Operating System 5 | Thread Part 1, Mutual Exclusion and Condition Variable
Operating System 5 | Thread Part 1, Mutual Exclusion and Condition Variable

- Threads
(1) Recall: Process
In the previous section, we have talked about processes and process management and we have known that a process is represented with its address space and its execution context. The address space is defined by a range of virtual addresses and different types of process states. The execution contexts are also stored in the process control block (PCB) for all the state information (i.e. program counter or stack pointer) of a process.
(2) Process For Multi-core Systems
However, the processes that are represented in this way can only be executed at one CPU (one core) at a given time. If we want a process to be able to execute on multiple CPUs (modern CPUs have multi-core systems), that process has to have multiple execution contexts. Such execution contexts within a single process are so-called threads.
(3) Properties of Threads
- Threads are active entities because each thread executing a unit of work on behalf of a process.
- Threads can work simultaneously because we can execute many threads at the same time. Thus, in this case, we have to think about concurrency.
- Threads require some level of coordination. For coordination, we are mainly talking about coordinating access to the underlying platform resources like sharing I/O devices, CPU cores, memory, and all other system resources.
(4) Process Vs. Thread
A thread is the unit of execution within a process. A process can have anywhere from just one thread to many threads. When a process starts, it is assigned memory and resources. Each thread in the process shares that memory and resources.
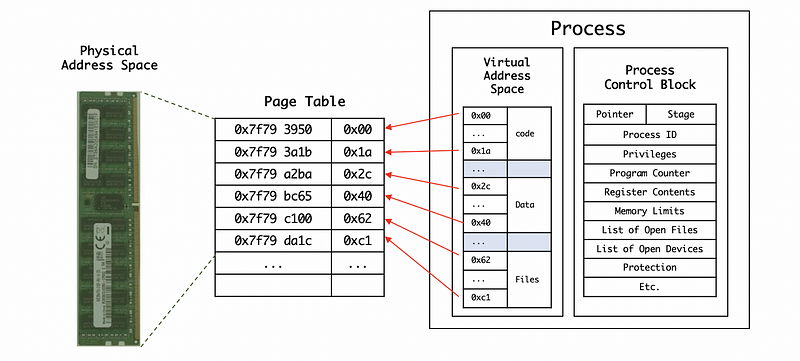
A single process is represented by its address space, and the address space will contain all the mappings of virtual to physical addresses for its code, its data, and its files. The process can also be represented by its execution context that contains the information about the values of the registers, the stack pointer, and etc. The operating system represents all this information in a process control block (PCB).
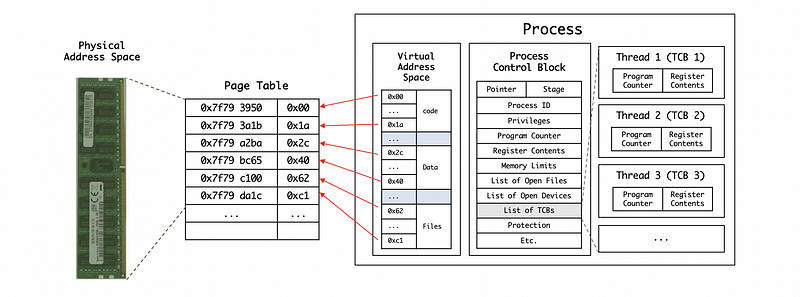
Threads represent multiple, independent execution contexts. They are part of the same virtual address space, which means that they will share all of the virtual addresses of a process. They will share all the codes, all the data, and all the files. However, they will also execute different instructions, access different portions of that address space, operate different portions of the input, and differ in other ways. So each thread will have a different program counter, stack pointer, stack, and thread-specific registers. The PCB that we use to store the information of the thread of a process is more complex because it has to contain all the information among all the threads with the list of thread control blocks (TCBs).
(5) Advantages of Using Threads
- Parallelization for Speedup
Suppose we have a 4-core CPU, and we also have a process that has 4 threads executing on this CPU. If these 4 threads have the same code but each of them has a different input, there can then be variations between the program and register contents for each of these threads.
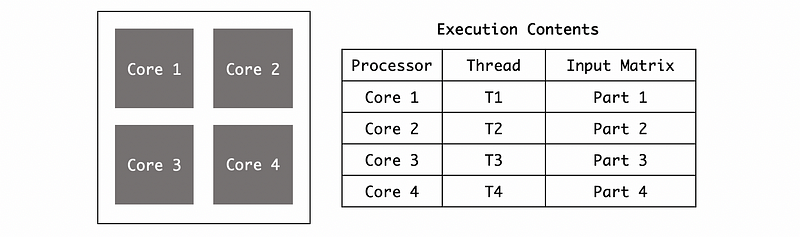
Compared with the situation that we only have 1 process when we can only run this process with the 4 inputs on a core one after one, we can run these 4 inputs simultaneously on the 4 cores. This is called parallelization can we can reduce our execution time of a program and finally achieves a speedup of performance.
- Specialization for Hot Cache
The operations executed by each thread on the CPU comes from the fact that the performance is dependent on how many states exist in the processor cache. If each of these threads running on a different processor (core) has access to its own processor cache, then the cache will be hot and this will improve the performance by reducing the W/R operations from the memory.
- Memory Efficiency
Some may have a question here. Why don’t we have 4 processes instead of 4 threads? The answer can be quite clear. If we have 4 threads of the same process, they can share the virtual address space (code, data, files). However, if we have 4 processes, each of them should have a virtual address space, which can be memory-consuming.
- Improve Cross-Threads Communication
Passing data or synchronization among different processes requires interprocess communication mechanisms that are costly. However, because all the threads share the same virtual address space, then it will not be as costly as inter-process communication.
(6) Context Switch for Threads
Now, let’s think about the context switch for threads. We have talked that the context switch happens when we want to move from one process to another. The current CPU state will be stored in the CPU and then we have to reload the data from the memory to cache. The process of changing from the cold cache to the hot cache can be quite time-consuming and it reduces the general performance.
For the context switch between threads of the same process, because these threads share the same virtual space, we don’t need to redo the mapping page from the virtual address space to the physical address space. So the context switch between threads can be much faster than the context switch between processes.
(7) Threads for a Single Processor
Suppose we have only one processor, could we improve the general performance of the CPU by threads? The answer is yes. In reality, the processors are not running all the time because sometimes we have to wait for the disks or some other devices. The time that the CPU is not working because it is waiting for some other devices is called idle time.
If we can have an idle time longer than two times the context switch time from one thread to the other (because we have to switch from one thread and then switch back), then we can improve the performance by using multiple threads on one processor.
2. Basic Thread Mechanisms
(1) Goals for Supporting Threads
- Design thread data structure
- Design mechanisms to create and manage threads
- Design mechanisms to coordinate and run concurrently
(2) Process Concurrency
Is it possible for two processes to access the same physical address? The answer is no. We have known that different processes have independent virtual spaces mapping to different physical address spaces. Because the operating system controls the mapping and the virtual addresses of different processes do not allow to map to the same physical address. Thus, it is not possible for a process to access the physical location of another process.
(3) Thread Concurrency
Is it possible for two threads to access the same physical address? The answer is yes because we have known that different threads share the same virtual address space. So both of the threads of a process can concurrently be running as part of their address space and they can legally perform access to the same physical memory. However, if these threads can access a physical address at the same time, there will be some inconsistency problems (i.e. see the data race problem).
(4) Synchronization Mechanisms
There are two kinds of synchronization mechanisms that serve different coordination purpose,
- Concurrency Control Mechanism: Mutex
To deal with the concurrency problems of the threads, we need a mechanism for threads to execute in an exclusive manner, and this mechanism is called mutual exclusion (aka. Mutex). Mutual exclusion is a mechanism that only one thread at a time is allowed to perform an operation. So if two threads want to make the same operation, one of them must wait for its turn.

- Coordination Mechanism: Conditional Variable
In addition, it is also useful for threads to have a mechanism to wait for one and another. Suppose we have a thread working, and we don’t want the other threads that wait for the result of this thread to repeatedly check the status of this thread because this can reduce the performance. The threads that are not working could send a specific condition at the beginning like “I will sleep until you wake me up.” and then when the working thread finishes (or meet some conditions), it sends another condition like “Wake up, I am finished.” before the proceeding. This mechanism is called a conditional variable.

3. Mutual Exclusion
(1) Thread Creation
The following content is based on the research paper of Andrew D. Birrell, who is a computer scientist who devoted his life to operating and distributed systems. This is a fundamental level introduction of the theory of the threads.
In Birrell’s paper, we use a data structure called thread type to represent a thread and this data structure contains all information that specific to a thread including the thread ID, the register values, the program counter (PC), the stack pointer (SP), the stack, and some other attributes of that thread (for scheduling, debugging, etc.).
Birrell used a fork call to create a thread. We should note that this is different from the fork UNIX system call (for creating a copy of the current process and it can be used with the system call exec) that we have talked about in the previous sections. The synopsis of the fork should have two parameters, proc and args ,
t1 = fork(proc, args)
the proc parameter is the program counter that the new thread is going to start by and the args will be available on the stack of this newly created thread. fork also returns to its caller a handle (in this case, variable t1) on the newly created thread.
t1 Data Structure
PC = proc
stack = args
After this operation completes, the process as a whole now has two threads, the original one t0 (also called the parent thread) and the newly created one t1. Suppose we have a multiple-core system, then t0 and t1 can execute concurrently. Then, t0 is going to continue the execution of the current code and t1 will start to execute the code from proc.
(2) Thread Termination
Once t1 is finished, t1 can either return the computed results or it can have some status of the computation, like success or error. When t1 finishes, some other threads (like t0) may want to get the returned result of t1. If we call join in the thread t0, then t0 will be blocked until it gets the result of t1.
child_result = join(t1)
(3) Thread Creation and Termination Example
Suppose we have the following pseudocode and the operation safe_insert is a call that manipulates the shared list list.
Thread thread1;
Shared_list list;
thread1 = fork(safe_insert, 4);
safe_insert(6);
child_result = join(thread1);
the program above executes the call safe_insert(4) for thread1 and safe_insert(6) for thread0 in parallel, and it assigns the result of calling safe_insert(4) to the variable child_result. In this case, the join call is optional because the result of the safe_insert(4) will be stored in the shared link link. So we can also capture the child result without calling join.
Moreover, in reality, join is not called very much because most of the new threads we fork can have no results, or the result can be communicated in some other ways (like list). Thus, if a thread’s initial procedure has returned and there is no subsequent call of join, the thread quietly evaporates.
(4) Recall: Linked List Data Structure
Let’s see how does a shared linked list works. Almost each of the elements in a linked list consists of two parts, value (the value we want to store in this entry) and p_next (the pointer points to the next element). To insert a value X into the linked list list,
List_element e;
e.value = X;
e.p_next = list.p_next;
list.p_next = &e;
In the beginning, when we create the linked list Shared_list list; , we are actually creating an element with list.value = head; and list.p_next = NULL;,
+-------+------+
| head | -+-> NULL
+-------+------+
Then, suppose we insert a value X, our linked list should be,
+-------+------+ +-------+------+
| head | -+-> | X | -+-> NULL
+-------+------+ +-------+------+
What’s more, suppose we then insert a value Y, our linked list should be,
+-------+------+ +-------+------+ +-------+------+
| head | -+-> | Y | -+-> | X | -+-> NULL
+-------+------+ +-------+------+ +-------+------+
(5) Concurrency Control Problem
Now let’s look back to our last example. We have known that the program executes the call safe_insert(4) for thread1 and safe_insert(6) for thread0 in parallel and there is a problem if two threads are running on the CPU at the same time because their operations are randomly interleaved. If the thread t1 and t0 simultaneously set the pointer of the element to NULL and then take turns in setting the pointers of the list, the first inserted element will be abundant.
For example, after e.value = 4; e.p_next = list.p_next; and e.value = 6; e.p_next = list.p_next;, all the p_nexts will be pointing to NULL,
+-------+------+
| 4 | -+-> NULL
+-------+------+
+-------+------+
| 6 | -+-> NULL
+-------+------+
Then if we first run list.p_next = &e; for t0 and then for t1, the result will be,
+-------+------+ +-------+------+
| head | -+->| 4 | -+-> NULL
+-------+------+ +-------+------+
+-------+------+
| 6 | -+-> NULL
+-------+------+
This is not what we want because the value 6 is not stored in the linked list.
(6) Concurrency Control By Mutual Exclusion
We have noticed that we must deal with the concurrency problem if we want to implement a multi-thread system. In order to deal with that, the operating system (and the threading library) supports a mechanism called mutual exclusion (mutex). A mutex is like a lock and it should be used whenever we want to restrict the shared data among the threads.
Mutex m;
lock(m) {
// critical section
} // free lock
The data structure of mutex should at least contain information about the locked status (default unlocked), a list of all the threads that are blocked (no need to be in order), and the owner thread of this lock. When a thread locks a mutex, it has exclusive access to the shared resources and this means that the other threads can not be able to successfully access or lock the same mutex. If another thread attempts to lock the mutex when it is already locked, the second thread blocks until the mutex is unlocked. The portion of the shared code that has been locked by mutex is called the critical section.
It is also interesting to know that Birrell’s construct of mutex follows the structure of,
lock(m) {
// critical section
} // free lockand the code above implicitly frees the lock after the critical section. While most of the common APIs have two separate explicit calls lock and unlock. So the structure of some other interface can be,
lock(m);
// critical section
unlock(m);
(7) Mutex: An Example
Now, let’s see how to deal with the concurrency problem in the previous linked list example. Suppose we still have the following main program,
Thread thread1;
Shared_list list;
thread1 = fork(safe_insert, 4);
safe_insert(6);
child_result = join(thread1);
And we would like to build a safe_insert call that will not have any concurrency problems by using the mutex. This function could be,
Mutex m;
voidsafe_insert(int i) {List_element e;
lock(m) {
e.value = i;
e.p_next = list.p_next;
list.p_next = &e;
}
}
4. Condition Variables
(1) Producer/Consumer Example
Before we look at the mechanism of the condition variables, let’s first see a producer/consumer example. Suppose we create 10 threads (handled by producers[0] to producers[9]) used to write their thread IDs into a linked list by the call safe_insert until the linked list is full. Then, we create 1 thread that is going to print and then clear this linked list only when this list is full.
// main
for i = 0, ..., 9
producers[i] = fork(safe_insert, NULL) // create producers
consumer = fork(print_and_clear, list) // create consumers
Suppose we only use the mutex, we should have the safe_insert call as
// producers
Mutex m;
lock(m) {
list.insert(producers[i].tid);
}
Then the consumer call should be,
// consumer
Mutex m;
lock(m) {
if list.full {
list.print;
list.clear;
}
}
However, the behavior of the consumer can be wasteful because it has to conduct <lock, not full, unlock> pairs every time, and what we want is that this thread can wait for the other threads and do nothing until the other threads tell it that the list is full.
(2) Condition Variable
Birrell recognizes that this can be a common situation in the multi-thread system, so he designed a new construct called the condition variable. This construct should be used in conjunction with mutexes in order to control the threads.
So the producer program can check for the full condition of every execution and send a single of list_full if the list is full. The Signal call can be used to send the signal.
// producers
Mutex m;
lock(m) {
list.insert(producers[i].tid);
if list.full Signal(list_full);
}
For the consumer thread, it will wait for the signal list_full before it continues the program. We are using the Wait(m, list_full) call to wait for the signal,
// consumer
Mutex m;
lock(m) {
While (!list.full) Wait(m, list_full);
list.print;
list.clear;
}
(3) Condition Variable API
For the condition variable, we commonly have the following APIs,
- Condition type: used to set the data type of the signal,
Condition cond;
Wait: for waiting for the signal. We should know that the mutex is automatically released and re-acquired if we have to wait for this conditioncondto occur.
Wait(mutex, cond);
/* automatically release mutex
** go on waiting queue
**
** wait ... wait ... wait
**
** remove from waiting queue
** re-acquire mutex
** exit the wait operation */
Signal: be able to weak up one thread that is waiting forcondat a time.
Signal(cond);
Broadcast: be able to weak up all threads that are waiting forcond.
Broadcast(cond);