High-Performance Computer Architecture 30 | Introduction to Cache Coherence, Coherence Protocols…
High-Performance Computer Architecture 30 | Introduction to Cache Coherence, Coherence Protocols, MSI, MOSI, MESI, MOESI, Directory Approach, and Coherence Misses

1. Introduction to Cache Coherence
(1) Cache Incoherent Problem
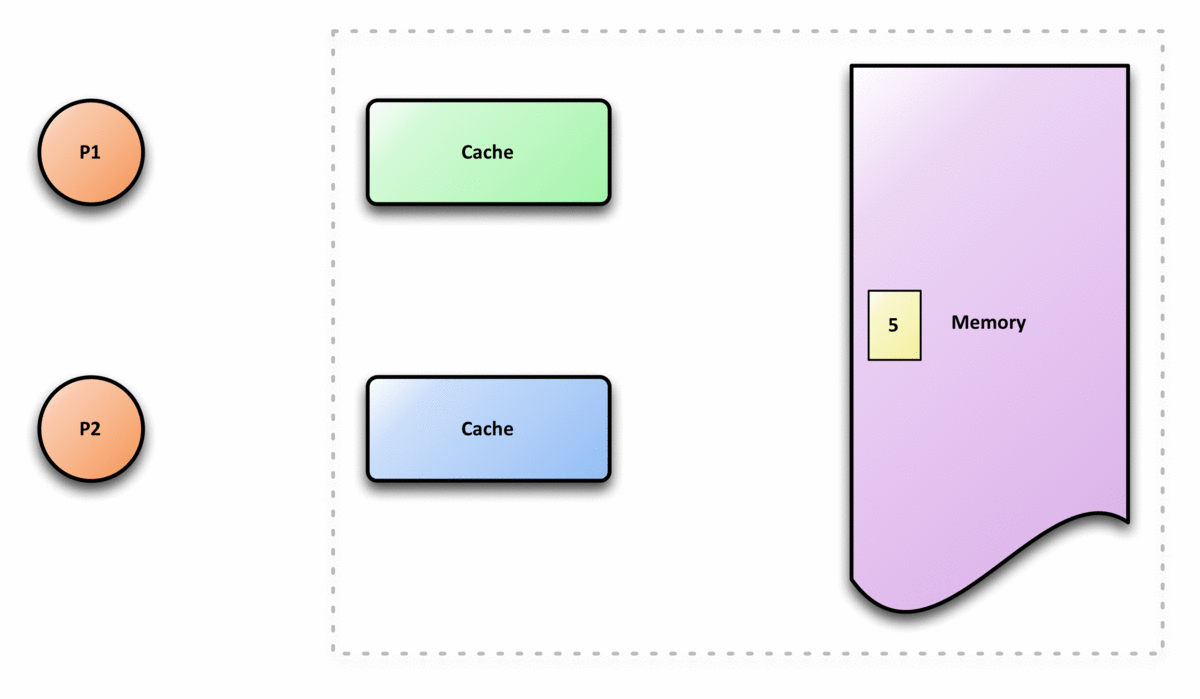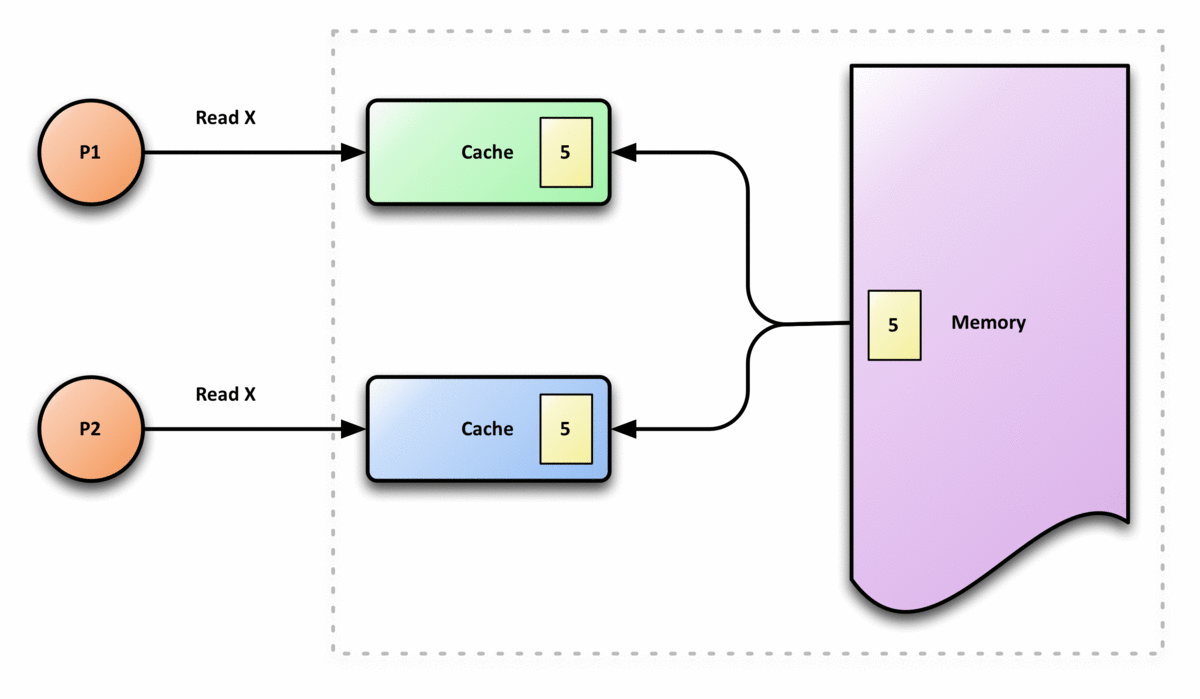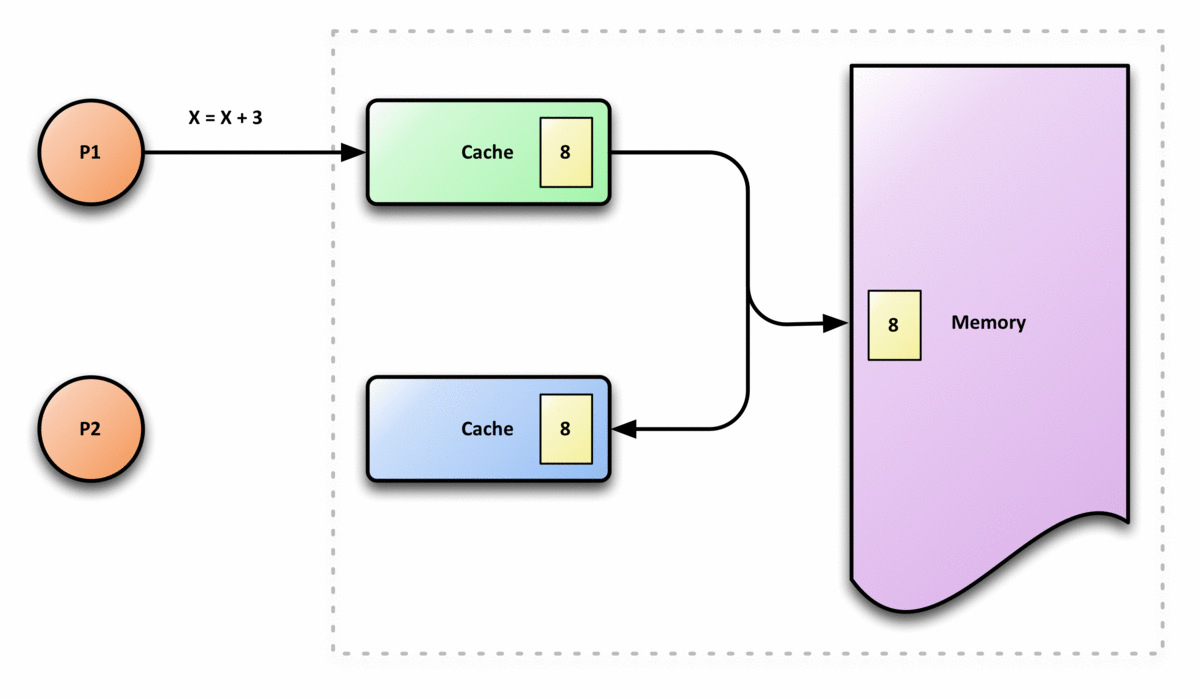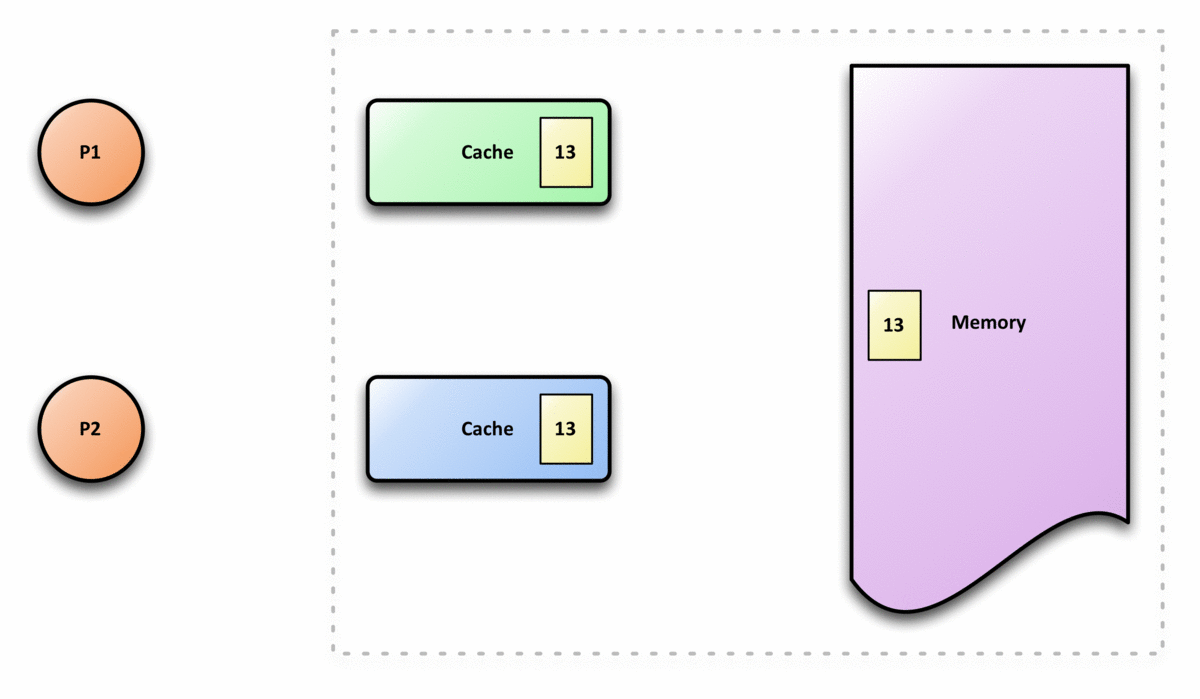
Before we talk about cache coherence, let’s first see why do we need to have cache coherence. When we use the shared memory for multicores, we assume that we can always retrieve the latest value from the shared memory. However, this is not the case in reality because each core has its own cache. If one core writes to its cache, and the cache has not written to the shared memory, then other cores will grab the wrong data from the memory if they need this value. This is called cache incoherence.
The following graph is an example of cache incoherence,
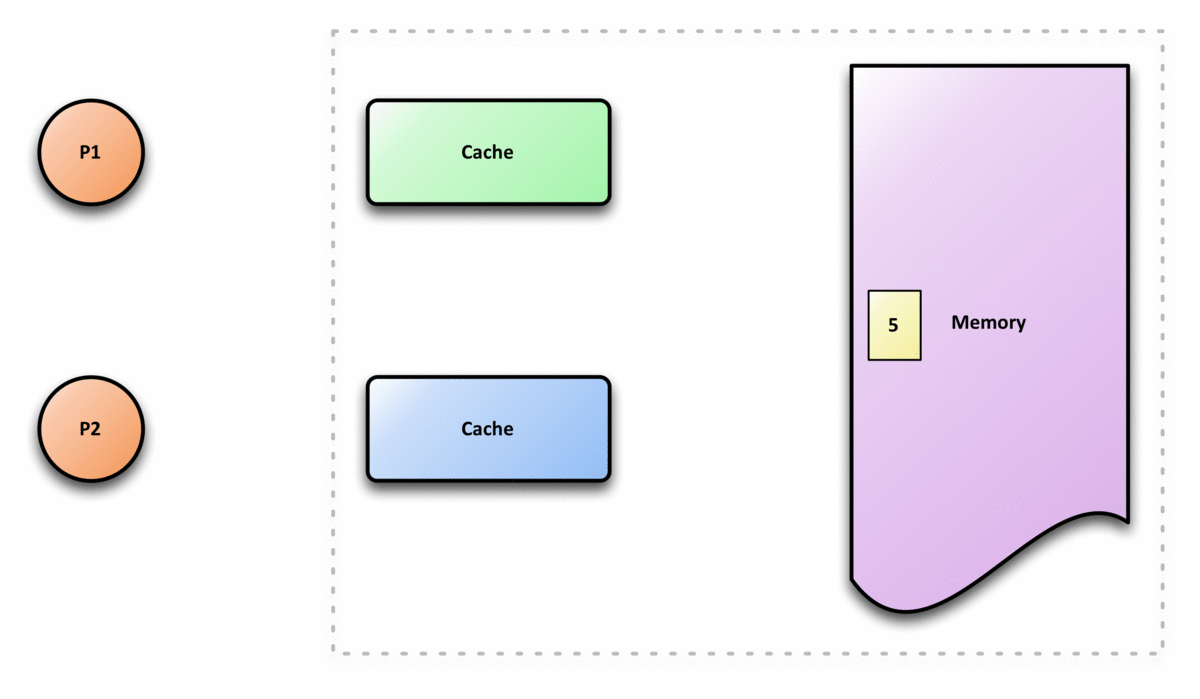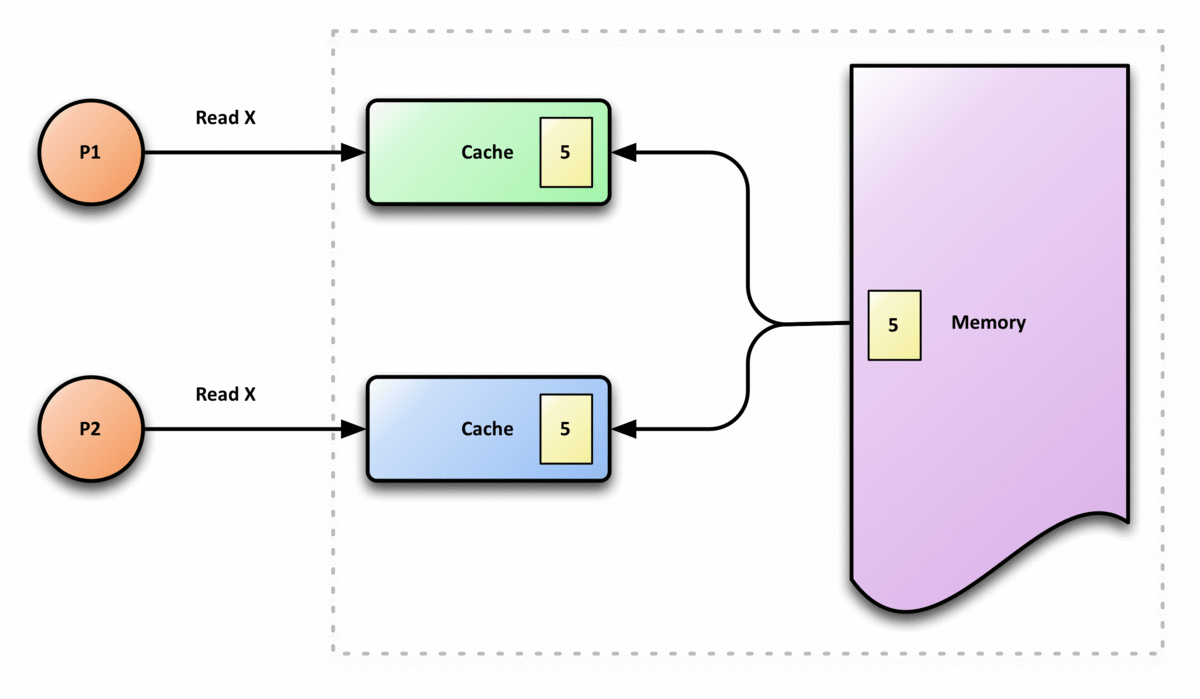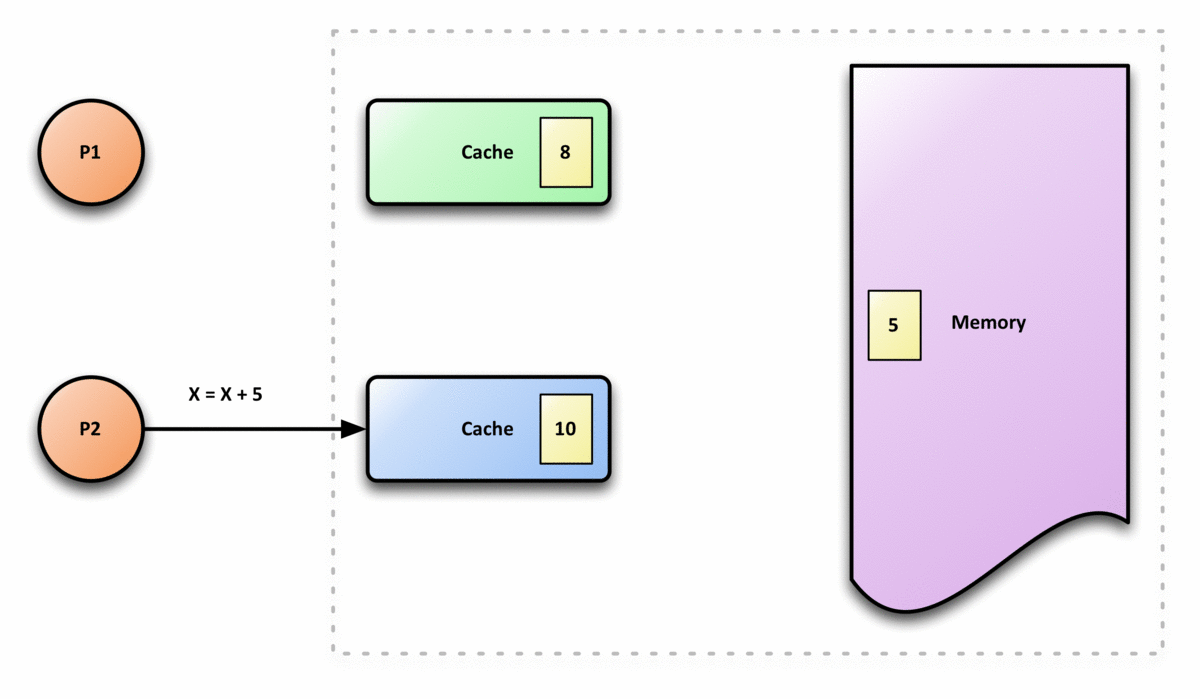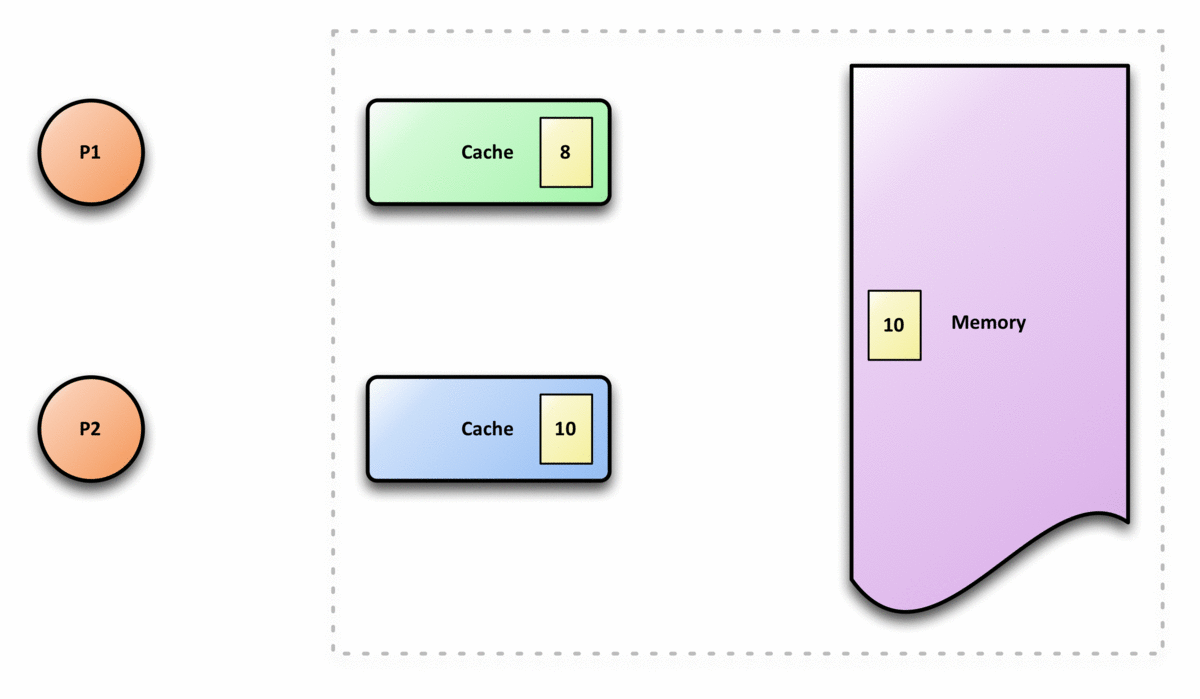
(2) The Definition of Cache Coherence
So let’s now define what it means for caches to be coherent. Intuitively, they are coherent because the two things behave like no caches, and specifically, there are three requirements for the cache coherence,
- Property #1: A read
Rfrom the addressXon the core, C1 returns the value written by the most recent writeWtoXon C1 - Property #2: If C1 writes to
Xand C2 reads after a sufficient time, and there are no other writes in between, then C2’s Read must return the value written by C1 - Property #3: If there are more than 1 writes to the same location, then those writes must be serialized. Any two writes to
Xmust be seen to occur in the same order on all the cores
(3) Cache Coherence Improper Approaches
There are several approaches for achieving cache coherence. However, because some of the approaches have bad performances, we are not going to use them in practice. These approaches include,
- Don’t do caching: if we don't do caching, we will not worry about the cache coherence. However, this approach will have a bad performance, so we normally don’t do so.
- Shared L1 cache: another option is to make all the cores share the same L1 cache. However, because there will be many conflict cache misses, we will still result in a bad performance.
- Private write-through (or write-back) caches: we can also have privates caches and make them write-through (directly write to the shared memory after the cache is updated). In that case, the shared memory actually sees all the writes. But the problem is that once the value is read, it doesn’t matter that all the other cores finish their writings. So potentially, we will see the stale value even after many many writes to the shared memory. So even with write-through caches, the caches are not necessarily coherent.
(4) Cache Coherence Approaches for Property #2
There are two useful approaches that can be used to achieve property #2 of the cache coherence. One technique is called the write-update coherence, and the other is called the write-invalidate coherence.
- Broadcast write to update other caches: this means that the value is not only written back to the shared memory, but it will also be written to all the other L1 caches as well. After that, all the other caches will now have the new value and they will actually provide the same value. This is also called write-update coherence because all the other caches are updated after each writes.
- Pretend to have a cache miss after write: another useful approach is that after a write to the memory, we will also prevent all the other caches from having hits, this means that these caches need to behave as if they have a cache miss or if their blocks are invalid. So this is also called a write-invalidate coherence.
We need to pick one of these approaches in order to suit property #2.
(5) Cache Coherence Approaches for Property #3
For cache coherence property #3, we have to decide the order of the writes and all the cores need to see the same order. This feature brings us two different approaches,
- Snooping: One way is that we can simply broadcast all the writes on the shared bus, and this means that the order of the writes on the shared bus is the order that should be seen by every core. This technique is called snooping because when the writes are sent to the bus, every core snoops this write. The downside of this approach is that the shared bus can become a bottom line.
- Directory: The other way is that each block is assigned an ordering point (aka. directory). Different ordering points can be used for different blocks. For each block, all accesses are ordered by the same entity. But different blocks have different entities so they don’t have a contention. When a write occurs the directory reflects the state change.
2. Coherence Protocols
(1) Write-Update Snooping Coherence
Now, let’s first see an example of the write-update snooping coherence. Suppose have two caches and each of these caches has two blocks with
- a single
- a tag
- data
Both of these two caches are connected to the same bus and we also connect the memory to this bus. Let’s say that the cache is initially empty so that all the valid bits are zero.
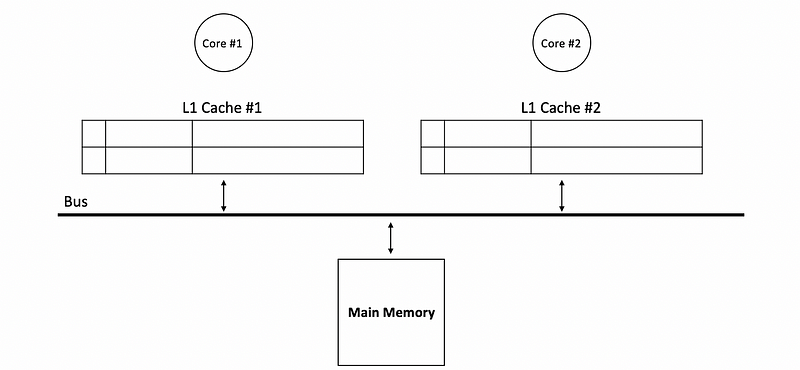
Let’s now see how the write-updating and the snooping works. Suppose we have core #1 read from address A in the beginning. Because the cache is empty, we will have a cache miss and the data is read directly from the main memory. Suppose the data we read is 0, then
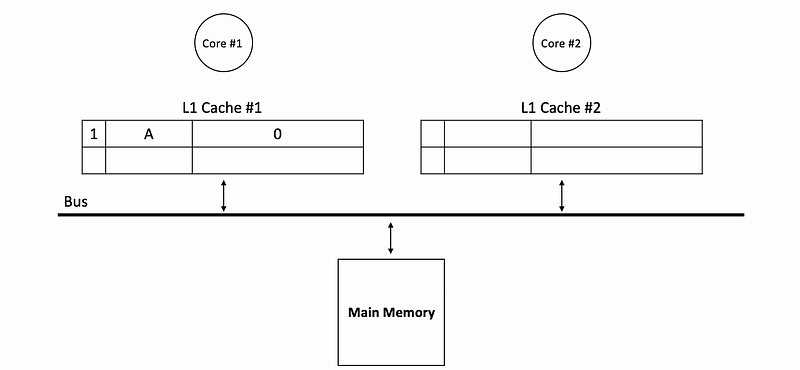
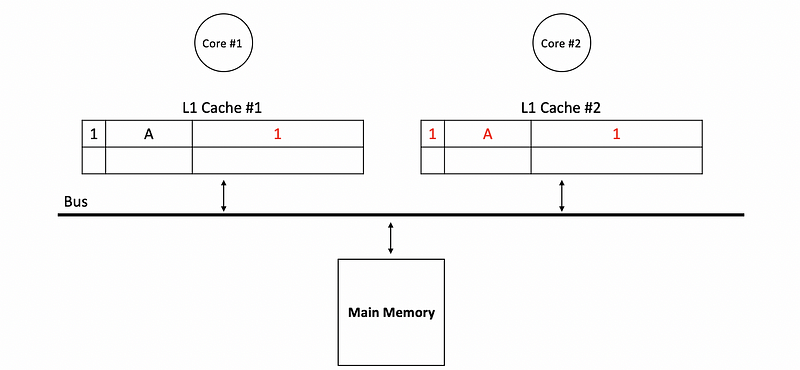
Now, if core #2 would like to write 1 to address A, then in order to achieve a cache-coherent by writing-update, we should not only update the value in the main memory but also we should update the value in cache #1. So the core #1 will snoop the bus and check if there is a tag corresponding to address A.
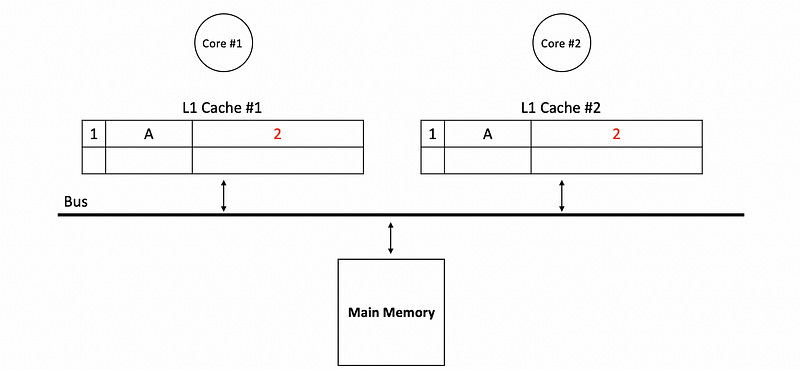
If both of the core write to the bus simultaneously, these writes will be serialized on the bus and then we will have to write to the main memory and update the other caches. Let’s say core #1 wants to write 2 to A, while core #2 wants to write 3 to A, but core #1 writes to the bus in the first place. So we will have,

(2) Write-Update Optimization: Memory Write Bottleneck
Under the condition of a write-update cache, we have a serious problem with memory accesses. As we have discussed for the unicore system, we will achieve bad performance with write-back caches because the amount of the writes can be huge, but the ability for the memory to accesses these writes is limited. Therefore, we can improve the performance by simply remove all the unnecessary writes to the memory. In order to eliminate all the unnecessary writes, we have to add a dirty bit to each block.
Although this dirty bit (D) has a similar function to the uniprocessor system, it actually has some differences. Commonly, this bit has two functions,
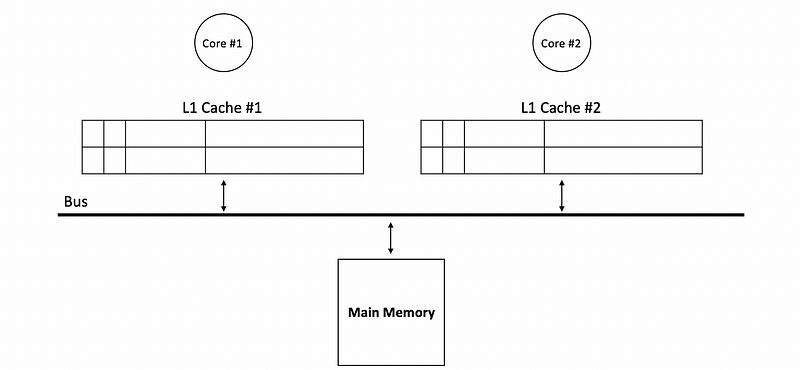
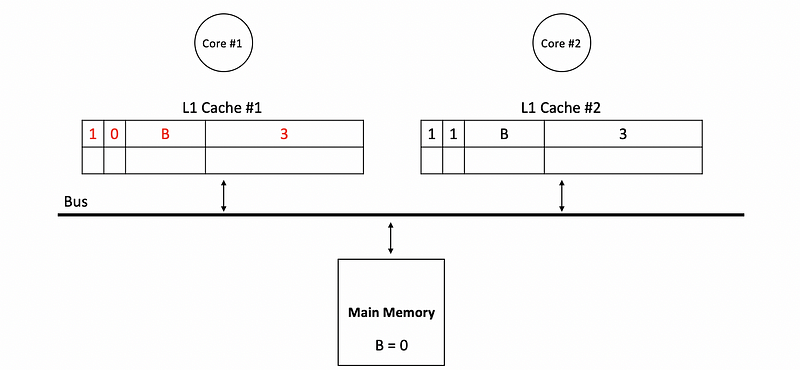
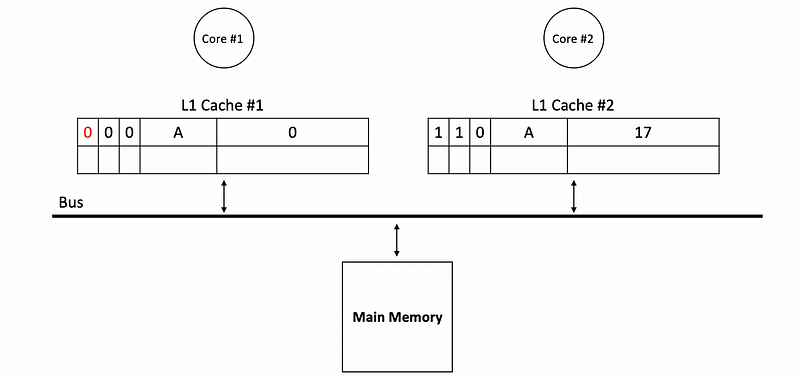
- Avoiding writes to the memory: one function of the dirty bit is that we don’t have to write back to the main memory immediately after each writes. Instead, the dirty bit will be set to 1, and we will only write to the memory when the block with a dirty bit is kicked out of the cache. For example, if we have the following caches in the beginning,
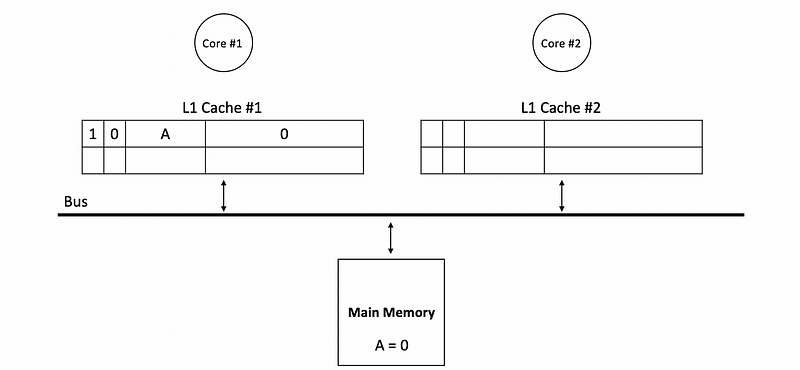
Then a write to A with value 17 will update as follows,
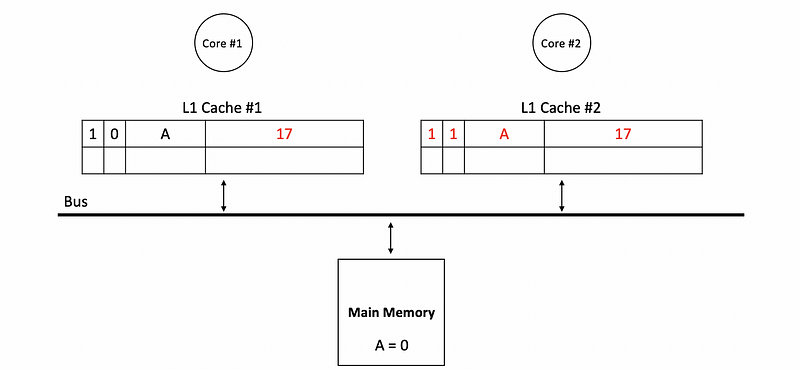
- Directly read from the cache: there is the other function of the dirty bit. Suppose core #1 would like to read from the B now but the true value of B is not updated in the main memory. Instead, the real value of B stays in the L1 cache of core 2,
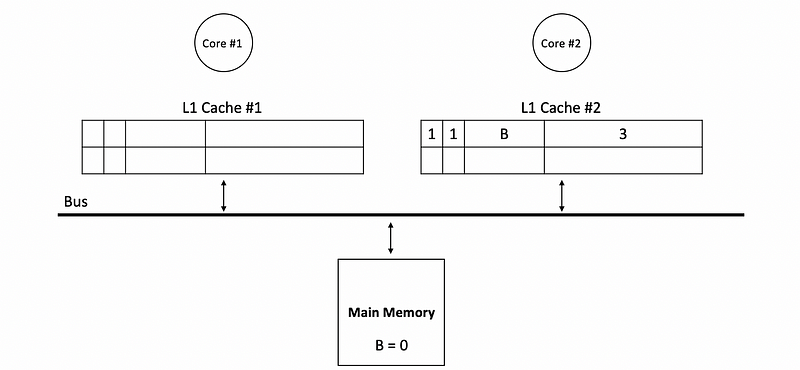
In this situation, we will not read from the main memory to get the value of B. However, we will directly access the L1 cache of core #2, and then, the value 3 is read from the cache instead of the main memory.
(3) Write-Update Optimization: Shared Bus Bottleneck
Now that we have dealt with the bottleneck of the main memory, we have to consider the bandwidth of the shared bus. Because the bus still gets all the traffics for every single write, the bus with all the writes now becomes a bottleneck.
In order to reduce the writes send to the bus, we can add a shared bit (S). The basic idea of this shared bit is that we can reduce the writes sent to the bus if there is no need to update in another cache. So if we write to an address only exists in the current cache block, we will not send it to the bus.
Let’s see an example. Suppose core #1 read A in the beginning and the value of A from the memory is 6. Then core #2 read B and the value of B from the memory is 17.
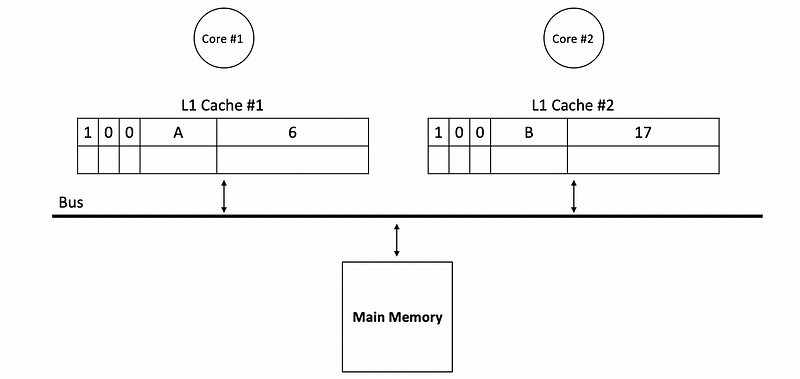
Now if core #2 writes 10 to A, then the L1 cache should be updated. The block of A in cache #2 has a dirty bit of 1 (because we write to A but we don’t write back to the memory) and a shared bit of 1 (because now A is shared by core #1 and core #2). This write will be sent to the bus because the shared bit is 1, which means that we have to update some other caches.
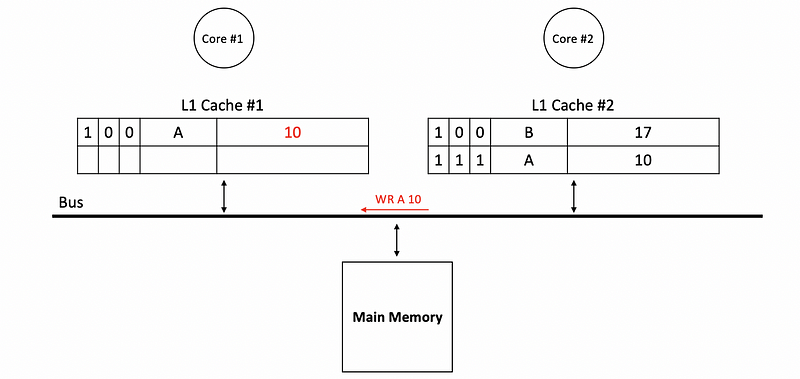
If core #2 writes 5 to B, then the L1 cache of core #1 doesn’t have to be updated. Because the shared bit is 0 for B, which means that B is not shared and we don’t have to update some other caches. Then we don’t need to send this write to the bus and this saves the bandwidth of the bus.

(4) Write-Invalidate Snooping Coherence
Another approach is by using the write-invalidate one. Instead of updating the other caches after writes, we can simply invalidate them. Suppose we have a read A at the beginning and the value of 0 is read from the main memory.
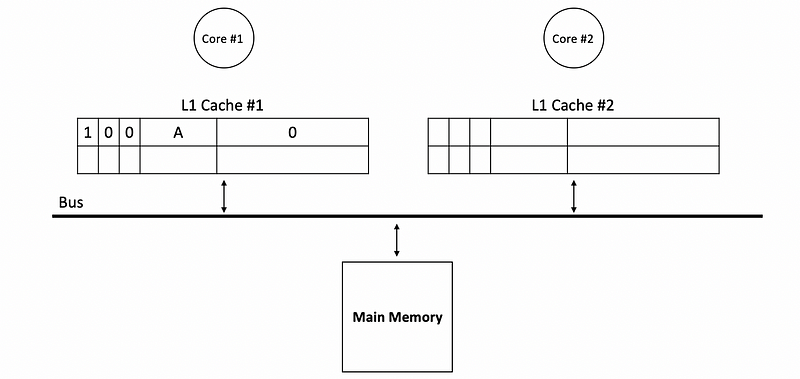
Then suppose core #2 writes to A with value 17. Because we will invalidate the cache with this address A, the valid bit in the corresponding block of cache #1 will be set to 0. Note the shared bit in cache #2 should be 0 because the value of A only exists in cache #2.
(5) Update Vs. Invalidate Coherence
Although we may consider that the update idea is much simpler, in practice, it is only used when one core writes and another core reads often. If an application has a burst of write to one address or if an application writes to different words in the same block, then invalidate is the better method.
(6) MSI Coherence
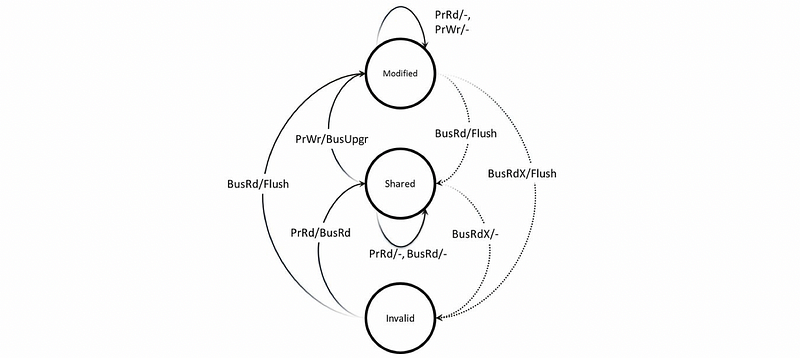
One simpler coherence protocol is called MSI coherence (aka. modified-shared-invalid) and it s is an invalidation-based protocol. In MSI, a block can be in one of three states in a cache,
- Invalid state: (Valid bit = 0) present in the cache with a 0 valid bit or simply not in the cache
- Shared state: (Valid bit = 1; Dirty bit = 0) a block in the shared state means that we can do simple reads without any further ado. However, we have to do some extra work if we want to write to it
- Modified state: (Valid bit = 1; Dirty bit = 1) in this case, we can do local reads and local writes without any further work. This is because we have known that the current block we are operating is not a shared block.
(7) Cache-to-Cache Transfers
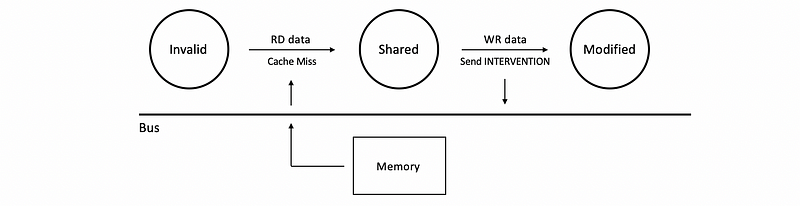
In the previous examples, we only said that if the cache has its dirty bit equals 1 (which is exactly in the modified state), we will not read from the memory. Instead, we can directly read from the cache. This process is called a cache-to-cache transfer.
When core #1 has block B in the modified state, and core #2 puts a read request for B on the bus, core #1 has to provide the data. In order to provide the data in core #1, basically, we have two methods,
- Solution #1: Abort & Retry
The first solution is that the core #1 somehow cancels the request from core #2 by an ABORT bus signal. When a request is placed on the bus, another core can assert the abort signal that tells the requesting core to back off and try again later. After the request from core #2 is aborted, core #1 can do a normal write back to the memory. At this point, the memory has to update the data and when core #2 retries its read request, it will get the data from memory.
The problem of this solution is that we will have two memory latencies before the core #2 can get the data. One for the write-back to memory to happen on C1, and then for us to actually get the data from the memory. Because w have to pay twice the memory latency, this solution is not ideal for us.
- Solution #2: Intervention
The second solution is called intervention. In this case, core #1 tells the memory that it will supply data by a INTERVENTION bus signal through core #1 asserting the intervention's signal signals to the memory not the responds. After that, core #1 will respond to the request with data. However, after responding to the request, the dirty bit of the cache of core #1 will become 0 and this means that all the caches will be in the shared state. So the memory should also read from the response from core #1 and updates its values, and the memory ensures that it gets the data that will not be written back anymore.
The problem with this solution is that this solution needs more complex hardware. In most modern processors, we are actually using a variant of an intervention approach because the complexity to respond is not too large compared with two memory latencies.
(8) Cache-to-Cache Transfer Writing Overheads
When we do cache-to-cache transfer, there are actually two aspects that we can improve.
- Unnecessary memory writes: suppose in the beginning, c1 (core #1) has the block in the M state and c2 (core #2) wants to read. By intervention, c2 will read from the c1 instead of the memory. After c1 responds to the request of c2, both the blocks in c1 and c2 become S state and the memory is also updated. Now if c2 writes to the block, c1 gets an I state and c2 gets an M state. If we continue this loop by c2 starting with M state and c1 reads from it, then we can finally achieve a result that the data is moving around between the caches and we don’t actually need to write to the main memory so many times in this case.
- Unnecessary memory reads: there are also some unnecessary memory reads in the MSI protocol. When c1 sends a read request and c2 provides the data, both of them will become the S state and the data will be written to the main memory. Now when we have another core c3 who would like to request the data, we can only send the request to the main memory although both c1 and c2 can provide the data. Therefore, in fact, there are some unnecessary memory reads.
(9) The Definition of the Owner State (O)
In order to deal with the unnecessary memory reads and writes, we need to make a non-modified version of the block in one of the caches that are responsible for,
- giving data to other caches (so that we don’t need unnecessary memory reads)
- eventually writing block to the memory (so that we don’t need unnecessary writes)
So what we really need to know is which of the shared copies is the one responsible, and we will know this by introducing another state called owned (O).
(10) MOSI Coherence
MOSI is designed to deal with the problems we have talked about for the MSI coherence. The MSI and MOSI are similar, but the main difference is that when we are in the modified state, we provide the data as before. But after providing the data, we will move into the O state instead of the S state. By moving the block into the O state, we will not update the memory immediately.
When a block is in the O state, it will basically have two functions,
- providing data: when it snoops a read (only necessary reads)
- write back to memory if replaced (only necessary writes)
So eventually, we have used the MOSI state to avoid the inefficiency of the MSI protocol that had to do with the memory, getting unnecessary accesses that could be satisfied by caches that already have the data. However, there is another inefficiency that both MSI and MOSI have, which is related to the thread-private data that is only ever accessed by a single thread.
Now, let’s to talk more about this inefficiency problem.
(11) The Definition of Thread-Private Data
The data that is only accessed by a single thread is called the thread-private data. For example, all data in a single thread will be thread-private. So if we have a 4-core processor around four single threaded programs, they will never share any data.
Even if we have a parallel program, we still have some data (e.g. data in the stack) that are still can only be accessed by a single thread.
(12) Inefficiency Problem for MSI and MOSI
With both MSI and MOSI, we have the inefficiency when we read the data in a thread and then we write to it, and the current thread is the only one that is accessing the data. When we read the data with the I state, we will have a cache miss and then we will access the memory to get the data. After that, the block will be at the S state. If we then write a new value to this block, we will first send INTERVENTION to the bus so as to invalidate all the other caches with the same block.
But this can be inefficiency when we only have one thread that has this data. Actually, we don't have to send INTERVENTION to the bus because the current data is private for the current thread and it can not be accessed by the other cores and caches.
We can notice that the send INTERVENTION penalty to the bus is actually what we have paid in this case for cache coherence, because we have assumed that no data are private, and we can always share the data. So what we want to do is to reduce the cost of sending this INTERVENTION to invalidate other cache blocks when the current block is thread-private. To avoid this invalidation, we will include a new state called exclusive (E).
(13) The Definition of the Exclusive State (E)
Before we talk about the exclusive state, let’s review some other states,
- M state: the modified state gives us exclusive access so that we can do both read and write. And it makes us the owner of the dirty block so that we are going to update the memory.
- S state: the shared state gives us the shared access so that we can only read. And we are not responsible for giving data to the other caches or the memory, so we are clean in this state.
- O state: The owned state also gives us a shared access so that we can do reads. However, it makes us the owner of the dirty block so that we are responsible for giving data to the other caches or the memory.
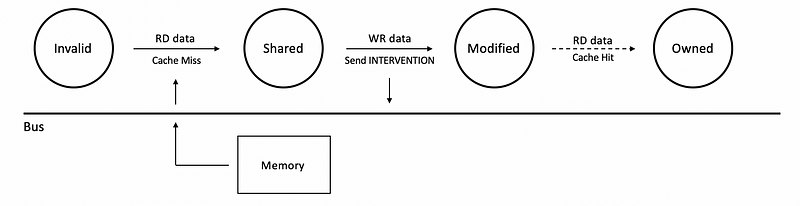
What the exclusive state does is that,
- E state: it gives us the exclusive access so that we can do reads and writes. However, the block is still clean and the memory don’t have to be updated.
(14) MESI/MOESI Coherence
So finally, let’s talk about how the exclusive bit works to deal with all the thread-private data inefficiency. Let’s again, see an example of the read then write case for four different protocols.
If we first read A and then we write to A, as we have said, both the MSI and MOSI coherence will write to the bus twice. One for the cache miss after read, the other for sending the INTERVENTION signal.
However, for MESI and the MOESI, we don’t go directly to the shared state if we detect we are the only one that having this block. So instead, we will go to the exclusive state (E). So now when we write data to it, we know that this is an exclusive access. So that we can write without telling anybody. After that, we will transite to the M state, because the block is dirty and we have to write to the memory in the future.
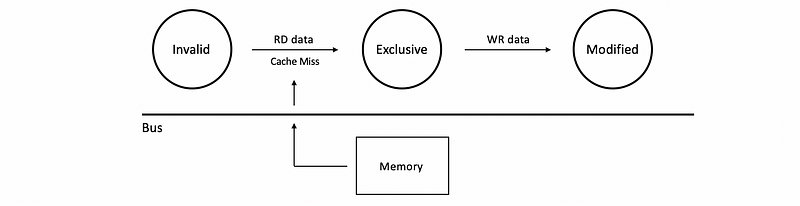
Finally, a general MOESI coherence protocol should be as follows,
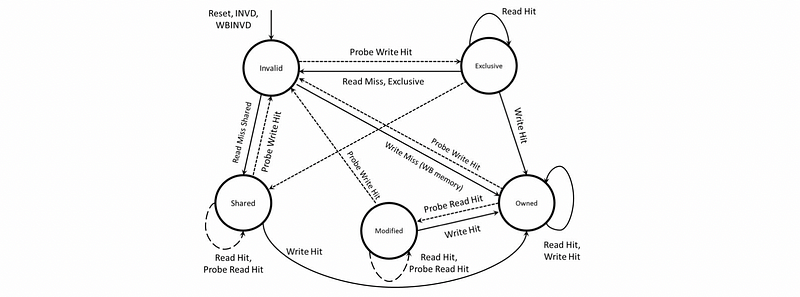
3. The Directory Approach
(1) Snooping Downsides
In the previous discussions, we have discussed that the other way to achieve the cache coherence is by a directory-based method. Before we talk about the directory, let’s first see what’s wrong with snooping. With the snooping approach, we can find out thart all the requests will be broadcasted to the bus so that the others can see them and establish ordering. However, the bandwidth can always be limited and we will have a bottleneck on the bus.
Therefore, the snooping approach doesn’t work well with more than 8 to 16 cores.
(2) The Defintion of Directory
The directory structure is a distributed structure across all the cores. It is not centralized in one place like the bus. Therefore, not all requests have to go to the same part of the directory.
- Each “slice” of the directory will serve a set of blocks
- Each core has its own “slice”
Therefore, we can achieve a higher bandwidth because each slices will operate independently. In fact, a slice has,
- Entries for blocks it serves, which tracks the information about which caches in the system have a non-invalid state.
- The order of accesses for a particular block is determined by the home slice of that block. So that accesses goes to the same block are serialized
Even if we have the directory protocol instead of the snooping protocol, the caches still have the same state (M/O/E/S/I). What is different is that when we send a request, the request no longer goes to the bus. Instead, the request will be sent via the network to the directory. Therefore, we can have many requests travelling to the individual slices, and then the directory figures out what to do next.
(3) The Directory Entry
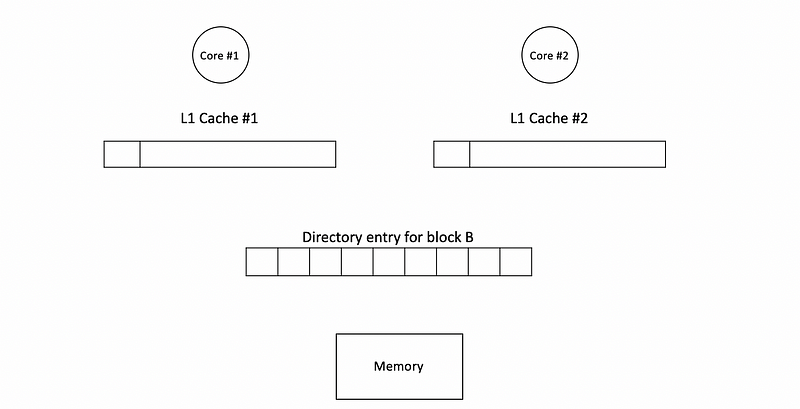
Now, let’s see the organization of the directory entry. Each directory entry has,
- 1 dirty bit: indicates that the block is dirty in some cache in the system
- cache bits for each caches: indicates whether or not the data present in that cache. There should be 1 cache bit per cache in the entry.
(4) The Directory Entry: Example
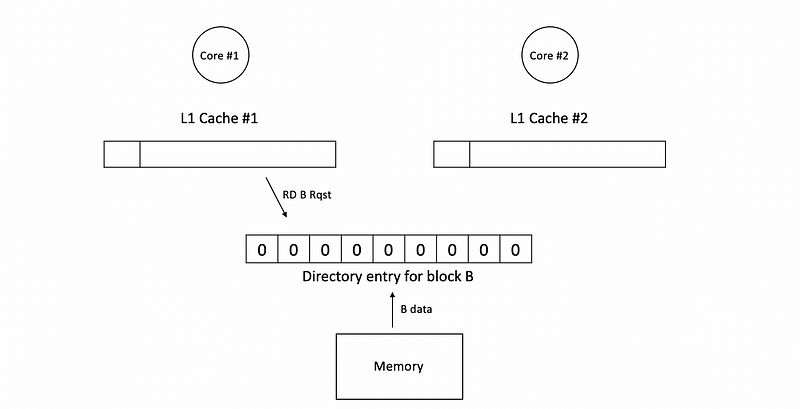
Now, let’s see an example of the directory entry. Let’s suppose we have 8 caches in the system (cache #0 ~ cache #7, but only cache #1 and cache 2 are shown). At the beginning, all the caches and the directory structures are empty.
Then if c1 send a read B request, we will first go to the directory and check if B exists in the system.
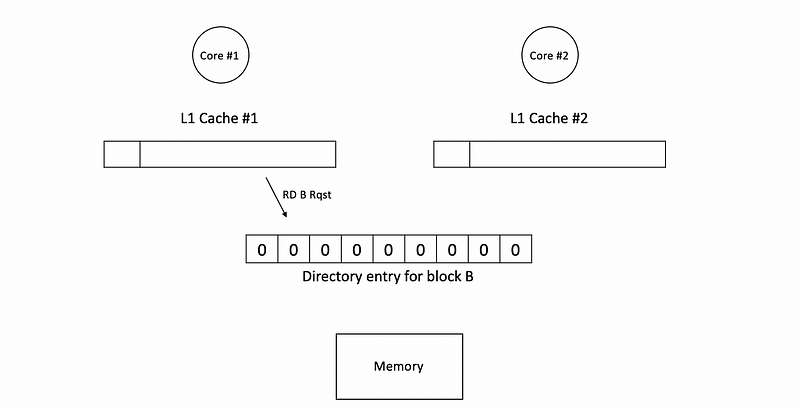
Becasue all the caches are initially empty, the directory will figure out a cache miss and then it will get B from the memory,
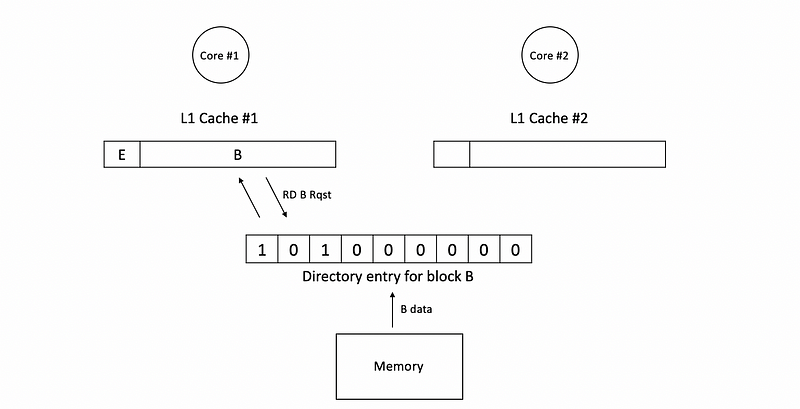
Then the data of B will be sent to c1 and the corresponding block in c1 will be in the E state (suppose we have MOESI protocol), and the directory will give exclusive access to c1. Because now the cache #1 has the B block, we will have to set the corresponding cache bit in the directory entry to 1. What’s more, because now c1 has exclusive accesses for read and writes, we will also set the dirty bit in the directory entry to 1 so that it will always check the c1.
Now, let’s suppose c2 sends a write B request,
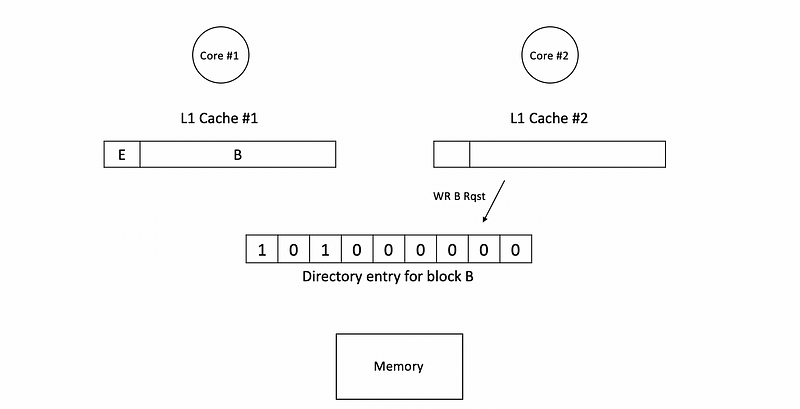
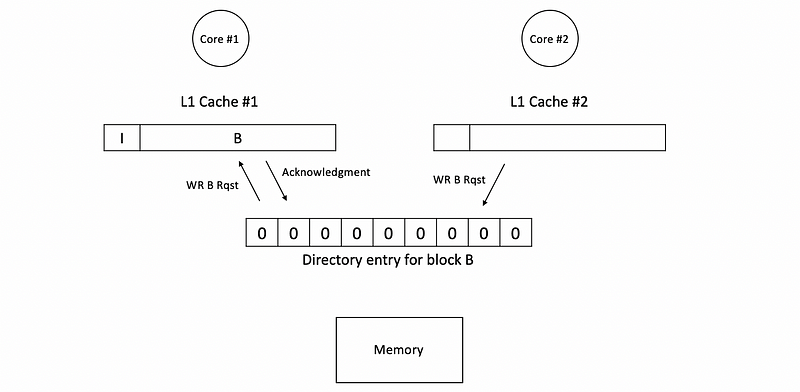
Because the dirty bit of the directory entry is 1, we have to invalidate block B in c1. Therefore, before conduct the write request, it will be firstly send to the c1 and the corresponding block B in c1 will be invalidate.
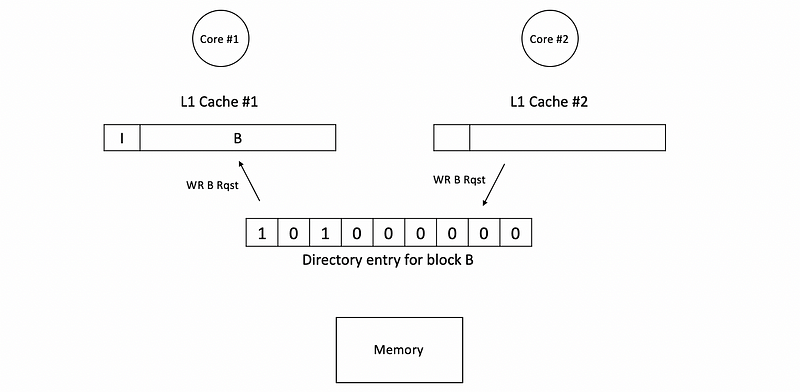
Before c1 is invalidate, the block B in c1 is in the exclusive state. So it can choose to respond with the data or it can just keep quite and confirm the validation. So that after the cache gets the write request, it will send at least the acknowledgment for invalidation if not with the data back to the directory, which means that the invalidation is done. When the acknowledgment arrives to the directory, the corresponding entry with the cache bit will be reset to 0, and if the data didn’t arrive, then we can simply replace the dirty bit.
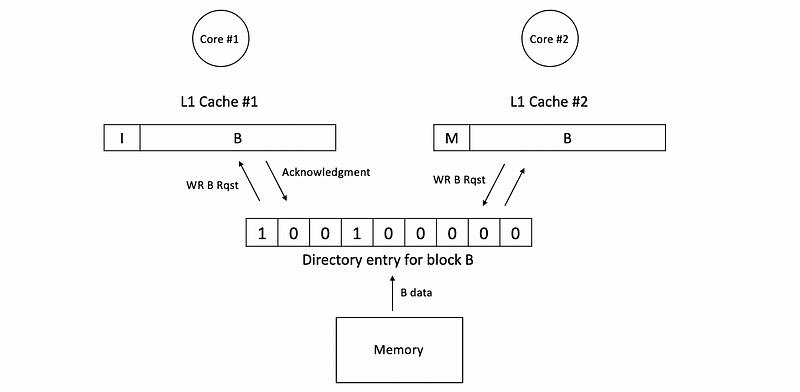
Because now the caches seems all empty again and we have to access the memory to get the block B. Again, we will get cache B from the memory and then send it to c2. The corresponding bits in the entry will be changed. After c2 gets the block, it will write to the block with its new value and then the block state becomes M.
The reason why we can have higher bandwidth is because when c1 send a request to for B, c2 can send requests for maybe D to another directory without worrying about the bandwidth. Therefore, the bandwidth for requests will be enlarged.
(5) Coherence Misses
We have talked about the cache misses and we have known that there will be 3Cs of cache misses. These include,
- compulsory misses
- conflict misses
- capacity misses
However, now we can have the another kind of cache miss, which is called the coherence misses. The coherence miss happens because we invalidate some blocks in the cache to maintain the cache coherence. There are actually two kinds of coherence misses,
- True sharing coherence misses: the cache misses we have seen so far, which happens when different cores accessing the same data. For example, let’s suppose we have the following two blocks in a 4-core system,

Then if we do,
c0: RD X
c1: WR X
c0: RD X <- True sharing coherence misses
Then we will have a true sharing coherence misses in the third operation.
- False sharing coherence misses: this occurs when different cores access different data so that there should not be any coherence messages because of that, except for these data items are in the same block. For example, if we still have the following two blocks in a 4-core system,
Then if we do,
c0: RD X
c1: WR W
c0: RD X <- False sharing coherence misses
Then we will have false sharing coherence misses in the third operation.