Operating System 3 | Process and Process Management, Process Control Block, Process Lifecycle…
Operating System 3 | Process and Process Management, Process Control Block, Process Lifecycle, Process Scheduling, and Process Communication

- Process
(1) The Definition of Applications
The application is a program on disk, in flash memory, or even in the cloud. But it is not executing and it can be treated as a static entity.
(2) The Definition of Process
One of the most important abstractions of the operating system is a process. In the simplest terms, a process is an instance of an executing program. Sometimes it makes sense to use a task or job to represent a process. We have talked that the application is a static entity, while, once an application is launched, it is loaded into the memory and it starts executing, and then it becomes a process. So in conclusion, the process is an active entity.
A process has its state of execution which described with the program counter (PC), the stack pointer (SP), and all this information is used by the operating system to decide how to schedule the process, how to swap between multiple processes, and for other management of tasks.
A process also has its parts or as we called the temporary holding area. In order to execute, the process needs some data and some states in the register.
A processor also requires some special hardware, like I/O devices, disks, or network devices.
(3) Program Vs. Process
If the same program (static) is launched more than once, then multiple processes (active) will be created. These processes will be executing the same program, but they are very likely to have very different states.
(4) The Definition of Address Space
A process encapsulates all of the data for running applications, and this includes the code, the data, the variables, etc. Every single element of the process state has to be uniquely identified by its address. So an OS abstraction used to encapsulate all of the process states is address space.
The address space is defined by a range of address from V0 to Vmax and different types of process states will appear in different regions in this address space.
(5) Different Types of States
Static State: available when the process first loads
- Text
- Data
Heap: heap is an area of dynamically-allocated memory. the heap doesn’t have to be a continuous portion of the address space (right after the static state). during the execution, the process dynamically
- creates some state
- allocates memory
- store the temporary results
- reads data from files
- etc.
Stack: a dynamic part of the address space and it grows and shrinks during the execution with a last-in, first-out (LIFO) order. The stack can be used to store and retrieve the state of a process
- restore states
- swap states
(6) Virtual Address Vs. Physical Address
Recall we have said that the potential address of the address space (V0 to Vmax) represents the maximum size of the process address space. We call these addresses virtual addresses because the process uses these addresses to reference some of its states and these addresses don’t have to correspond to the actual locations in the physical memory (physical addresses, DRAM).
Physical addressing means that your program actually knows the real layout of RAM. With virtual addressing, all application memory accesses go to a page table, which then maps from the virtual to the physical address. So every application has its own “private” address space, and no program can read or write to another program’s memory. This is called segmentation.
— — Borealid, from StackOverflow
However, it is necessary for the progress to access physical addresses or it will not find the exact space of the data in the memory. Actually, the memory management hardware and the operating system components responsible for memory management by mapping between each virtual address and each physical address. This separation between application and physical memory will allow us to maintain physical memory management simple and not in any way dictated by the data layout that all processes are executing.
First of all, the process requests some memory to be allocated by the operating system to it at a particular virtual address. Then the address of the physical memory that the operating system actually allocates will be mapped to the virtual address and this map will be stored as an entry in the page table. When the process tries to access the virtual address, the operating system finds the physical address according to the mapping rules in the page table. Therefore, even the processes have the exact same virtual address space, they can work with no conflicts.
(7) Concerns About Insufficient Memory
It seems possible that if we have the same virtual space for all the processes, our memory can become full easily. For example, let’s suppose we have to execute a program 4 times and this program has a virtual space of 4GB. However, our memory has 8GB in total and for some worst cases, the 4 processes will request memory for more than 8GB (max = 4*4 = 16GB), and then it is possible for the memory to be full.
However, the modern operating system will request some space on the disk to avoid this problem. When these data stored on the disk are needed, they will be reloaded to the memory.
2. Process Control Block
(1) The Definition of Program Counter
Before the execution of an application, its source code must be compiled in binary (assembly code). At any given time, the CPU needs to know where the process currently is in this binary sequence and it uses the program counter (PC), which is maintained in a register of the CPU while the program is executing.
(2) The Definition of Stack Pointer
Another piece of state that defines what a process is doing is the process stack and the top of this stack is determined by the stack pointer. A stack pointer is a small register on the CPU that stores the address of the last program request in a stack.
(3) The Definition of Process Control Block
To maintain all the useful information for every single process, the operating system uses a process control block (PCB) to store all the state information for a process. The process control block is a data structure that the operating system uses for maintaining every one of the processes. The PCB is created when the process is created and it also initialized at that time and certain fields are updated when the process states changes.
A process control block is likely to contain the following information,
- process number
- program counter
- registers (i.e. the stack pointer)
- memory limits: various memory mappings
- list of open files
- priority
- signal mask
- CPU scheduling information: how much time this process has executed in the CPU and how much time it should be allocated in the future
- etc.
(4) Interactions Between PCB and CPU
Now, let’s see how PCB interacts with the CPU. Suppose we only have two processes P1 and P2, and the CPU schedule is as follows. The green bar means that the corresponding process is executing, while the white bar means that it is an ideal process at the moment.

At the time T1, both of the processes P1 and P2 are created and initialized. Because CPU will execute P1 first so that the state of P1 is loaded to CPU and the state of P2 is saved. At the time T2, the CPU is going to switch the process from P1 to P2. So it saves the current CPU states to PCB_P1 in the memory and then restores the state of P2 from the PCB_P2 . Finally at the time T3, the CPU is going to switch the process from P2 to P1. So it saves the current CPU states to PCB_P2 in the memory and then restores the state of P1 from the PCB_P1 .
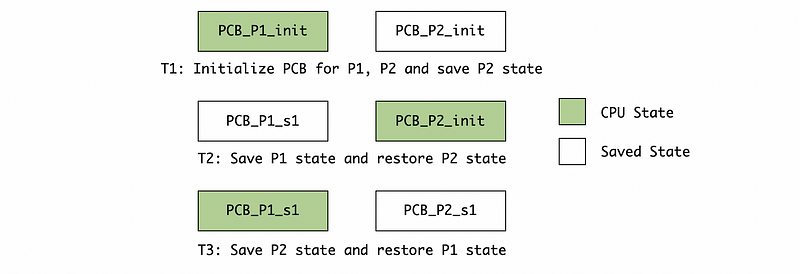
Note that the state in the PCB is updated while the processes switching. So we don’t have to update the state of the PCB whenever the PC counts or it will cost a lot for the L/W instructions. We are going to explain more about this in the following section.
(5) Context Switch
The context switch is a mechanism used by the operating system to switch the execution from the context of one process to the context of another process. This operation can be expensive because of the following two reasons,
- Direct Costs: the number of cycles that have to be executed to load/store all the values from the process control blocks to/from memory.
- Indirect Costs: when the process
P1is running on the CPU, lots of its data is going to be stored in the processor’s cache and this is called a hot cache. The cash is a place for the CPU to access some data (tens of instructions) and it is much faster than accessing the memory (hundreds of instructions). However, when the context switch happens, all of the data in the cache belonging toP1will be replaced to make room for the new data. So next time whenP1is scheduled to execute, its data can only be accessed from the memory and we call this situation a cache missing problem. And also, the cache now without the data of the process we want to execute is called a cold cache.
Therefore, it is significant for us to limit the frequency of the context switching.
3. Process Lifecycle
(1) Process Id
In most operating systems, the process id (or process identity or pid) is used to uniquely identify an active process.
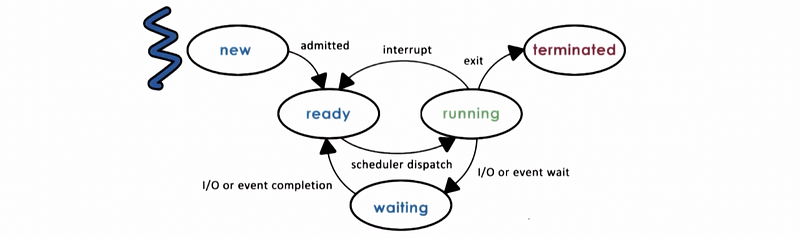
(2) Process States
As we have said, processes can be idle (ready) or running. These are two of the commonest states for any given process. When the process is running, it can be interrupted or context-switched and then become an idle process (also called the ready state). This is also called a ready state because it is ready to execute but it is not the current context that is running on the CPU. At some other moment, the scheduler will schedule this process again and then it will start executing on the CPU so it becomes a running state.
Moreover, there are some other states of the process that we have to know.
When the process is created initially, it enters the new state. Then the OS will perform admission control and it will determine if the process can be allocated and initialized. When it is at the ready state, it can be executed at any time if it is dispatched to the CPU. After the scheduler moves this process to the CPU, it then becomes the running state. From here, a number of things can happen,
- If the running state is interrupted by some other process, the OS will move the running state of the current process back to the ready state.
- If the running state is pending for some operations that take a long time like I/O or event (i.e. timer or keyboard), then the process enters the waiting state until these operations are finished.
- If the running state finishes all the operations of the program or encounters some kind of error, then it will exit. It will return the appropriate exit code and then the process is terminated.
(3) Process Creation
Actually, all the processes come from a single root process and they will have some of the relationships to one and another where the creating process is the parent and the created process is the child. You can imagine that because all the processes come from a single root process and all of them could have new children. Thus, the process is more like a tree for its data structure. This is called a process tree. We can view the current process tree by,
$ ps -e
Then you can find that we have many processes and the root for all of them is the process with pid = 1 and name launchd(For Mac OS), or name init (for UNIX-like), or name zygote (For Android OS). You can also find the process related only to the current terminal by,
$ ps -a
So how can a process create more processes? Well, the use of fork and exec provide a very simple way to create new processes. Both the fork and exec are system calls of the operating system and their meanings are,
forkwill create a copy of the current process as its child process. The values from the PCB of the current process will be copied. At that point, both the parent and the child will be continuing immediately after the fork because both of them have almost the same values in their process control block.execwill take the created PCB by fork and rewrite the value of it with some other programs. Thus a new program will be load and the child PCB will now be different from the parent PCB. The child process now contains the values from the new programs. A more accurate definition given by Yemaosen is that theexeccall is a way to replace the entire current process with a new program. It loads the program into the current process space and runs it from the entry point.
Now, let’s have a try. Let’s open two terminals and execute the command ps in one of these 2 terminals,
$ ps
The output should be as follows (note that the PID, TTY, and TIME can be different),
PID TTY TIME CMD
25867 ttys000 0:00.38 -bash
32580 ttys001 0:00.24 -bash
Now, let’s run the following command in another terminal (for me, pid = 32580),
$ cat
And from the first terminal, we now run,
$ ps
Then we can find a new process of cat ,
PID TTY TIME CMD
25867 ttys000 0:00.38 -bash
32580 ttys001 0:00.24 -bash
33681 ttys001 0:00.00 cat
This process is actually the child process (for me, pid = 33681) of the second process (for me, pid = 32580). Then we can use ^c to kill the process of 33681 . After killing this process, we can find out that there is no cat process.
$ ps
So what really happens? In fact, when we run the command cat , the terminal actually uses both the fork system call and the exec system call. The fork is called (shown in 1.) in the first place to create a copy of the process 32580 . Then the exec is called to replace the PCB of the process 33681 with the context of the command cat . After we killed the process 33681 by ^c, the CPU will restore the state of its parent process 32580. This is shown by the following diagram.
+------------+
| pid=32580 |
| bash |
| |
+------------+
|
| 1. calls fork
V
+------------+ +-----------+
| pid=32580 | forks | pid=33681 |
| bash | ----------> | bash |
| | | |
+------------+ +-----------+
| |
| waits for pid 33681 | 2. calls exec to run cat
| V
| +-----------+
| | pid=33681 |
| | cat |
| | |
V +-----------+
+------------+ |
| pid=32580 | | exits
| bash | <-----------------+
| |
+------------+
|
| continues
V4. CPU Scheduling
(1) The Definition of CPU Scheduler
The CPU scheduler is an operating system component that manages how processes use the CPU resources. A CPU scheduler defines which one of the currently ready processes will be dispatched to the CPU to start running, and how long it should run for.
(2) The Definition of the Ready Queue
At a time we may have several processes that are in the ready state. And the ready queue is defined as the combination of all of these ready processes.
(3) The Definition of Preemption
To act the role of the scheduler, the operating system must be able to preempt, which means to interrupt and save the context of the current process. This is called preemption.
(4) Steps of Scheduling
Step 1. Preemption: interrupt & save
Step 2. Schedule: by running some scheduling algorithms
Step 3. Dispatch: dispatch process & switch context
Because these steps can happen very frequently, we have to carefully design them in order to make them efficient.
(5) Scheduling Performance
Before we continue, we have to design a measurement for analyzing the performance of a scheduler. Suppose we define the processing time is Tp (this is also called the time slice) and the scheduling time is T_sched , then the useful CPU work can be defined as,
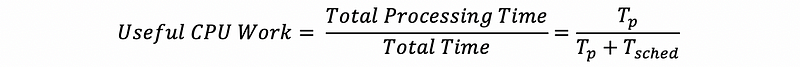
Note that there are also some other metrics that we can use to measure the performance of a scheduler and we are not going to focus on them now.
(6) Sources of the Ready Queue
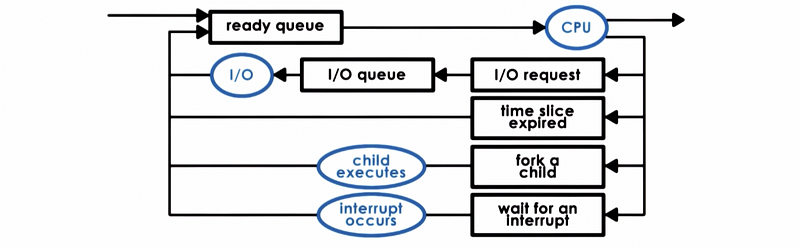
A process can make its way to the ready queue in a number of ways.
- A process that after the I/O event
- A process with its time slice expired
- A new process created via the
forkcall - A process after an interruption
5. Inter-Process Communication (IPC)
(1) IPC Mechanisms
To make better use of our operating system, we also have to communicate between different processes. Inter-process communications (IPC) mechanisms help to transfer data and information between address spaces of different processes, and they also have to maintain isolation and protection. The IPC mechanisms also need to provide flexibility and good performance for different processes.
(2) Message-Passing IPC
One mechanism that the operating system support is the message-passing IPC. The operating system establishes a communication channel like a shared buffer for instance. Then the processes communicate by one process writing or sending a message to this buffer and the other reading or receiving a message from this channel.
The advantage of this is that this IPC is controlled by the OS so the OS can manage the channel by the API. However, the downside is the overheads because every single piece of information has to be transferred between the user space and the kernel memory.
(3) Shared Memory IPC
The operating system establishes a shared memory channel and maps it into each process address space. Then each process is allowed to read and write from this shared memory as any other addresses in their virtual space.
The advantage of this is that the OS is out of the way so we don’t have to worry about the overheads. However, because the OS no longer works for controlling this IPC, we can not use any APIs provided by the OS. Sometimes we have to reimplement the code in order to use the shared memory in the correct way.