, we can have more access to the main memory in a time. Therefore, we must maintain a wider memory bandwidth for a larger flow of accesses or these accesses will have to wait in a queue and the multiprocessors are now serialized. This prevents an additional core from benefiting our performance.
With these problems, the centralized shared memory has this problem so they can work only for smaller machines with 2, 4, 8, or 16 cores, and also our memory needs to be not too big and too slow.
(5) Distributed Shared Memory (NUMA)
The distributed shared memory (aka. non-uniform memory access time, or non-uniform memory access, or NUMA)is another type of multiprocessors, which means that instead of caring about the shared memory problem, we can have memories assigned to each core. It has the term “shared” but this type has no relation to real shared memory. So there is no memory that is shared by all the cores. Different cores will connect with each other using a network interface card (aka. NIC) that connects to a network.
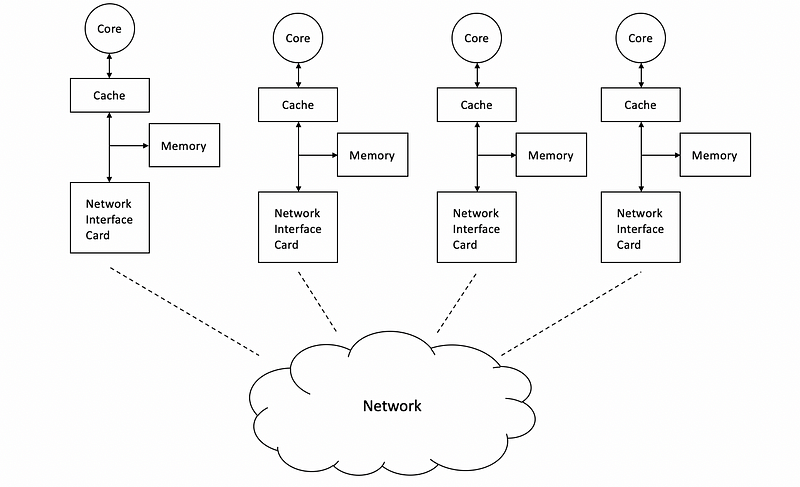
So now if two cores want to communicate with each other, they will act like independent machines that communicate through a network. One core needs to send the message to the network and another needs to properly receive the message from the network. This technique is actually called message passing. The only difference to the real network communication is that the NICs are much faster. For this reason, this type of multi-processor is also called a multi-computer or cluster computer.
(6) UMA Vs. NUMA
Now, let’s summarize the difference between message passing (NUMA) and the shared memory (UMA).
- Communication: for message passing, the programmer is responsible for figuring out who sends/receives data. While for shared memory, the OS will automatically figure everything out
- Data Distribution: for message passing, the memory is distributed. While for shared memory, the system is responsible for sending the data where it is needed
- Hardware Support: for message passing, the HW support is relatively simple because what we have to implement is just NICs. However, for shared memory, we need extensive hardware support that automatically figures out when to send the data, to whom, etc.
- Programming Correctness: getting correctness is relatively difficult in message passing and you can get all sorts of deadlock issues, wrong distributions, etc. But you don’t have to think about synchronization. For shared memory, although we also have to conduct synchronization, it is also much simpler than the message passing
- Program Performance: the performance is difficult to get for message passing, but is even more difficult to get for shared memory. We have to make a lot of efforts before the program performs well
2. Introduction to Multithreading
(1) Types of Shared Memory Hardware
We have different types of shared memory hardware, and these include,
- Multiple single cores to any memory address: UMA or NUMA
- A single core with multithreading: different threads will time sharing the same core. Different threads actually have the same physical memory.
- Hardware multithreading in one core: the hardware multithreading can be either a coarse-grain (means changing the threads every few cycles) or a fine-grain (means to change threads every cycle). We can also have simultaneous multithreading (aka. SMT, or Hyper-threading), which means that in any given cycle, we could be doing instructions that belong to different threads.
(2) The Performance of Multithreading
Now, let’s see why multithreading can improve performance. Suppose we have a 4-issue wide single-threading unicore processor and the green, red, and blue blocks mean instructions from different processes. Then suppose we have the following program with three processes and they are scheduled as follows,
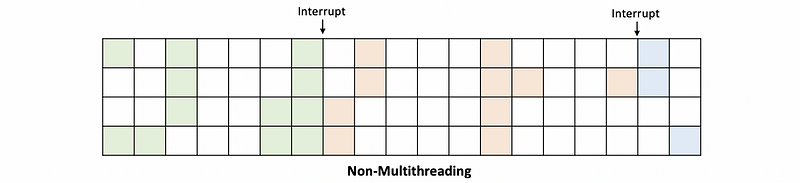
If we have hardware multithreading with fine-grain, which means we can do context switches between different threads to fill the blanks. Note that we have to pay an extra cost (like x1.05) if we want to implement this. Then, we are going to have,

Moreover, there are still some blanks we can fill. And the SMT can be used to fill these blanks. Although we have to pay a higher cost (like x1.5) for the hardware, the performance will be better.

There are still some blanks but we can not fill them up because these blanks are actually caused by the true data dependencies.
(3) SMT Hardware Changes
SMT is not much more expensive than a UMA or Fine-Grained Multithreaded core. It only changes the following parts,
- Add a program counter
- Add a RAT
- Add architectural registers
It will not add ROB because commonly, a ROB is large enough to store all the information we need.
(4) SMT, Data Cache, and TLB
We can not use a VIVT machine for SMT because with a VIVT machine SMT will lead to the wrong data being used. However, with a VIPT and a PIPT machine, the TLB must know which thread belongs to which processor.
(5) SMT and Cache Performance
The cache of the core is shared by all the SMT threads that are currently active on it. The advantage is that we can achieve fast data sharing. The downside is that the cache capacity is also shared by also the threads so that if the working sets of all the currently active threads exceed the cache size, we will have a cache flushing problem and this problem results in lots of cache misses.