Operating System 7 | Thread Part 3, Kernel/User-Level Threads, and Multithreading Patterns
Operating System 7 | Thread Part 3, Kernel/User-Level Threads, and Multithreading Patterns

- Kernel/User-Level Threads
(1) Kernel-Level Threads
The kernel-level threads imply that the operating system itself is actually multithreaded. The kernel threads are visible to the kernel and they are managed only by the kernel-level components like the kernel scheduler. Some kernel-level threads are used to support the operating system, while others are used for supporting the user-level threads.
(2) User-Level Threads
At the user level, the processes themselves are multi-threaded and each of them contains several user-level threads. For the execution of a user-level thread, it must associate with a kernel-level thread. So there has to be some sort of relationship between the user-level threads and the kernel-level threads.
(3) One-To-One Model
The first model between the user-level threads and the kernel-level threads is a one-to-one model, which means that each of the user-level threads has a corresponding kernel-level thread. So the operating system can see all the user-level threads and the OS also knows the synchronization, the blocking, and extra. By this model, the user-level threads can directly benefit from the thread supports that are available in the kernel.
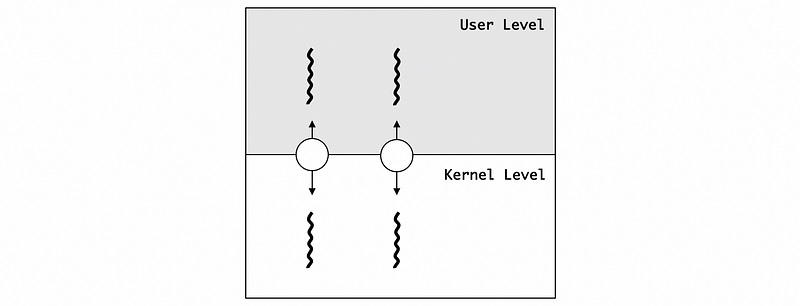
However, this model also has some downsides.
- Expensive: For every operation, we have to go to the kernel. So we have to pay the cost of the system calls
- OS Policies: The OS can have limited policies, for example, the process can be restricted by the number of the threads
- Portability: We also need to think about the portability concerns
(4) Many-To-One Model
Suppose we have a relationship that several user-level threads are mapped onto a single kernel-level thread. To implement this model, we need to have a thread management library in the user lever that decides which one of the user-level threads will be mapped onto the kernel-level thread.
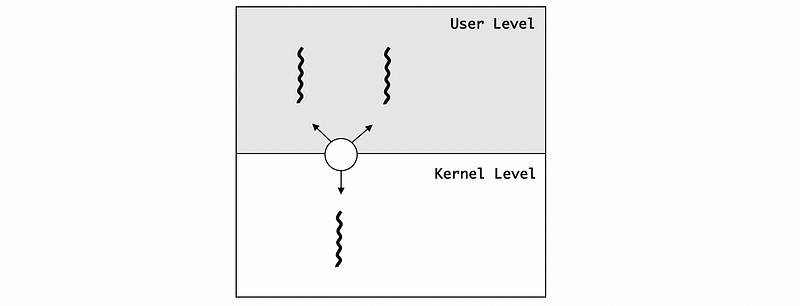
The benefit of this model is that it is totally portable. This means that almost everything can be done in the thread management library and we don’t rely on any kernel-level support.
However, this model has some downsides as well,
- OS has no insights into the application’s needs
- the OS may block the whole process if one user-level thread blocks on I/O
(5) Many-To-Many Model
The many-to-many model allows some user-level threads mapped to some kernel-level threads. The kernel knows that the process is multi-threaded different user-level threads can be mapped to different kernel-level threads. If some user-level threads are blocked from I/O because the corresponding kernel-level thread is blocked, the process overall can have some other kernel-level threads that can do the I/O operations.
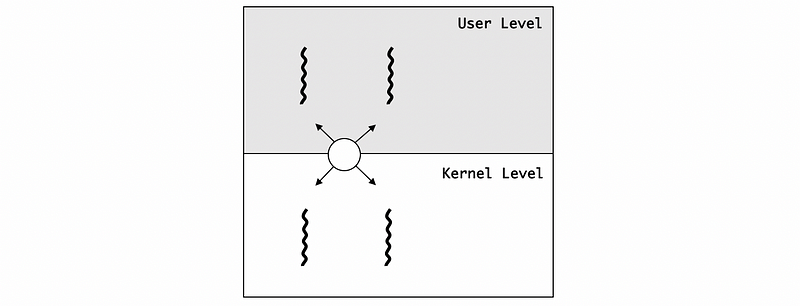
The downside of this model is that now we must need some coordination between the user-level thread management and the kernel-level thread management.
(6) The Definition of System Scope
There are different levels in which multi-threading is supported, at the entire system or within a process and each level affects the scope of the thread management system. At the kernel level, we have system-wide management that is supported by the operating system thread managers, and this scope of thread management is called the system scope.
(7) The Definition of Process Scope
We have also talked about that at the user level, there’s a user-level thread library (links to a process) that manages all the threads that are only within that single process. Different processes will be managed by different instances of the same library or even different processes may link entirely to different user-level libraries. This scope of thread management is called the process scope.
(8) System Scope Vs. Process Scope
Suppose we have two processes, one process has 50 threads and the other has only 5 threads. If we use the process scope for thread management, the OS will not know what is going on for each of these two processes. Then the OS will potentially allocate equal kernel-level threads for these two threads and the former one will be slow.
However, if we use the system scope for thread management, the OS will allocate different resources for these two threads because the OS really knows how many threads they have.
2. Multithreading Patterns
(1) Boss-workers Pattern
This is a popular multithreading pattern with one boss thread assigning works to the other threads and other worker threads perform the entire task that is assigned to them. Since we only have one boss thread that must execute on every single piece of work that arrives in the system, the throughput of the system is limited by the boss thread. Therefore, we must keep the boss thread efficient. So the less time the boss spent on each order, the more efficient our system will be.
The boss can actually assign the works to the workers by two approaches,
- The boss keeps track of the free workers and then directly signaling the specific worker. Also, the worker has to the boss that it accepts the work, like a handshake. The advantage of this approach is that the workers don’t have to synchronize with each other. However, because the boss needs to supervise all these worker threads, the boss will spend more time on each order and the general throughput will go down.
- The boss and the workers share an order queue. When the boss grabs an order, it will place the order in the shared queue so that each of the free workers can look into it and then picks up some pending work. The downside of this method is that the boss and the worker now have to synchronize the access to the shared queue. Because the boss now has less work to do for each order, it will spend less time on each order and the general throughput will go up.
Usually, we tend to pick the latter approach for better system performance if we are willing to use the boss-workers pattern for multithreading.
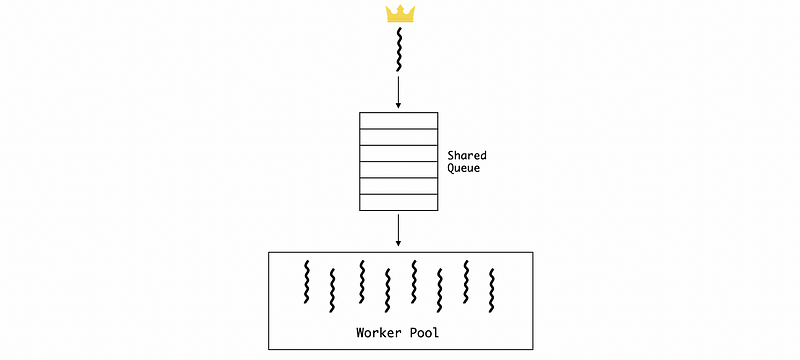
(2) Determine the Number of Workers
Suppose we have fewer workers than we need, the shared queue will be easy to be full. When the queue is full, the boss has to wait for an empty space so the average time the boss spends on each order will increase. This will result in a worse throughput. However, if we have more workers than we need, we are going to add some overheads to the system and it will result in a waste of resources. So how many workers are enough for this boss-worker pattern? Actually, we usually have two approaches for this, we can have either a statically sized worker pool or we can have a dynamically sized worker pool. We are not going to go into the details of this problem and here, we can just have this brief introduction.
(3) Boss-workers Pattern Evaluation
- Simplicity: 1 thread assigns work to all other threads
- Overheads: we have to think about the worker thread pool management including synchronization for a shared buffer
- Ignore Locality: the works are randomly assigned to the workers instead of concerning about the optimization if we have specifications among the workers (because the worker thread will have the information in the cache if they are assigned to a similar task). Actually, instead of all workers randomly assigned with tasks, we can have workers specialized for certain tasks. Even though this requires the boss to look into each of the order and classify different kinds of jobs, the performance loss will be offset by the improvement of the specialization of the workers. This is called the quality of service management (QoS management). However, load balancing (how many workers we need for each type of task) can become a serious problem if we decide to specialize the workers.
(4) Pipeline Pattern
Another approach to assigning the works is by pipeline. Each of the tasks will be divided into several subtasks that each of them is performed by a separate thread. So the entire task will be equivalent to the pipeline of the threads. Multiple tasks can concurrently exist in the system and each of them will be in different pipeline stages.

(5) Long Time Stage for Pipeline
Similar to the barrel effect, the throughput of this pipeline is determined by the stage that takes the longest time to execute. Well ideally, we would like to have a pipeline with the same time of execution on each stage. In order to deal with the stage that needs more time to execute, we can assign more threads to that stage (subtask). The thread pool of a subtask consists of all the threads we assigned to this subtask.
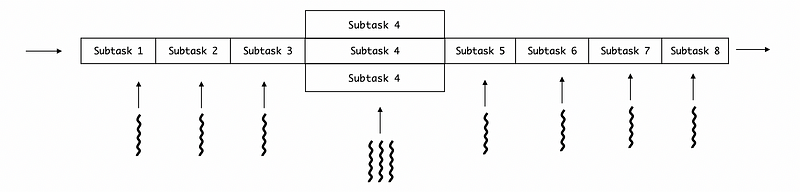
(6) Short Time Difference for Pipeline
Even though we can have more threads assigned to a subtask that takes a longer time to execute, it can be quite a problem for us to deal with the short time difference between different stages. For example, if stage 3 is still executing when stage 2 is ready, stage 2 has to wait for the stage to finish. This will reduce the overall throughput of the pipeline. To deal with this problem, shared buffers are used for communications between different stages or threads.
When a thread finishes, the result will be stored in a buffer and then it will start to execute the next one. If the next thread finishes, it can grab the result from the last thread directly from the shared buffer.
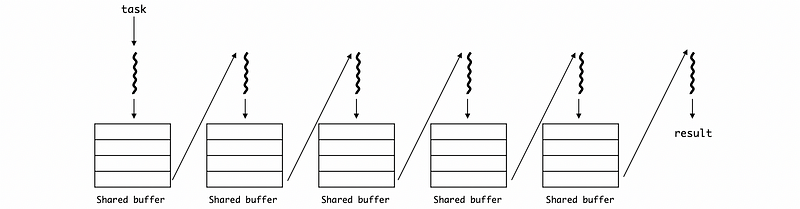
(7) Pipeline Evaluation
- [Adv] Specialization and Locality: highly specialized threads for specific subtasks
- [Dis] Balancing and Synchronization Overheads
(8) Layered Pattern
Each layer of a layered pattern is related to a group of subtasks and each layer can execute any one of the subtasks that correspond to it. An end-to-end task must go up and down all the layers to finish.
The advantages of a layered pattern are its specialization and less fine-grained than the pipeline (this means that it is much easier to decide how many threads to allocate for each layer). The downside are that,
- not suitable for all applications (this pattern highly relies on the subtasks)
- require more synchronization because all the layers have to communicate