Intro to Machine Learning 3 | Naive Bayes
Intro to Machine Learning 3 | Naive Bayes

- Spam-Ham Classification
Before we begin, let’s see our basic example for this model. Suppose we have tons of emails and we have already known that 75% of them are hams and 25% of them are spam.
If we randomly pick one email from our mailbox, can we know if this email is spam or ham?
2. Maximum A Priori Classifier
Let’s suppose we do not have any more information about the email we have picked up, and the only information we know is the prior probability.
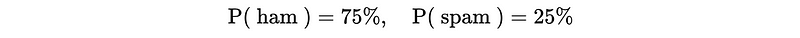
So the a priori classifier should be,
- Predict Ham if,
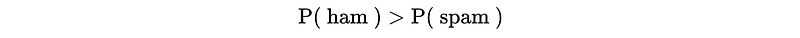
- Predict Spam if,
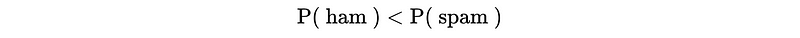
This is also,
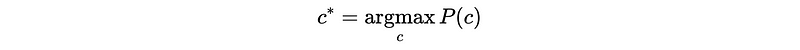
3. Maximum Likelihood (MLE) Classifier
Let’s suppose we do have some extra information about the email because we know some words in that email. Suppose the words are,
Viagra sale
So the likelihood classifier based on this information should be,
- Predict Ham if,
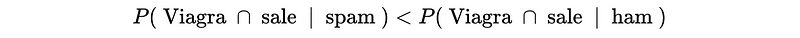
- Predict Spam if,
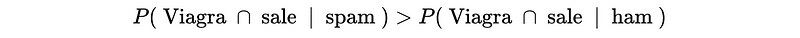
This is also,

Although this model works well, it doesn’t take into the knowledge of the a priori probability.
4. Maximum A Posteriori (MAP) Classifier
If we want to leverage the a priori probability to our classifier, we may need to use the maximum a posteriori classifier. By Bayes’ Theorem, the a posteriori probability is defined by,
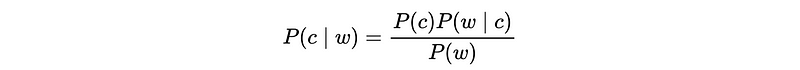
So for this classifier, we would
- Predict Ham if,
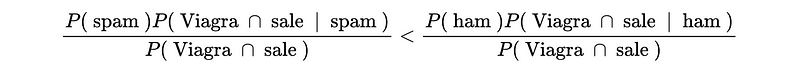
- Predict Spam if,
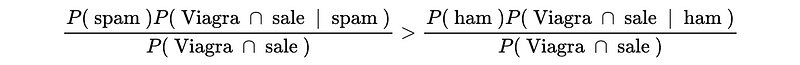
Because the denominators are just the same, we can cancel them out directly. So we will,
- Predict Ham if,
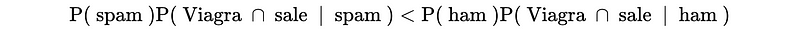
- Predict Spam if,
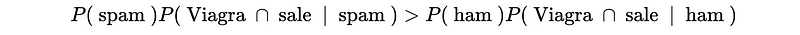
This is also,
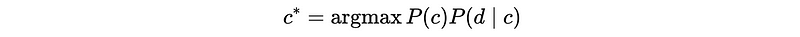
5. Naive Assumption
The naive assumption means conditional independence for all the words. This is applied because we don’t want to exhaust all the combinations of words in that document.
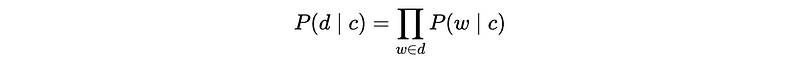
For example, we can have,
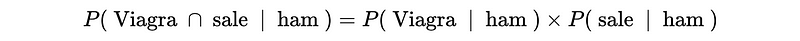
So the maximum a posteriori (MAP) classifier could then be,
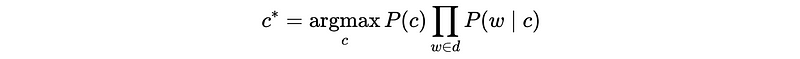
6. Fixed-Length Word-Count Vector
Note that in the last classifier, we have to construct a different classifier for each document, this is because of the product of word likelihoods in each document. Rather than arbitrary-length word vectors for each document d, it’s much easier to use fixed-length vectors of size |V| with all the words across the documents. So the classifier becomes,
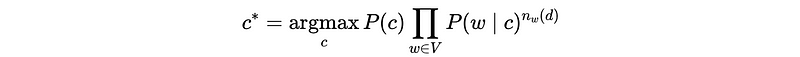
Here we have the function n_w(d) depending on d, and this means how many times the word w appears in document d.
7. Estimating Likelihood
- For long documents
The likelihood P(w|c) can be estimated by the number of times w appears in all documents from class c divided by the total number of words (including repeats) in all documents from class c.
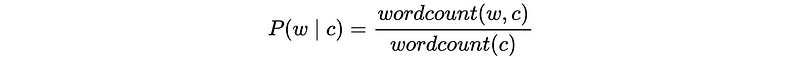
- For short documents (like tweets)
The likelihood P(w|c) can be estimated by the number of documents with w in class c divided by the number of docs in c.

8. Laplace Smoothing for 0 Likelihoods
Because we can have a product shrinking to 0 if there is at least one word in the vocabulary that doesn’t appear in the document, which also means at least one likelihood would be 0. To deal with this problem, we have to apply Laplace Smoothing (aka. additive smoothing) technique to the likelihoods.
The Laplace smoothing is defined by,
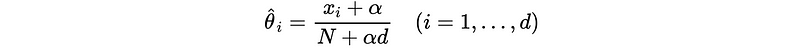
Leverage this to our likelihood,
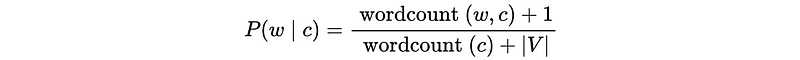
9. Unknown Word Problem
Now we have one remaining problem. Suppose we would like to predict the class of a document and that document has some words that never exist in the vocabulary (i.e. “unknown” words). The solution is that we can map all unknown w to a wildcard word in V so then wordcount(unknown, c) = 0 is ok but |V| is 1 word longer.
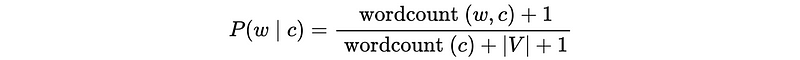
So the likelihood for an unknown word should be,
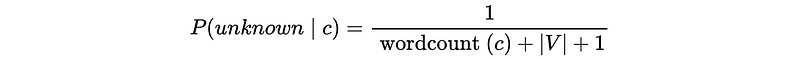
Also, for a word that exists in the vocabulary but doesn’t exist in the document, the likelihood should also be,

10. Floating Point Underflow Problem
Let’s imagine a situation when we have 30,000 words across documents in class c, and the vocabulary length is 1,200. Then the likelihood for a word exists in the vocabulary but doesn’t exist in the document or an unknown word should be,
p(w|c) = 1 / (30000 + 1200 + 1) = 0.000033
For any specific document, we must have this situation several times and the final product will be too small for us to compare (because the computer can only accept a certain range of precision). In order to avoid these vanishing floating-point values from the product, commonly we will take the log-likelihood method. Then the classifier becomes,
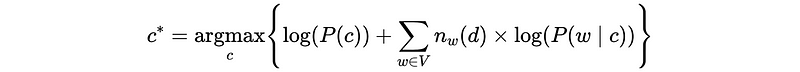
This is called the Multinomial Naive Bayes classifier.
11. Categorical Naive Bayes Classifier
Now that we have completed the discussion of the spam-ham classification example, let’s see a more generalized version of the Naive Bayes Classifier.
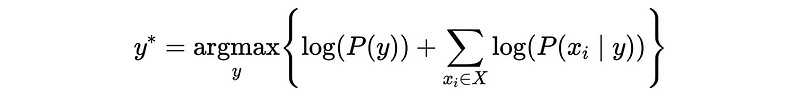
Let’s see an example. Suppose we have the label = {Apple, Banana, Strawberry}, Color = {Red, Green, Yellow}, Weight = {> 20g, < 20g}. Suppose we have the following data set,
Label Color Weight
---------- ----------- ------------
Banana Yellow >20g
Banana Green >20g
Banana Yellow >20g
Banana Yellow >20g
Banana Yellow >20g
Apple Red >20g
Apple Green >20g
Apple Green >20g
Apple Red >20g
Strawberry Red <20g
Strawberry Red <20g
Strawberry Red <20g
Strawberry Red <20g
Based on this dataset, let’s predict the class of the following fruits by Naive Bayes,
Color Weight
---------- ------------
Yellow <20g
Green <20g
Let’s first calculate the parameters,
P(Banana) = 5/13
P(Apple) = 4/13
P(Strawberry) = 4/13
P(Green|Banana) = 1/5
P(Yellow|Banana) = 4/5
P(Green|Apple) = 1/2
P(Red|Apple) = 1/2
P(Red|Strawberry) = 1
P(>20|Banana) = 1
P(>20|Apple) = 1
P(<20|Strawberry) = 1
Otherwise,
P(x|y) = 0
By Laplace smoothing,
P(Green|Banana) = 2/8 = 1/4
P(Yellow|Banana) = 5/8
P(Red|Banana) = 1/8
P(Green|Apple) = 3/7
P(Yellow|Apple) = 1/7
P(Red|Apple) = 3/7
P(Green|Strawberry) = 1/7
P(Yellow|Strawberry) = 1/7
P(Red|Strawberry) = 5/7
P(>20|Banana) = 6/7
P(<20|Banana) = 1/7
P(>20|Apple) = 5/6
P(<20|Apple) = 1/6
P(>20|Strawberry) = 1/6
P(<20|Strawberry) = 5/6
For case #1, it will predict Strawberry because
y = Banana :
log(P(Banana))+log(P(Yellow|Banana))+log(P(<20|Banana)) = -3.37
y = Apple :
log(P(Apple))+log(P(Yellow|Apple))+log(P(<20|Apple)) = -4.92
y = Strawberry :
log(P(Strawberry))+log(P(Yellow|Strawberry))+log(P(<20|Strawberry)) = -3.31
For case #2, it will predict Strawberry because
y = Banana :
log(P(Banana))+log(P(Green|Banana))+log(P(<20|Banana)) = -4.29
y = Apple :
log(P(Apple))+log(P(Green|Apple))+log(P(<20|Apple)) = -3.82
y = Strawberry :
log(P(Strawberry))+log(P(Green|Strawberry))+log(P(<20|Strawberry)) = -3.31
Therefore, based on the given dataset, we can have,
Color Weight Pred
---------- ------------ ----------
Yellow <20g Strawberry
Green <20g Strawberry
12. Categorical Naive Bayes Classifier in Python
Now, let’s repeat our result in of Naive Bayes classifier CategoricalNB above in Python.
from sklearn.naive_bayes import CategoricalNB
# Our fruit data
X = [[1, 1],
[0, 1],
[1, 1],
[1, 1],
[1, 1],
[2, 1],
[0, 1],
[0, 1],
[2, 1],
[2, 0],
[2, 0],
[2, 0],
[2, 0]]
y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2]
clf = CategoricalNB()
clf.fit(X, y)
# predict [Yellow, <20g] and [green, <20g]
print(clf.predict([[1, 0], [0, 0]]))
The output should be,
[2 2] # category 2 means Strawberry
We can also check the estimate parameters by clf.coef_,
import math
for i in clf.coef_[0]:
print()
for j in i:
print(math.exp(j))
print("------------------")for i in clf.coef_[1]:
print()
for j in i:
print(math.exp(j))
The output should be,
0.25000000000000006
0.625
0.12500000000000003
0.42857142857142866
0.14285714285714288
0.42857142857142866
0.14285714285714288
0.14285714285714288
0.7142857142857143
------------------
0.14285714285714288
0.8571428571428572
0.16666666666666669
0.8333333333333333
0.8333333333333333
0.16666666666666669
This is exactly the same as the estimated likelihood after Laplace smoothing we have calculated.
However, for the word counts for text classification (e.g. spam or ham example) as we discussed at the beginning, it is better to use MultinomialNB by,
from sklearn.naive_bayes import MultinomialNB
CategoricalNB is more commonly used for classification with discrete features that are categorically distributed (e.g. the fruit example).