High-Performance Computer Architecture 31 | The Introduction of Synchronization, Atomic Exchange …
High-Performance Computer Architecture 31 | The Introduction of Synchronization, Atomic Exchange Instructions, Test-then-Write Family, Load Link, Store Conditional, Barrier Synchronization, and Flippable Local Sense
- The Introduction of Synchronization
(1) The Definition of Synchronizations
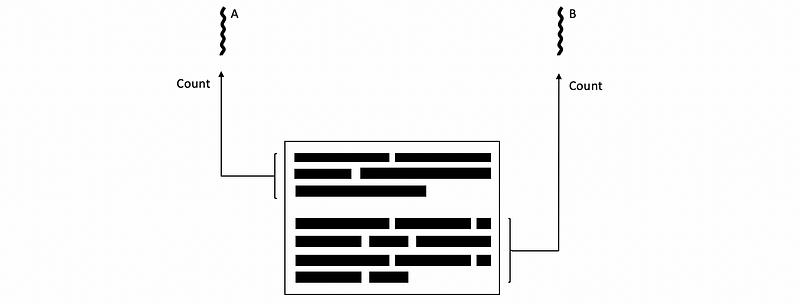
Because we can have multicores and multi-threads that are trying to work together in the same program, we will need synchronization. For example, let’s say we have two threads and what they are doing is counting the occurrences of different letters in an essay. The first thread is called thread A, which will be counting the first half of the document, and the second one is called B, which will count the second half.
Suppose the programs we have for thread A and B are,
// for thread A
LW I, 0(R1)
LW C, Count[I]
ADD C, C, I
SW C, Count[I]
// for thread B
LW I, 0(R1)
LW C, Count[I]
ADD C, C, I
SW C, Count[I]
And it is clear to find out that they are the same because we are operating on the same Count[i] array. Let’s suppose that at a time, both of the threads A and B read from the document and get the same latter A, then they will simultaneously index to the same position and load the same counting value. Suppose we have 15 in the Count array before reading these two letter As,
// for thread A
LW I, 0(R1) // -> I = 'A'
LW C, Count[I] // get C = 15
ADD C, C, I // C = 16
SW C, Count[I] // Count['A'] = 16
// for thread B
LW I, 0(R1) // -> I = 'A'
LW C, Count[I] // get C = 15
ADD C, C, I // C = 16
SW C, Count[I] // Count['A'] = 16
However, both of these two threads will write 16 back to the program and this is not correct. What we actually need is that we want to increase letter A in sequence and get a final result of 17. Therefore, this is definitely an incorrect behavior against what we expect.
(2) Synchronization Example
Now, let’s see a real program that shows us why should we maintain synchronization for a multithreading program. If you can not understand the following code, the following articles may help.
What we are going to do is that we would like to implement the program we have discussed. We are going to create 2 threads and one thread counts the first half of the file and the second one counts the second half of the file. To make things clear, we will have 320 letter A in the document called text.txt with the first half and the second half separated by an escape character \n. We expect to count 320 of A as a result, but if we have a number smaller than that, then we probably have some synchronization problems.
The document should be,
And the program should be,
If we run the code above several times, we may probably get the following results,
A: 320
A: 320
A: 302
A: 320
A: 293
...
You can find out that even though some of them count the write value as we expect, there can be some cases we have a synchronization problem.
(3) The Definition of Atomic (Critical) Section
In the last example, we don’t want both of the threads loading from the memory and get a value of 15. What we want is that these two threads can execute in sequence. Therefore, we may want to exclusively execute some of the code in the program as follows,
LW I, 0(R1)
// exclusive ============
LW C, Count[I]
ADD C, C, I
SW C, Count[I]
// exclusive end ========
If the bold codes are exclusively executed among threads, we can avoid the interleaved sections of those two threads, and they should happen one at a time. The code section that can only happen one at a time is called the critical section or the atomic section.
(4) The Definition of Mutex (Lock)
To implement a critical section, we have to use synchronization called mutual exclusive (aka. mutex, or lock). So what we really need before we get into the critical section, we need to lock a global mutex (means that this mutex should be in the shared memory of all threads that requires this lock), which can be seen by all the other threads, so that if there are any other threads who would like to lock the mutex will be blocked and these threads will spin there until the mutex becomes unlocked. Once we can grab the mutex, we are able to enter the critical section. In the previous example, we are going to maintain an array of mutexes Countlock for each counter. Therefore, the code for the two threads above should be,
LW I, 0(R1)
lock Countlock[I] // lock
LW C, Count[I]
ADD C, C, I
SW C, Count[I]
unlock Countlock[I] // unlock
(5) Mutex Implementation: A Paradox
Now, let’s see how we can implement a mutex. As we have said, the mutex is only a global data structure in the shared memory as a normal variable, and it can be used to control whether we can access a thread or not. Therefore, we can use a simple int type to implement a mutex, and also we will write some functions for it. In our example, we will initialize mutex as 0 in the beginning, which means that we can lock and access the critical section. After the mutex is set to 1, the other threads acquire the lock will be blocked.
So the mutex_type is defined by,
typedef int mutex_type;
And the initialization function should be,
void mutex_init(mutex_type *mu) {
*mu = 0;
}The locking function should be,
void mutex_lock(mutex_type *mu) {
while (*mu == 1) {}
*mu = 1;
}And the unlock function should be,
void mutex_unlock(mutex_type *mu) {
*mu = 0;
}After implementing these in our previous code, we can have,
If we run the code above several times, we may probably get the following results,
A: 320
A: 294
A: 299
A: 320
A: 319
...
It seems that our mutex is not working and we still have synchronization problems. Well, how does this happen? To answer this question, let’s review the mutex_lock function.
void mutex_lock(mutex_type *mu) {
while (*mu == 1) {}
*mu = 1;
}Suppose we have two threads now and when they execute while (*mu == 1) {} simultaneously. Then both of them will consider mu = 0 and they will not be locked. Therefore, we will result in some synchronization problems.
In order to deal with this, we should have a magic lock that does not rely on the mutex, and it will make the while statement mutually exclusive among all the threads.
void mutex_lock(mutex_type *mu) {
magic_lock(lock);
while (*mu == 1) {}
*mu = 1;
magic_unlock(lock);
}So now here’s the paradox. If we have this magic lock, we don’t have to implement a mutex because the magic lock can be used as the mutex. However, if we don’t have this magic lock, we can not implement the mutex either. So in conclusion, we need a mutex to implement a mutex, which can be impossible for us, and what’s more, there is also no magic.
(6) Mutex Implementation: Solutions
Now, let’s see what do we do if there’s no magic. There are several ways to get the effect that the magic lock will give us,
- Lamport’s Bakery Algorithm: this algorithm is able to use normal loads and saves to replace the magic lock. But this algorithm can be too complicated with tens of instructions per lock. So it can be slow and expensive.
- Special Atomic R/W Instructions: another way is to use so-called special atomic read and write instructions. So there would be an instruction that does this check and set to 1 and that will allow us to have only one instruction access the critical section without needing the magic. These instructions can be briefly called atomic instructions.
(7) Common Atomic Instructions
There are three main types of atomic instructions. These include atomic exchange instructions, test-then-write instruction family, and LL/SC instructions.
We are going to introduce them in the following sections.
(8) Atomic Exchange Instructions
For example,
EXCH R1, 8(R2)
this instruction means that we are going to swap the data in R1 and in the address of 8(R2) in the memory. Therefore, we will conduct a load instruction from the memory and write to R1, and we will also conduction a save instruction from R1 to 8(R2). When we have this instruction, what we can do is that, we will write 1 to the R1 register and we will looply check the value of R1. Suppose we have two threads acquiring the same mutex = 0, we will do one more check on the R1 after it gets the value of 0 from mu. Therefore, only one thread can be unlocked and we will lock the mutex properly.
R1 = 1;
while (R1 == 1) {
EXCH R1, mu;
}
The drawback of this is it continues to swap while waiting to acquire the lock and we can avoid the unnecessary swaps by the test-then-write instructions.
(9) Test-then-Write Family
We also have a test-then-write atomic instruction family, which will test some conditions before we conduct the instructions. For example,
TSTSW R1, 8(R2)
This means that before we store the value of R1 to 8(R2), we will first test whether 8(R2) = 0. If it is not 0, we will not write to it. So this method corrects the drawback of the Atomic Exchange.
For example, if we have the TSET instruction of,
TSET R1, Addr
which is the same as,
if (Mem[Addr] == 0) {
Mem[Addr] = 1;
R1 = 1;
} else {
R1 = 0;
}Then the mutex lock can be implemented by,
void mutex_lock(mutex_type *mu) {
R1 = 0;
while (R1 == 0) {
TSET R1, mu;
}
}(10) Load Linked (LL) / Store Conditional (SC)
The test-then-write instructions are good but it is hard to implement because it is actually a strange instruction, and it is neither a store or load. It would be ideal for processor design if we could do something like load&store yet behaves in the way of a test-then-write instruction. This brings us to the linked load (LL) and the store conditional (SC) instructions.
The reason why this is bad for the processor design is that this is bad for the pipeline. Suppose we have a normal five-stage pipeline and we need to implement atomic read and write in the instruction, we can not finish both load and store in a single M stage. Therefore, in order to implement this, we need to have more M stages (e.g. M1 and M2) as follows,
F D A M W -> F D A M1 M2 W
So the basic idea is that we should only one thread can read from the mutex at a time. After the mutex is read by one thread, all the other threads should know that it is already read by some information accessible for all the other threads. The structure LL and SC use to share the information is called the link register. Let’s now see an example. Suppose we have the following code,
LL R1, mu
SC R1, mu
What we need is that if the LL finds the lock variable mu available, and we try to do an SC, then the SC will only succeed when if the lock is still available at that time. The key is that if we snoop a write to the lock variable after LL, we will put a 0 into the link register. Then if the LL loads the lock variable and we see that it is free, and then we will try to do an SC. If some other thread beats us to it, then SC will fail because the link register will not match the local variable.
Let’s suppose we have to read 12 from the memory, increase by 1, and put it back to the memory. Assume we have two threads, and they will load from the memory simultaneously. Then we have,
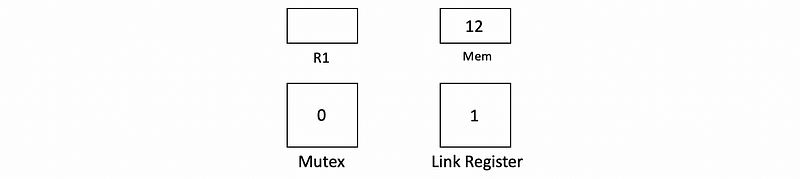
At the beginning, both of the threads will LL 12 from the memory to R1 because the mutex is initially 0. After the load, the mutex will be set to 1 in order to block the other threads.
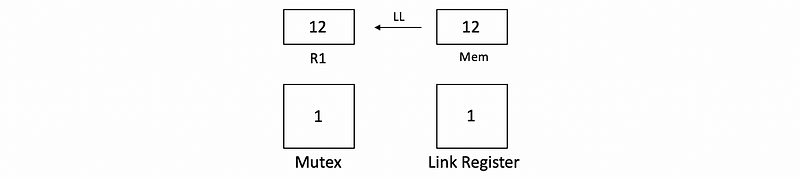
For normal loads and saves, we will then increase 12 to 13 and write it back to the memory. It is obvious that we will have a synchronization problem. However, for LL and SC, after we increase the value in R1 from 12 to 13, the first thread writes to the memory will first check if the mutex matches the linked register. If these values match, we can then save the value to the memory,
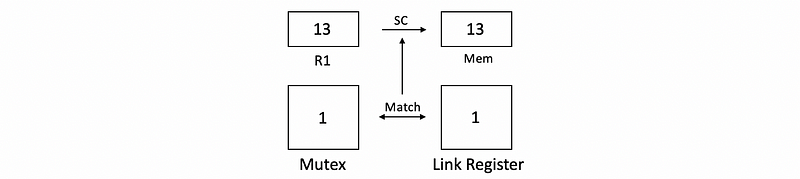
After the first thread writes to the memory, the link register will be set to 0. Then before the second thread writes to the memory, it will also check if the mutex matches the linked register. However, because the link register is set to 0 because of the first thread, the value in the mutex doesn’t match the value in the link register. Then the SC instruction figures out we have a synchronization problem. So what we are going to do next is that we are going to abort the value in R1 and retry LL from the memory.
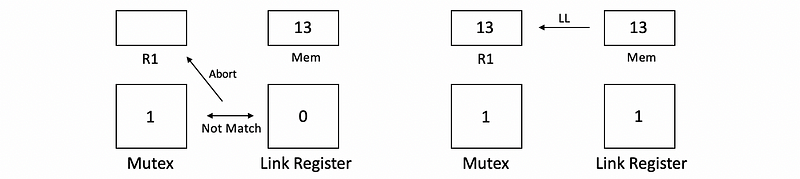
Now, if we continue the second thread, we will get the correct value and then the correct value will be written to the memory. Now, we perfectly deal with the synchronization problem.
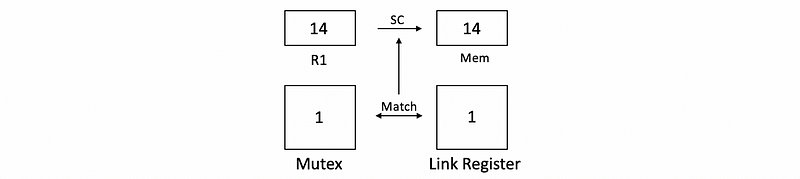
So the pseudocode for implementing this LL/SC approach is,
void mutex_lock(mutex_type *mu) {
trylock:
MOV R1, 1; // set a variable = 1
LL R2, mu; // load mu to R2
SC R1, mu; // check whether mu = R1
BNEZ R2, trylock; // if mu = 0, we should retry
BNEZ R1, trylock; // if not match, we should retry
}Note that we can not explicitly read from the index register.
(11) Lock Performance
Let’s now consider an example of how the atomic exchange instructions interact with coherence protocols and what is the performance of the lock. Initially, the mutex is initialized to 0, and the R1 register in each core is set to 1. All the caches are empty in the beginning.
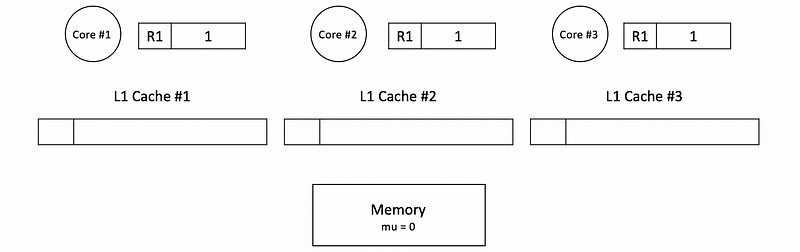
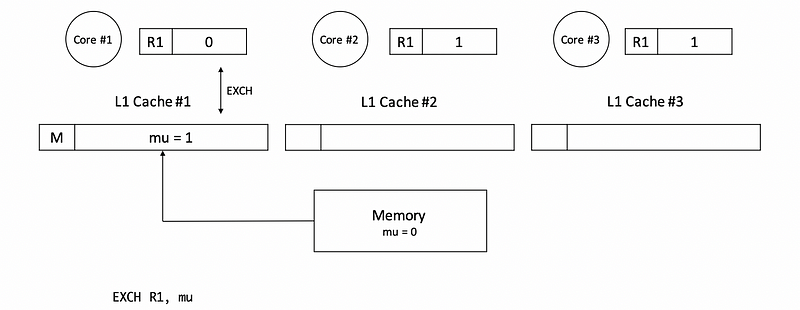
Let’s say that core 0 tries to grab the mutex first and successes. Because the mutex is initially in the memory with a value of 0, we have to read this value to cache #1. After that, we will exchange the value in R1 and mutex mu so that the block mu will be in the M state.

Before mu is unlocked by core #1, let’s suppose then core 2 requires the lock and tries to enter the critical section. However, this will fail because at this time, we will not require the mutex from the memory. Instead, there will be a cache-to-cache transfer from cache #1 to cache #2. After this transfer, the corresponding block in cache #1 will be set to the I state and the corresponding block in cache #2 becomes the M state.
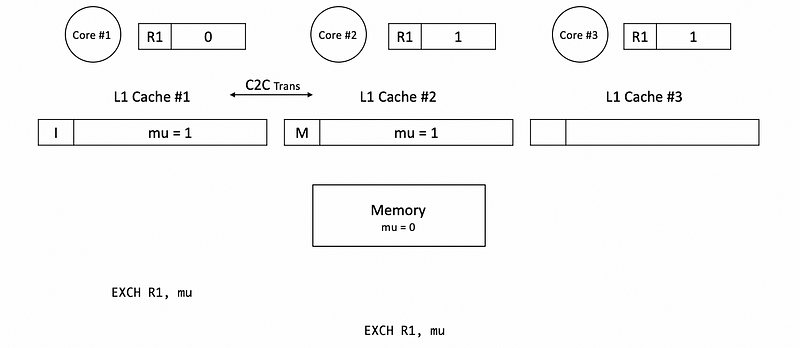
Suppose core #3 then acquires the same mutex mu and then it can block similar to core #2.
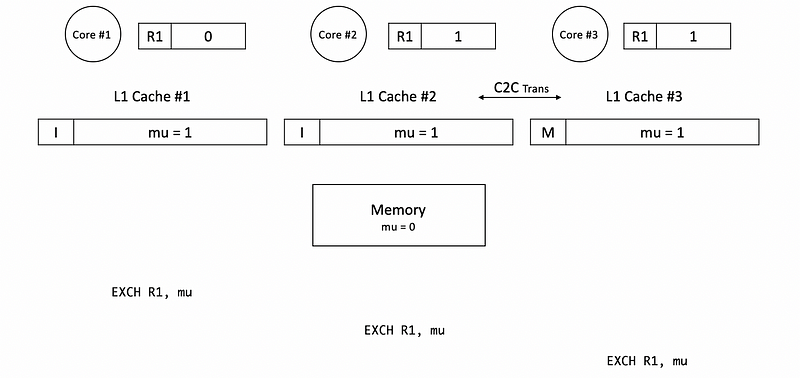
As long as the lock is still busy, core #2 and core #3 will be spinning in the loop trying to acquire the mutex mu. So what will happen is that cache #2 to cache #3 transfers and cache #3 to cache #2 transfers are going to happen many many times. So finally, what we can view is an I-M state swap of these two blocks. Each time the state swaps, there will be communications on the shared bus and also we will spend a lot of power.
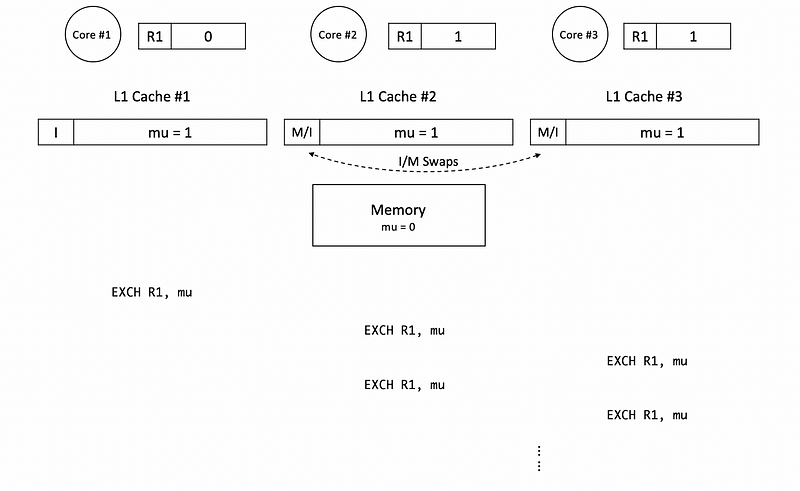
None of the swaps will successfully grab the block until the mutex mu is unlocked and the value of it is reset to 0. So at some point, core #2 and core #3 will have a race condition and one of them could acquire the lock successfully.
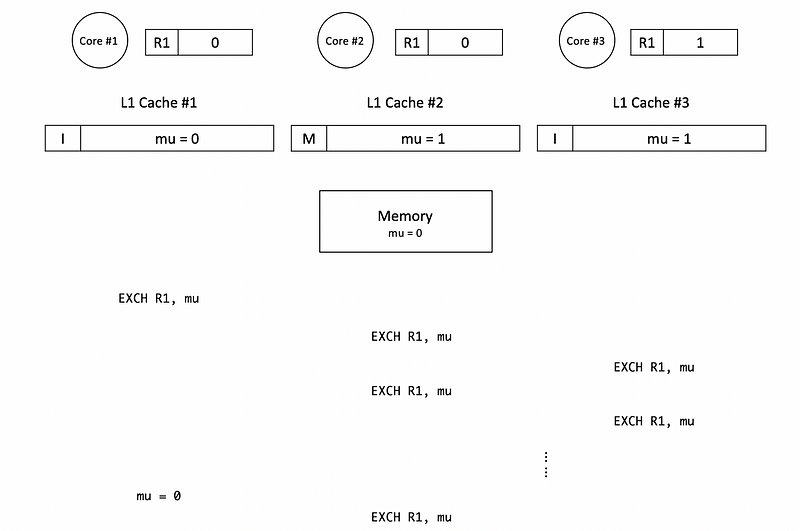
As we have discussed, the atomic read-write operations repeated even while waiting for the lock is inefficient in terms of energy and it actually slows down the thread that is in the critical section.
(12) Test-and-Atomic-Operation Lock
Because we have the inefficiency of repeated r/w operations with the mutex, we may want to have it improved. One way to make our lock more efficient is by an approach called test-and-atomic-operation. So before we have the EXCH ,
R1 = 1;
while (R1 == 1) {
while (mu == 1)
EXCH R1, mu;
}
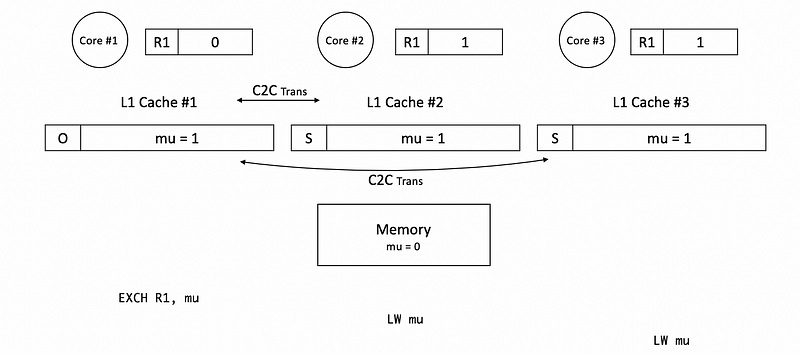
In the beginning, we still have cache #1 load from the memory, and the corresponding block is in the M state.
Because then core #2 and core #3 only read from the mu block in core #1 without writing, the block in core #1 will be in the O state. Both the blocks in cache #2 and cache #3 will be in the S state.
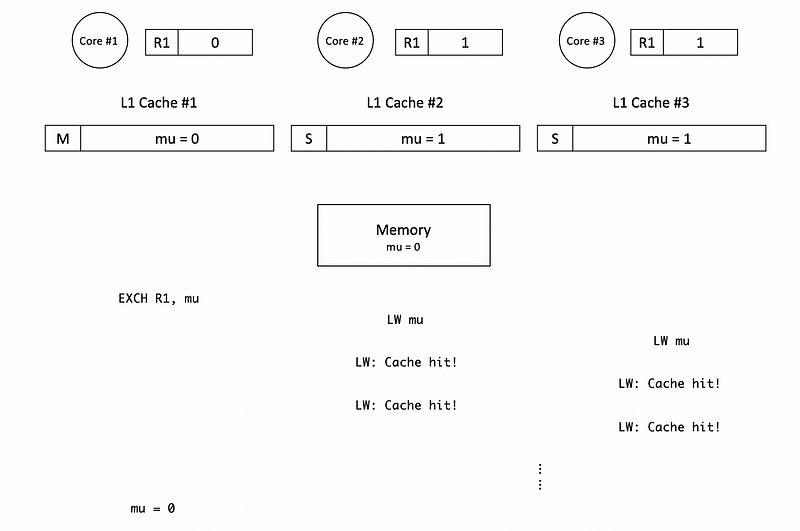
Then in the following loops, we will have cache hits. So we can directly read from the current cache instead of doing the I/M swaps between two caches. And this results in a better performance.
2. Barrier Synchronization
(1) The Definition of Barrier Synchronization
Another type of synchronization is called barrier synchronization. This often occurs when there is a parallel section where several threads are doing something independent of each other. For example, suppose each thread is adding up the numbers in its own part of a shared array, and eventually, we want to know the total sum. What needs to happen is that we need to make sure that everybody is finishing their own adding up and that’s why we need a barrier.
So the barrier is pretty much a global wait that ensures that all threads have entered the barrier before any of them can proceed the past barrier. The barrier synchronization ensures that all threads that need to arrive before any can leave the barrier.
A typical barrier implementation has two variables,
- A counter: counts how many threads arrived
- A flag: gets set when the counter reaches N
typedef struct barrier_t {
int count;
int flag;
} barrier_t;(2) Simple Barrier Implementation
Let’s see how can we implement a barrier in a thread,
barrier_t *barrier = (barrier_t *) malloc(sizeof(barrier_t));
lock(mu_barrier);
if (barrier->count == 0) barrier->flag = 0; // initialize flag
barrier->count ++; // count thread
unlock(mu_barrier);
if (barrier->count == NUM_THREADS) {
barrier->count = 0; // reinitialized the counter
barrier->flag = 1; // the flag implies we can continue
} else {
spin(barrier->flag != 1); // wait for threads until flag set
}Because the barrier can be accessed by all the other threads, when we update the value of the counter, we have to lock the barrier for synchronization purposes.
If the counter achieves the number of the threads NUM_THREADS we are waiting for, we have to reinitialize th counter to 0 for future use. And the flag should be set to 1, which shows all the other threads that are waiting to continue execution. However, if we have a counter smaller than the number of the threads, we have to wait for the other threads, and the current threads need to spin when the flag is not set.
(3) Simple Barrier Implementation: Exception Situation
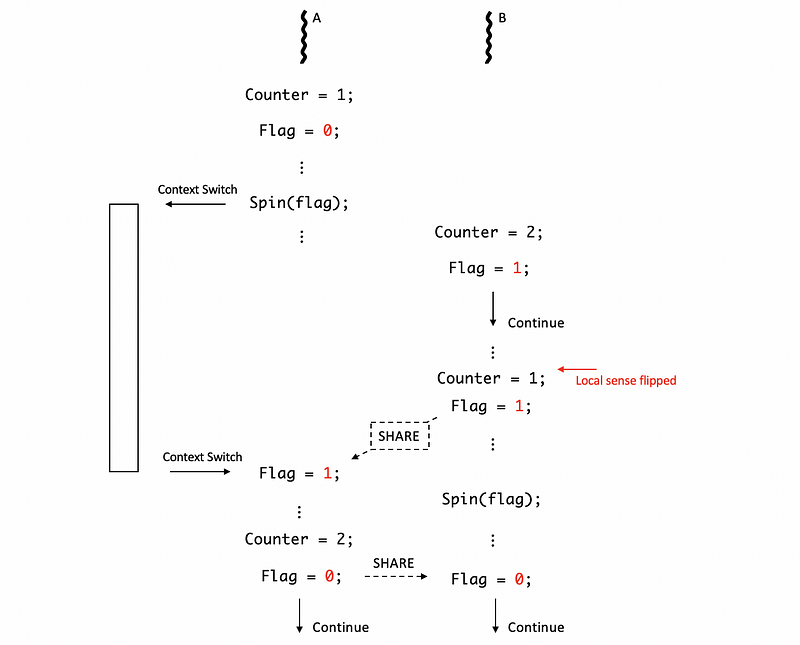
For the simple barrier we have discussed, there can be an exception. Let’s say we have two threads. Thread A will be executed first but it will spin and wait for the thread B. When thread B finishes, the flag will be set to 1 both of them can continue executing,
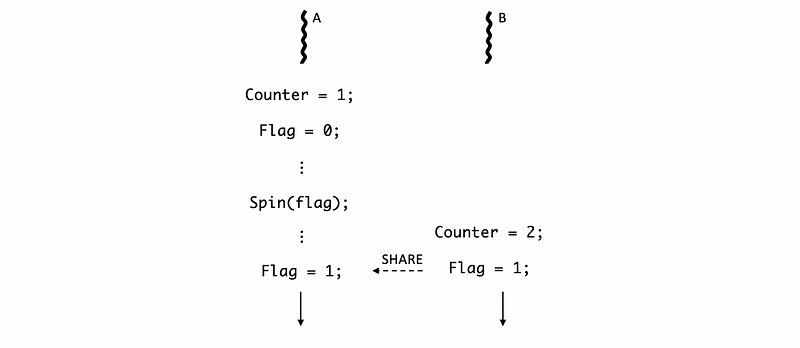
However, when thread A is spinning, we may probably context switch to some other programs and it may take a while for us to come back. So when thread B sets the flag to 1, thread A may not continue executing immediately. Therefore, the flag from B shared to A will be delayed.
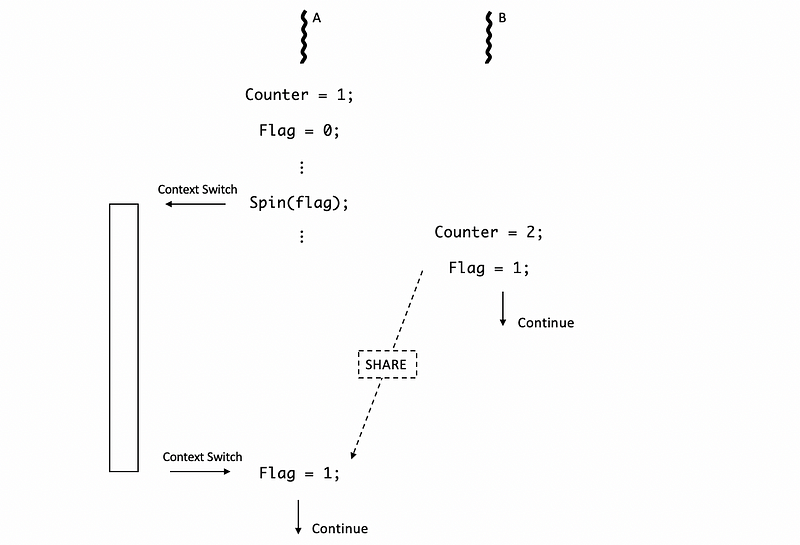
This will not be a problem until if in the delayed time, thread B keeps executing and reaches another new barrier. Then sadly, the flag will be cleared to 0 before thread A grab its value. When thread A switches back to the program, it will still get a flag of 0, and both of the threads are spinning now. Therefore, we have both of the threads waiting for each other but no one can continue, which is quite similar to a deadlock problem.

(4) Simple Barrier Exception Solution: Flippable Local Sense
So the last thing we are going to discuss is how we can reuse the barrier properly and this is done by assigning the flag with the flippable local sense. The exception is caused because we have changed the value in the barrier before another thread reads from it. Although we can maintain new barriers to avoid this problem, it is simpler if we can reuse the barriers.
For reusing the barrier in the proper way, we can assign the flag with a local sense variable instead of a constant. The modified code should be,
barrier_t *barrier = (barrier_t *) malloc(sizeof(barrier_t));
int localsense = 1;
localsense = !localsense;
lock(mu_barrier);
if (barrier->count == 0) barrier->flag = localsense;
barrier->count ++;
unlock(mu_barrier);
if (barrier->count == NUM_THREADS) {
barrier->count = 0;
barrier->flag = !localsense;
} else {
spin(barrier->flag != localsense);
}Initially, the localsense is set to 0 in the first barrier, and this means that 0 means we have to wait for the other threads, while 1 means that we can continue executing. After passing the first barrier, the localsense will be flipped to 1, and this means that 1 means we have to wait for the other threads, while 0 means that we can continue executing.
Therefore, thread A can still get a flag of 1 from B even if B reuses the barrier,