Intro to Machine Learning 7 | Introduction to Deep Learning
Intro to Machine Learning 7 | Introduction to Deep Learning

- Activation Functions
An activation function is a function used in artificial neural networks which outputs a small value for small inputs, and a larger value if its inputs exceed a threshold. If the inputs are large enough, the activation function fires, otherwise it does nothing. In other words, an activation function is like a gate that checks that an incoming value is greater than a critical number.
Some common non-linear activation functions are,
- Threshold step function
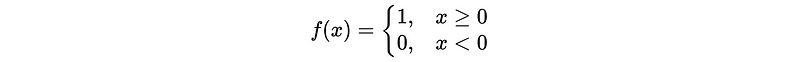
- Rectified linear unit (ReLU)
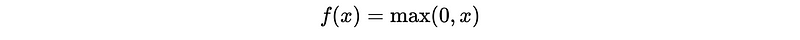
- Parametric rectified linear unit (PReLU)
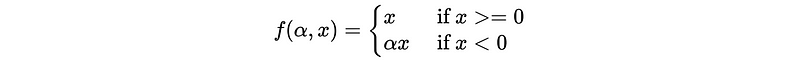
- Sigmoid function
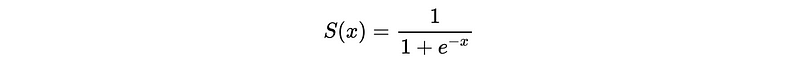
- Hyperbolic tangent (tanh)
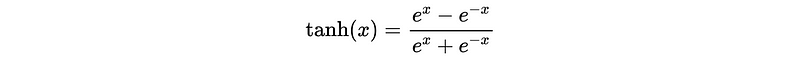
- Softmax
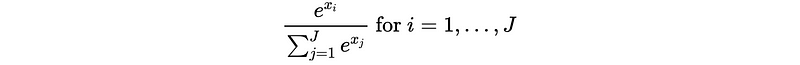
2. Epoch, Batch, Minibatch, Iterations
epoch: An epoch means passing the entire X training matrix in the neural network once for gradient descent.nepochsmeans the total number of for gradient decent. Each update of the model parameters occurs after considering all training instances or after each epoch.batch: Sometimes we have a large scale of data and it can not be passed to the network in a single batch. Therefore, we split this training data in chunks and then pass them to the network.batch_sizeis the data size of each batch andnbatchesequals toentire X size / batch size.mini-batch: Note thatmini-batchis different frombatch. The former one trains the neural network on the entire X training matrix, while the latter trains the neural network on different small data chunks of X separately. The mini-batch method takes the average of computed gradients across all the batches and then update the weight in an epoch. Next, we shuffle the batches, and iterate until convergence. The gradient descent based on mini-batch is also called mini-batch gradient descent, or more commonly stochastic gradient descent (SGD). It is called stochastic because a) Randomness; b) Imprecision introduced by computation of gradients on a subset of the training data.iteration: Iterations are the number of batches or mini-batches we have to complete training in one epoch. The total iterations means the number of iterations in one epoch times the number of epoches.
3. PyTorch Basics
(1) PyTorch For Linear Regression
- Import PyTorch
import torch
- Set features and labels as tensors
n = len(df)
m = # of features
X = torch.tensor(df.x).float().reshape(n, m)
y = torch.tensor(df.y).float().reshape(n, 1)
- Create a random tensor of
dim=(1,1)
torch.randn(1, 1)
- Create a randomly started parameter requires autograd of
dim=(1,1)
torch.randn(1, 1, requires_grad=True)
- Create a linear model, where
mandbare randomly started parameters,
y_pred = m * X + b
- Linear loss function based on RMSE
loss = torch.mean((y_pred - y)**2)
- Computes the gradient of
losswith respect to all variables withrequires_grad=True.
loss.backward()
- The gradient of loss with respect to parameter
mafter callingbackward
m.grad
- Reset the gradient of loss with respect to parameter
mto 0
m.grad.zero_()
- Inbuilt Adam optimizer for all the model parameters with
requires_grad=True
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
- Zero out all the model parameters with
requires_grad=True
optimizer.zero_grad()
- Take one step in gradient descent based on the gradient of loss with respect to parameters
optimizer.step()
(2) PyTorch For Frank Rosenblatt Perceptron
- PyTorch in-built linear model
nn.Linear(1, 1)
- PyTorch in-built ReLU
nn.ReLU()
- PyTorch in-built Sigmoid
nn.Sigmoid()
- PyTorch in-built function used to glue models together
nn.Sequential()
- Frank Rosenblatt Perceptron (similar to Logistic Regression for statistics, see a difference here)
model = nn.Sequential(
nn.Linear(100, 1),
nn.Sigmoid()
)
- Multi-neuron Frank Rosenblatt Perceptron with a 1000-neuron layer
model = nn.Sequential(
nn.Linear(100, 1000), # hidden 1000-neuron layer
nn.Sigmoid(), # activation function
nn.Linear(1000, 1) # output layer
)
(3) PyTorch For Classification
- Regressors typically use mean squared error, but classifiers typically used log loss (cross-entropy loss).
import torch.nn.functional as F
loss = F.binary_cross_entropy(y_pred, y)
loss = F.cross_entropy(y_pred, y)
- Note that the output layer for classification should be a Sigmoid activation function or a Softmax activation function or something like that
nn.Sigmoid() # for binary class classification
nn.Softmax(dim=1) # for multiclass classification
(4) Running PyTorch on GPU
- Find if we have a CUDA device (i.e. GPU from Nvidia), if we don’t have it, just name it as
cpu
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')- Move the tensors with data to the GPU/CPU device
X = torch.tensor(X).float().to(device)
y = torch.tensor(y).to(device)
- Also, make sure the model runs on GPU
model = model.to(device)
4. Validation for Deep Learning Models
Deep learning models often have so many parameters that we can drive training loss to zero, but unfortunately, the validation loss usually grows as the model overfits. For example, we are expected to see the following plots when training,
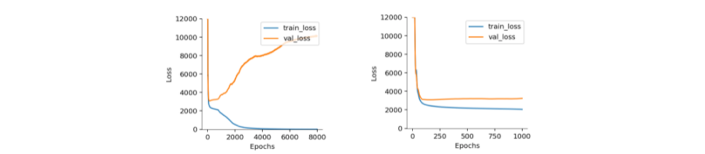
One way to reduce overfitting is to use weight decay, which is actually the same as the L2 regularization we have discussed before. Without constraints, model parameters can get very large, which typically leads to a lack of generality. Using the Adam optimizer, we turn on weight decay with parameter weight_decay, but otherwise, the training loop is the same. For example,
optimizer = torch.optim.Adam(model.parameters(),
lr=learning_rate,
weight_decay=weight_decay)
5. Deep Learning Frequently Asked Questions
- Why do we have to normalize before we train a neural network?
Or it would be hard to find a suitable learning rate for all the parameters.
- How to prevent overfitting a neural network?
Introduce weight decay to the optimizer or simply find the nepochs with the lowest validation loss.
- Why does the training loss sometimes pop up and then go back down? Why is it not monotonically decreasing?
It is likely the learning rate is too high and therefore, as we approach the minimum of the lost function, our steps are too big. We are jumping back and forth across the location of the minimum in parameter space.
- What happens if we set a small learning rate but keep the same number of epochs?
The training loss continues to decrease but it will stop at a relatively high training loss. The training loss stays at a high level because we don’t have enough iterations for it to converge.
- What happens if we set a small learning rate and also increase the number of epochs?
The training will be very slow because we have more iterations and a smaller learning rate. The training loss continues to decrease but much lower than before and stops long before reaching a loss very near zero.
- How do we know what the right value of the weight decay is for our optimizer?
Typically we try a variety of weight decay values and then see which one gives us the best validation error.