High-Performance Computer Architecture 33 | Many Core Challenges and Solutions
High-Performance Computer Architecture 33 | Many Core Challenges and Solutions
- Many Cores
(1) Many-Core Challenges
In this part, we are going to talk about implementing a multi-core system. When it comes to the situation that we have more than 1 core because we need to maintain coherence between more cores, the coherence traffic increases. Therefore, we will meet the following challenges,
- Bus Bottleneck: When we have more coherence traffic on the bus, the bus only allows us to do one request at a time. Then the bus will become a bottleneck.
- Off-Chip Traffic Bottleneck: when we have more cores, we also have more off-chip traffic (i.e. memory traffic). Therefore, we need to have more on-chip caches. Commonly if we have 4 cores, we have 4 L1 caches and 4 L2 caches. So that even if we have more cores, each core will have the same misses as the unicore. As a result, there will be higher memory traffic and the off-chip traffic now becomes a bottleneck.
- Over Large Coherence Directory: Because we have an on-chip network that is no longer a bus, we need directory coherence. But a traditional directory has one entry for each possible memory block, and the memory can be many gigabytes in size, which may result in billions of directory entries that will not fit on the chip.
- Power Budget for Cores: as the number of cores goes up, the power we can spend in each core goes down. This will result in a lower frequency of the core and each core will be much slower.
- OS Confusion: we will have all of these brings to the OS, which has to deal with multithreading, with one core for several threads, with one chip supporting many cores. So the OS can actually supports many threads. However, if the threads we are executing just use the first core of the system and it can be improved if we splite these threads to other cores, how can the OS figure that out?
2. Challenge 1: Bus bottleneck
(1) Bus Vs. Network
The simple idea is that all the cores will communicate the coherence information through a single shared bus, but we have discussed that there will be a bottleneck of the performance.

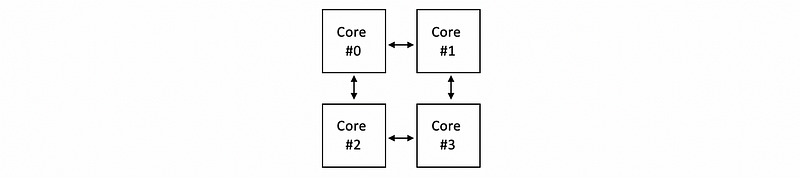
A better idea is that we can use a network to communicate between different cores. This kind of on-chip network used to connect different cores is called a mesh. Suppose we have a 4-core system, and what we have is these cores are individually connected as follows,
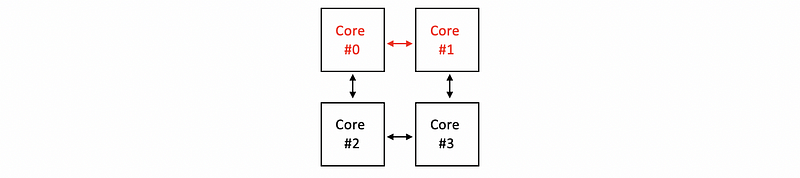
So when we want to maintain coherence between core #0 and core #1, we can directly communicate with the individual link between them,
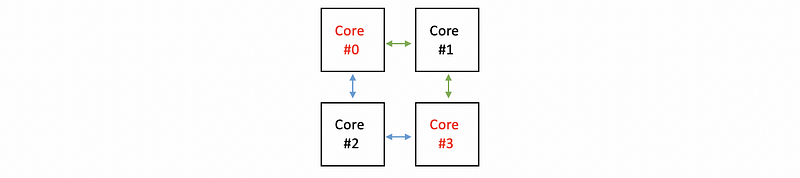
If we want to maintain coherence between core #0 and core #3, we can not send the message directly. But we can have two paths to send the message, via core #1 or via core #2,
We can even have a larger mesh with 16 cores and we will have more individual links between the cores. Therefore, we are going to have a higher throughput compared with only one shared bus. For example,
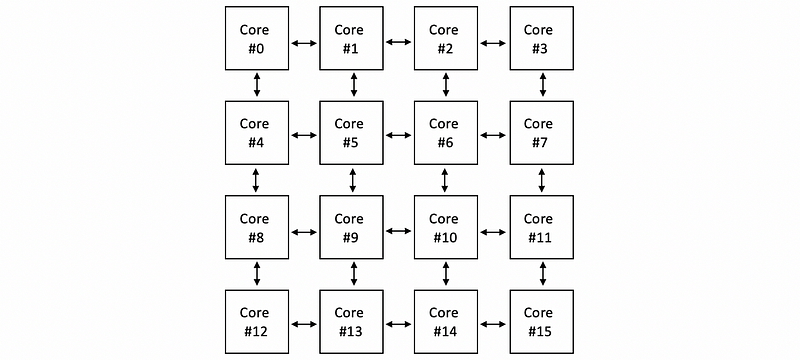
(2) Mesh Network: An Example
Now let’s see an example about the speedup of using a mesh. Suppose we have 4 cores, and each core sends an equal amount of messages. And the messages sent by each core are round-robin, which means that the messages from one core are equally send to other cores. Suppose each core sends 10 million messages per second and the bus and each link can support 20 million messages per second.
Then let’s start from core #0 in a mesh. Suppose core #0 is sending all the messages equally to the other three cores. Because core #1 and core #2 are neighborhoods for core #0, it will send all the information directly through the individual link between each pair of them, with the 1/3 amount of messages. However, for core #3, because we have two paths to send to this core, then each of the paths will send 1/6 amount of messages.
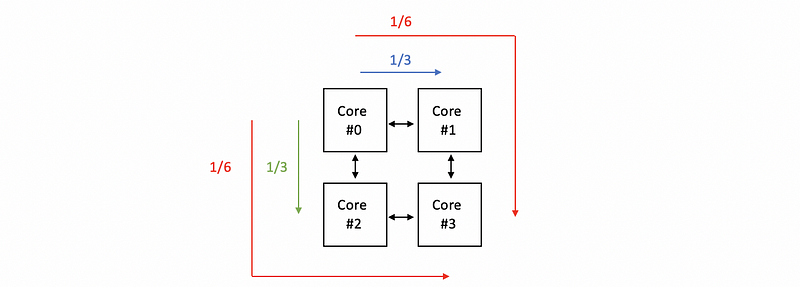
Then, the data transfers through the path sent by core #1 should be,
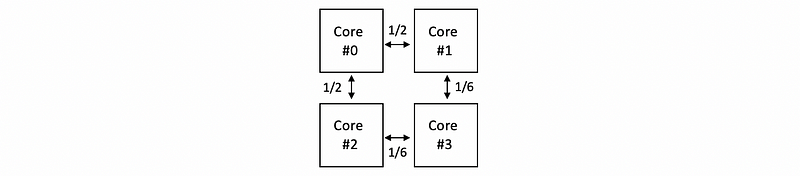
Then let’s continue this process for the other three cores and finally, we can get the total data transferred through each link is,
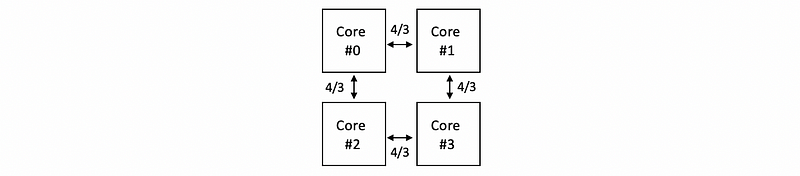
We can multiple 4/3 with the amount of data send by each core per second and then we can know that there will be 13.3 million messages transfer on each link per second. This value is smaller than the bandwidth of each link, which is supposed to be 20 million messages per second. So the cores keep sending messages without waiting.
However, when we have a shared bus, we can only have 2 cores working at a time because of the bus bottleneck. Therefore, we can finally know that the speedup in this case of mesh to the bus is 2.
3. Challenge 2: Off-Chip Traffic Bottleneck
(1) Shared Last Level Cache Problem
Because we have a bottleneck of the off-chip traffic, we need to reduce the number of access requests to the memory. The simple way to achieve that is by sharing a big last level cache (LLC), which in most of today’s modern processors is the L3 cache so that all the cores go to that cache finally.
But there is a problem to have one huge LLC like this. Such a large cache would be slow, and if it is really one single cache, it will only have one entry point where we enter the address and expect the data out. Because this one entry point is responsible for all the cache misses from all the cores, it turns out to be a bottleneck.
(2) Distributed LLC
The solution to this problem is that we can have a distributed LLCs that can have more than one entry point. But the main idea is that all of these distributed LLCs will be logically one single cache, which means that there will be no duplicate blocks in them.
However, the distributed LLC is sliced up so that each tile gets part of this cache. So now, on the chip of each core, we will the core, the L1 cache, the L2 cache, and a slice of the L3 cache,
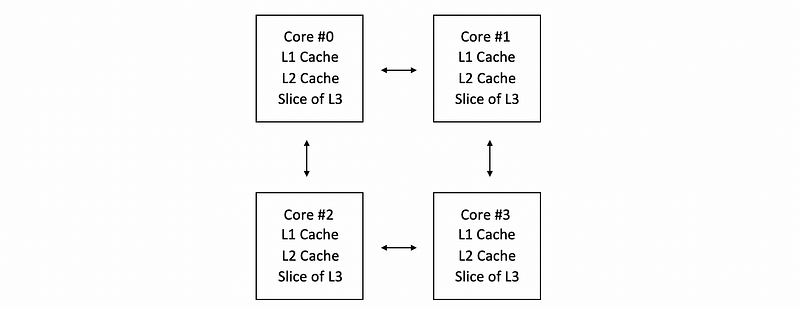
Now the problem is that how can we find the block we need because the L3 is distributed in each core? There are several solutions,
- Round-robin by Cache Index: the simplest idea is that we can simply spread the data to all the cores by the index. This is called a round-robin method by cache index. However, this method is not good for the locality. This is because a core is just as likely to access something that is in the opposite corner of the chip as it is to access its own L3 cache slice.
- Round-robin by Page Number: However, we can also spread the data by its page number. Then all the blocks that belong to the same page number will end up in the same slice. This helps because the OS can now map the pages to make accesses more local.
4. Challenge 3: Over Large Coherence Directory
(1) Directory Slicing
The directory can be too large because the directory has entries for every memory block. Because the directory is too large, the on-chip directory is also sliced and distributed to each core, and the directory is sliced the same as the LLC.
(2) Partial Directory
In fact, we can also realize that entries that are not on the last level cache or in any caches on chip will not be shared by any caches, so we don’t really have to maintain that information.
Therefore, we can maintain a directory that is called a partial directory that will not have every memory block. Instead, the partial directory will have a limited number of entries and then we allocate an entry in this limited directory only for such blocks that have at least one presence bit in one of the private caches.
When the partial directory runs out of entries, we can simply replace an existing entry possibly by LRU or some other policies.
5. Challenge 4: Power Budget for Cores
(1) Performance of Power Budgets
Even if our program supports parallel execution in some parts, it may not benefit from adding more cores because each core slows down. For example, suppose we have a program that,
- 20% time supports 1-core parallelism
- 30% time supports 2-core parallelism
- 40% time supports 3-core parallelism
- 10% time supports 4-core parallelism
Let’s suppose we have 100 sec time of execution if we have a unicore system. Then, how long will we spend executing this program if we have 2 or 4 cores?
When we have two cores, the frequency will be 79% (i.e. 3√0.5 = 0.79) of the unicore system. And if we have 4 cores, the frequency will be 63% (i.e. 3√0.25 = 0.63) of the unicore system.
Regardless of the reduction of the frequency, the execution time we will have for a 2-core system will be 60 s (i.e. [20% + 80%/2]*100 = 60), and the execution time of a 4-core system will be 50.8 s (i.e. [20% + 30%/2 + 40%/3 + 10%/4]*100 = 50.8).
So finally, take the frequency into consideration, we will have the actual execution time for a 2-core system is 76 s (i.e. 60/0.79 = 76), and the actual execution time for a 4-core system is 81 s (i.e. 50.8/0.63 = 81).
Therefore, we can find out that even we can benefit from the parallelism of cores, the power reduction for the added cores can make the performance worse.
(2) Boost Frequency
The idea of dealing with this power budget problem is quite simple. When we don’t need core parallelism, it can be a waste if we still support the unused cores. So basically, what are we going to do is that, when there is no parallelism available, we boost the frequency of one or two active cores so that they get the full power budget of the chip.
Examples of this solution are Intel’s Core i7–4702 MQ processor (for the laptop) released in Q2, 2013, and Intel’s Core i7–4771 processor released in Q3, 2013.
6. Challenge 5: OS Confusion
Actually, most of the modern OS’s today will figure out which core to run the thread to obtain the best performance, but this is beyond not scope of this series. What you have to keep in mind is that the OS implementations should also be aware and responsible for figure out which thread to put on which core in order to achieve the best performance.