Operating System 12 | Interactions between Kernel-Level Threads and User-Level Threads with SunOS…
Operating System 12 | Interactions between Kernel-Level Threads and User-Level Threads with SunOS and Linux Examples

- Recall: Kernel vs User Level Threads
(1) Kernel-Level Threads
Supporting threads at the kernel level means that the OS kernel itself is multithreaded. To do this, the OS kernel maintains some abstraction, for our threads data structure to represent threads, and it performs all of the operations like synchronization, scheduling, etc.
(2) User-Level Threads
Supporting threads at the user level means that there is a user-level library that is linked with the application, and this library provides all of the management and runtime support for threads. Different processes may use entirely different user-level libraries that have different ways to represent threads that support the different scheduling mechanisms.
(3) Mapping Mechanisms
We also discussed several mechanisms on how user-level threads can be mapped onto the underlying kernel level-threads, and we said these include one-to-one, many-to-one, and many-to-many mapping.
(4) One-to-one Mapping
All of the information for this process is contained in the PCB, including virtual address mapping, stack, registers, etc. Whenever the process makes a system call, it traps it into the kernel.
(5) Many-to-one Mapping
Let’s then make the thread multithreaded, and then there will be a user-level thread library (ULTlib) used to manage these threads. Because the thread library is used to manage these threads, it tracks some of the user-level thread (ULT) data structures.
The PCB contains the virtual address mappings as well as the stack and register information for the kernel-level thread.
(6) Many-to-many Mapping
Although we have multi-threads at the kernel level, we don’t want to recreate all of the information in PCB for the multiple kernel-level threads. So we are going to split some information in the original PCB to kernel-level thread control blocks (KLTCB) including the stack and the register pointer for kernel-level threads (KLT). The virtual address mapping will be left in the PCB so all the KLTs can share the information easily.
Compared with the user-level threads, each kernel-level thread looks like a virtual CPU.
2. Thread Data Structure
(1) At Scale Thread Data Structure
For the data structure of a multithreading process and multiple CPUs,
- each ULT maintains a pointer to the corresponding PCB and vice versa
- each KLT keeps a pointer to the corresponding PCB and vice versa
- each KLT maintains a pointer to which CPU it is running via a shared CPU data structure
So when the kernel needs to context switch amongst KLTs that belong to different processes, it can quickly determine whether they point to different PCBs. Therefore it can easily decide it needs to completely invalidate the existing address mapping (different PCBs) or it can directly use the current ones (same PCB).
(2) Process State
If two KLTs point to the same address space (meaning that they belong to the same kernel-level process and have the same virtual address mapping), there is certain information in PCB for either the current KLT or all the KLTs of this KLP. The information is called the process state.
(3) Hard Process State
The hard process state refers to the information that applies to all threads within a process (i.e. virtual address mappings). When we do the context switch between different KLTs, we want to maintain the hard process state.
(4) Light Process State
The light process state refers to the information specific to a certain KLT within a process (i.e. signal mask/ syscall args). When we do the context switch between different KLTs, we want to replace the light process state.
(5) Process State Separation
Because we want to abort the current light process state and maintain the current hard process state in the procedure of context switch, we have to split the process state to the hard process state and the light process state.
(6) Reasons for Choosing Multiple Data Structures
- Scalability
A single PCB must have a large continuous data structure, while the multiple data structures maintain the same information with smaller data structures and this increases the scalability.
- Overheads
A single PCB should have private copies for each entity, while the multiple data structures are easier to share.
- Performance
A single PCB should save/restore all the information (i.e. process state) on each context switch, while the multiple data structures only save/restore the information that needs to change (i.e. light process state).
- Flexibility
A single PCB should update the ULTlib for any change, while the multiple data structures will update a much smaller portion of the state.
(7) KLT Data Structure Example
Now, let’s take a look at an actual Linux kernel implementation. We are going to use the the version 3.17 of the Linux kernel and from the file kthread.h, we can find a C structure named kthread_worder providing a simple interface for creating and stopping kernel threads. The task_struct element inside this structure is a holding place for tons of important information regarding its process.
3. User Level Structures in Solaris 2.0 (SunOS 5.0)
SunOS was brought by ORACLE in 2010 and it is no longer maintained now. But it is very well known for the quality and the stability of its UNIX distributions. The most of this part is based on the paper Beyond Multiprocessing … Multithreading the SunOS Kernel and the paper Implementing Lightweight Threads. If you have trouble reading a paper, you can refer to this paper about how to read a paper in the first place.
(1) The General Overview
From the Stein and Shah’s paper, we can find the following figure,
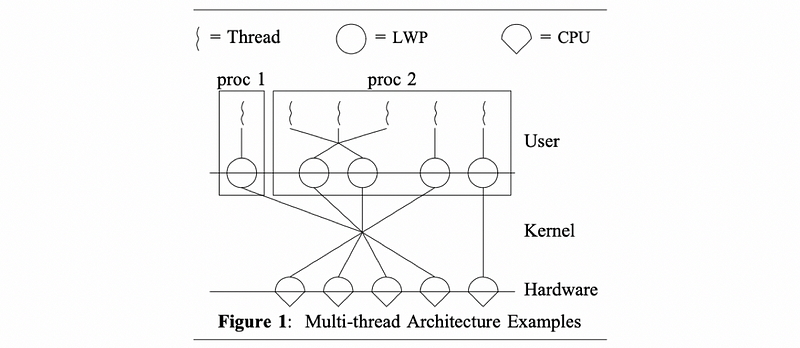
You can also find a similar figure in another paper.
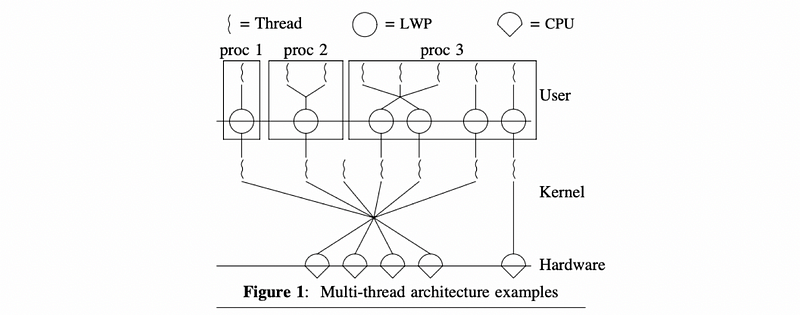
Let’s now analyze this figure.
Going from the bottom up,
- the OS intended for multiprocessors with multiple CPUs
- the kernel itself is multiple threaded with multiple KLTs
- the processes can be single or multithreaded in the UL (user level)
- both one-to-one and many-to-many mappings are supported
- each KLT that is executing a ULT has a lightweight process (LWP) data structure associated with it
- to the ULTlib, the LWP represent the virtual CPU on which it will be scheduling its threads on
- kernel-level scheduler (KLS) will be used to manage and schedule the KLTs onto the physical CPUs (not shown in the figures)
(2) ULT Data Structures
Let’s now see the data structures of a ULT at the UL. This is introduced in Stein and Shah’s paper section Thread Library Implementation in page 3 to page 4.
Recall that for the POSIX thread, when a thread is created, a thread ID is returned and this ID can be used as a pointer to the thread structure. However, the SunOS uses a slightly different way to implement this. The thread ID is not treated as a pointer but as an index. We can use this index for a table of pointers and find the corresponding pointer pointing to the thread structure (page 4).
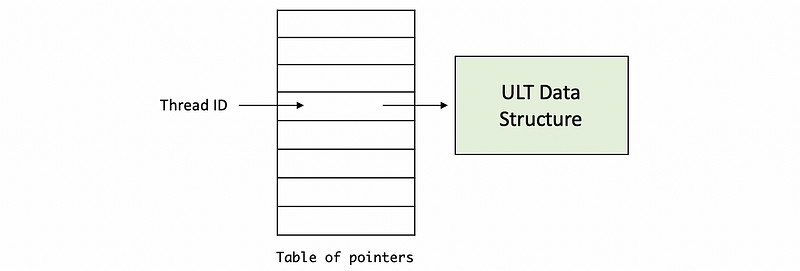
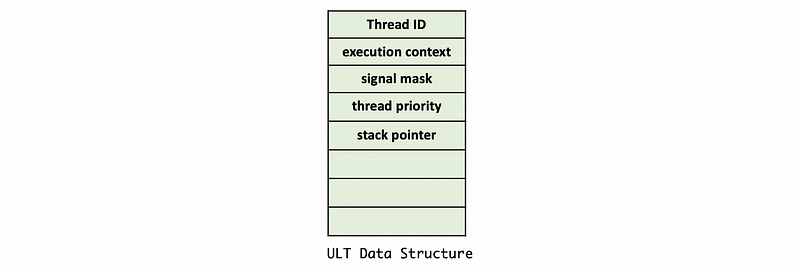
For the data structure of each ULT, it is represented by (page 3),
- thread ID
- an area to save the thread execution context
- the thread signal mask
- the thread priority
- a pointer to the thread stack (stack pointer)
We have two ways to specify the storage for the stack. One way is to automatically allocate the storage by the library. The other way is to pass an area in by the user or the application. The library allocated stacks are obtained by mapping in pages of anonymous memory (Page 3).
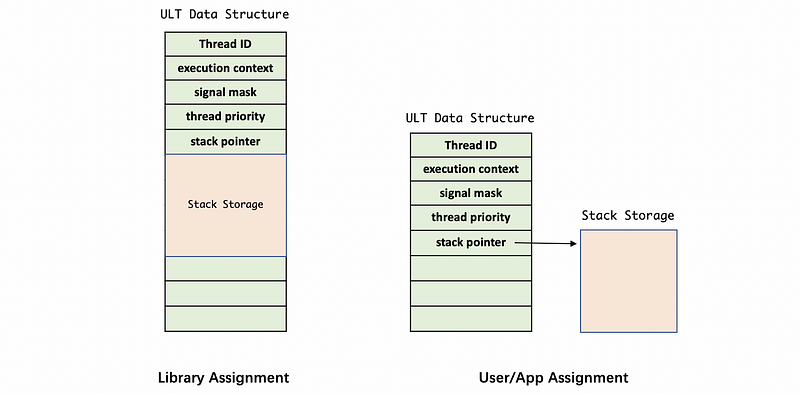
However, there is a problem. The ULT only knows the stack pointer but it doesn’t know where it ends, so there will be a stack overflow problem.
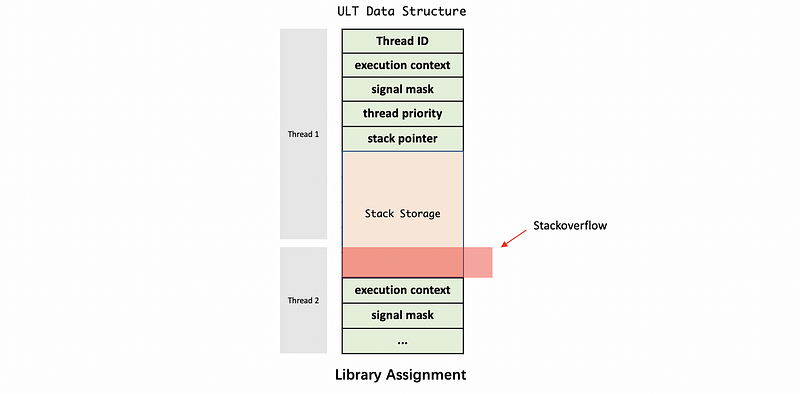
When the stack is overflowed, even though thread 2 will raise an overwrite error, it is hard for debugging because we can hardly figure out that this overflow problem is caused by thread 1.
In Stein and Shah’s paper, the design of “Red Zone” is used to deal with this problem. We add red zones to split different ULTs, and when the stack storage writes to the red zone, an error will be raised and we can easily figure out the thread 1 runs out stack (page 3).
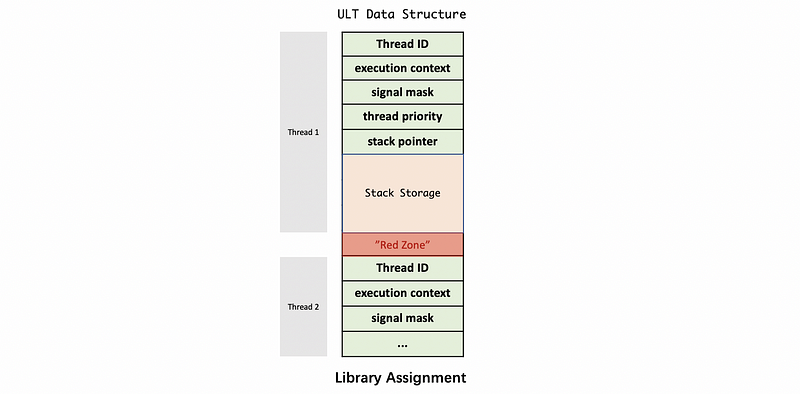
(3) KL Data Structures
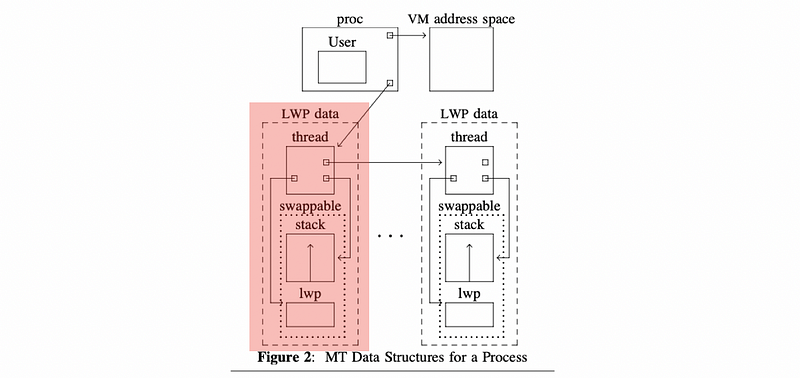
From the Eykholt’s paper at page 2, we can find the following figure about the KL data structures,
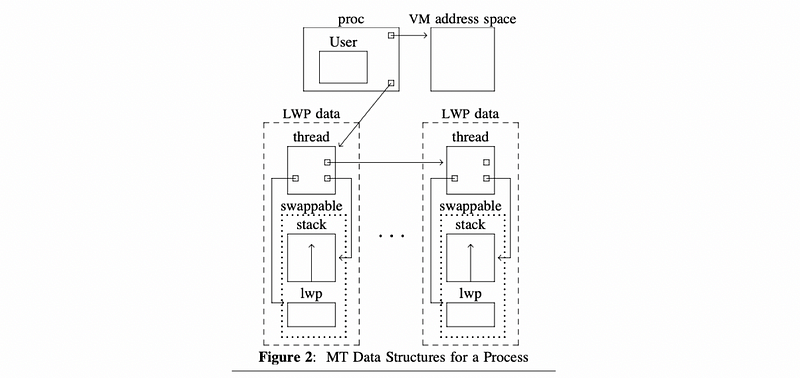
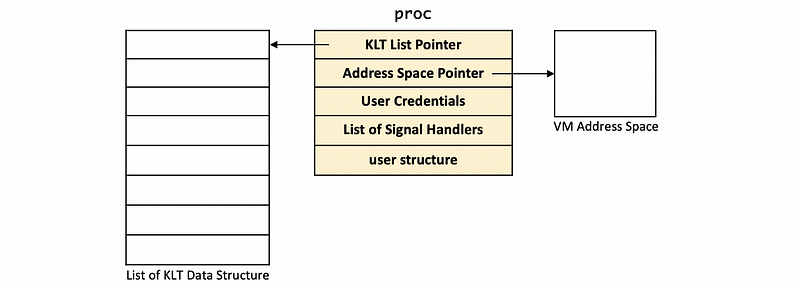
The proc is a process data structure that contains information about the user in User, points to the VM address space, and then points to a list of KLT data structures.
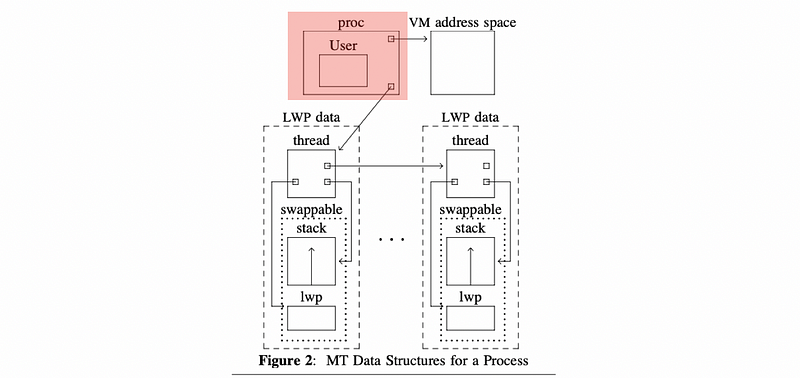
For each KLT data structure in the list, it points to the LWP that it corresponds to, its stack, etc. The LWP and stack portion are actually swappable. What is not shown in this figure is any info about the CPU. Some other pointers are also not shown.
The pre-process data for the current KLT is contained in the proc structure. It contains the pointer to a list of KLTs associated with the process, a pointer to the address space, user credentials, and the list of signal handlers. The proc structure also contains the vestigial user structure.
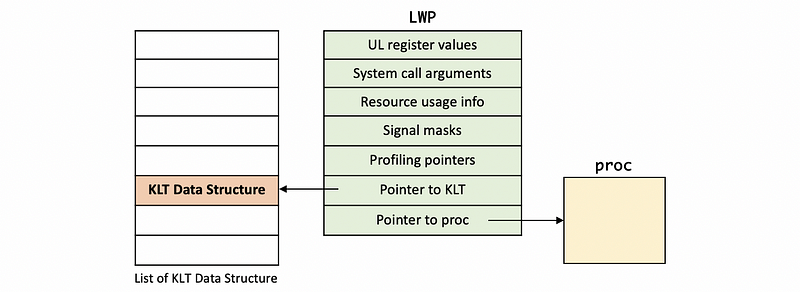
The lightweight process (LWP) data structure contains information that’s relevant to one or more of the ULTs that are executing in the context of the process and keeps track of their UL registers and system call arguments. It contains the structure such as the PCB for,
- UL register values
- system call arguments
- signal handling masks
- resource usage information
- profiling pointers
It also contains pointers to the associated KLT and process structures. The information maintained in an LWP data structure is in some ways similar to what we maintain at the user level in the ULT data structure. Instead, this is what’s visible to the kernel, so when the OS level schedulers need to make scheduling decisions they can see this information and act upon it.
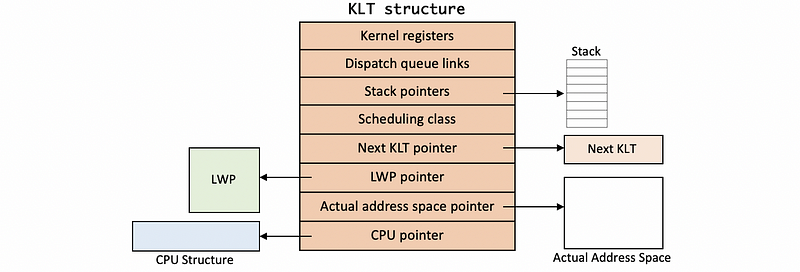
The KLT data structure includes kernel level information like,
- kernel registers
- dispatch queue links
- stack pointers
- scheduling class
- pointer to the next KLT
Also has pointers to the various data structures that are associated with this kernel,
- LWP
- actual address space
- CPU where it is running
Because the KLT is in the memory, it is not swappable because we can lose the data forever. In contrast, the LWP data structure does not always have to be present in memory, so if we’re under memory pressure, it is okay to swap the LWP out.
The pre-processor information is maintained in a structure called cpu , which has the information about,
- pointer to currently executing KLT
- pointer to idle KLTs for the CPU (means the other KLTs in the list)
- dispatch handling information
- interrupt handling information

To speed access to the thread, LWP, process, and CPU structures, the SPARC architecture is used because it contains lots of extra registers.
(4) Basic Thread Management Interaction
- Request More KLTs
Consider we have a multithreaded process. And let’s say that process has 4 ULTs. However, the process is such that, at any given point of time, the actual level of concurrency is just 2. So in the KL, it would be nice if the user-level process actually said, I just really need 2 KLTs.
When the process starts, the kernel will first give it a default number of kernel-level threads and the accompanying lightweight threads. And let’s say that is 1 KLT by default.
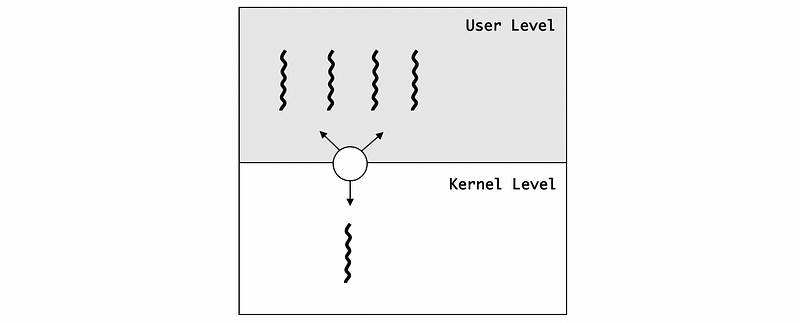
Then, the UL process must request additional kernel-level threads for the currency problem, and this can be done because the kernel supports a system call called set_concurrency. In response to this system call, the kernel will create additional threads and it will allocate those to this process.

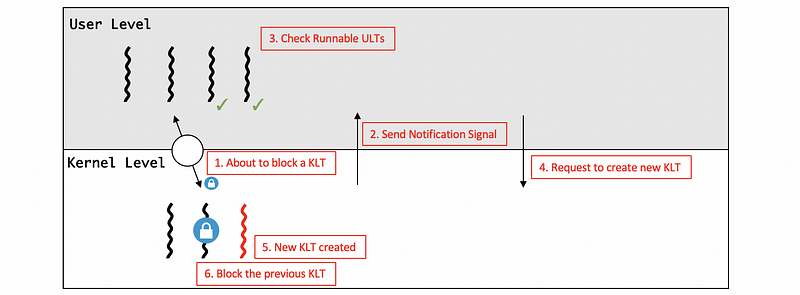
- Handling KLTs Block
Suppose the two ULTs are occupied by two of the I/O operations in the user level, they were basically moved onto the wait queue that’s associated with that particular I/O event. So the two corresponding KLTs are blocked as well.
Because we only have 2 KLTs in this case, now we have a situation where the process as a whole is blocked. However, other ULTs are ready to run and make progress. The reason why this is happening is that the kernel doesn’t know what is happening in the ULTlib, it doesn’t know that the ULTs are about to block and whether we have runnable ULTs.
In order to deal with this problem, the kernel can send a notification signal to the ULTlib before it blocks any KLTs. Then the ULTlib can check its running queue and finds out if it has runnable ULTs. If it has multiple runnable ULTs, it still needs to maintain a 2-thread-level concurrency. Thus, a system call to request will be made more KLTs with associated LWPs.
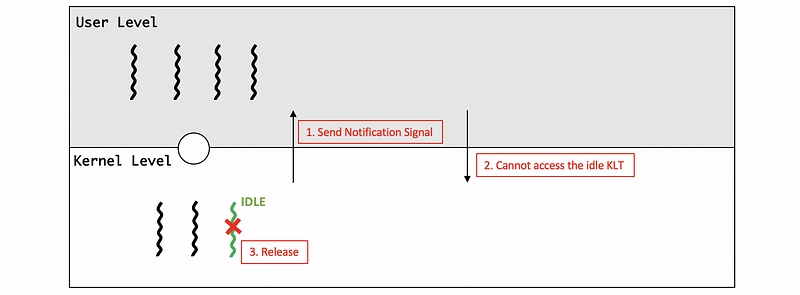
- Release the Idle KLT
At a later time when the I/O operation completes, at some point, the kernel will notice that one of the kernel-level threads is pretty much constantly idle because we said that that’s the natural state of this particular application that needs only 2 KLTs.
Then, the kernel can tell the ULTlib that you no longer have access to this kernel-level thread, so you can’t schedule on it. The reason we need to tell the ULTlib is that the ULTlib doesn’t know what’s happening in the kernel.
(5) Thread Management Interaction: A PThread Example
From the PThread library, the function pthread_setconcurrency is provided for the thread management interaction. You can refer to the manual page of the function for more information.
Note that when 0 is passed as the parameter for this function (i.e. pthread_setconcurrency(0)), it means that the underlying manager should decide how to manage the concurrency level for the particular process (as it deems appropriate).
(6) Thread Management Visibility
At the KL, the kernel sees all the,
- KLTs
- CPU
- KLS(which is the one making decisions)
At the UL, the ULTlib sees,
- ULTs that are part of that process
- KLTs that are assigned to that process
If we are using the one-to-one model, then every ULT will have a KLT associated with it. Even if it’s not a one-to-one model, the user level library can request that one of its ULTs can be bound to a KLT.
At the KL, if a particular KLT is permanently associated with a CPU, we call this process pinning because the KLT is pinned to the associated CPU.
(7) Visibility Issue: ULT Locking Problem
Suppose we have 4 threads at the UL and all of these threads use the same lock. If the KLT now is supporting the execution of that critical section code of a thread, all the other threads will be blocked from the same critical section because of the mutex lock.
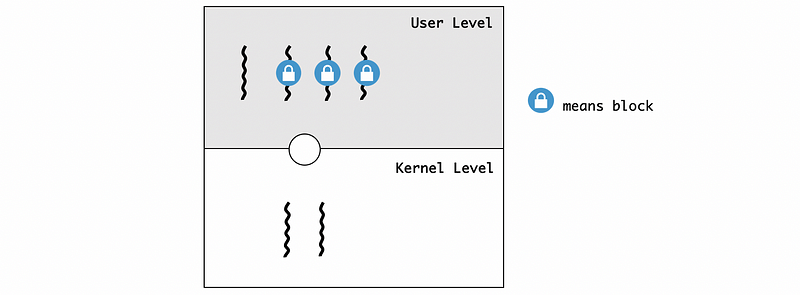
If we have the situation in which the kernel preempted this executing KLT, and all the current KLT and the corresponding ULT will be delayed because the KLS schedules will then schedule the other KLT.
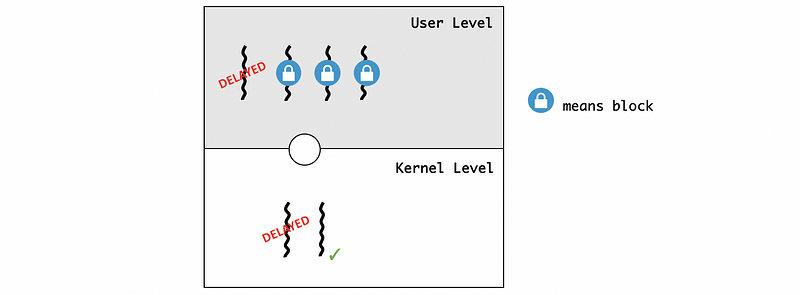
Now, the execution of this critical section cannot continue because all the other ULTs will be blocked from the critical section. After the kernel figures out this blocking issue, the previous KLT will be scheduled by the kernel again. Then the critical section will be completed, and the lock will be released. And subsequently, the rest of the ULTs will be able to execute.
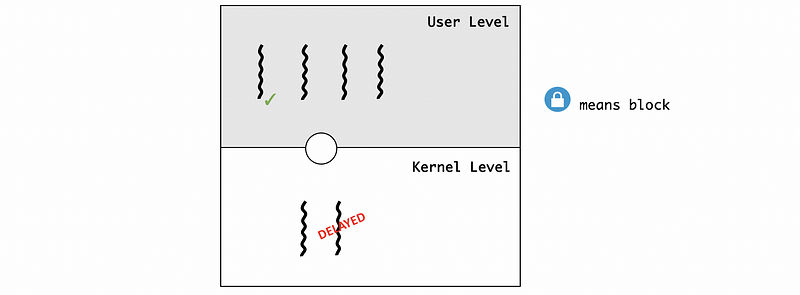
(8) Visibility Issues Reasons for Many-to-many Model
There are several reasons for the visibility issues,
- the ULTlib makes scheduling decisions that the kernel is not aware of, and that will change the user-to-kernel mapping
- data structures like mutex and wait queues are also invisible to the kernel
(9) When does the ULTlib Use?
When a UL process (ULP) needs some features of the kernel, it has to jump to the ULTlib scheduler. A ULP jumps to the ULTlib scheduler when,
- ULTs explicitly yield
- timer set by ULTlib expires
- ULTs call library functions (i.e. lock/unlock)
- blocking ULTs becomes runnable
In addition to being invoked on some operations that are triggered by ULTs, the ULTlib scheduler is also triggered in response to certain events/signals that come either from timers or directly from the kernel.
(10) Multiple CPUs: Interactive Issues
In the previous examples, we only had a single CPU. So all of ULTs run on that CPU, and whatever change in the ULTs will be scheduled were immediately be reflected on that particular CPU.
In a multi CPU system, the KLTs that support a single process may be running in multiple CPUs, even concurrently. So we may have a situation where the ULTlib that is operating on one thread of one CPU may impact what is running on another thread of another CPU.
Let’s see an example.
Suppose we have three threads, T3, T2, and T1. The thread priority is that T3>T2>T1. T2 is currently running in the context of one thread on one CPU and currently holds a mutex. T3 with the highest priority is waiting on the mutex and is blocked. T1 is running on the other CPU.
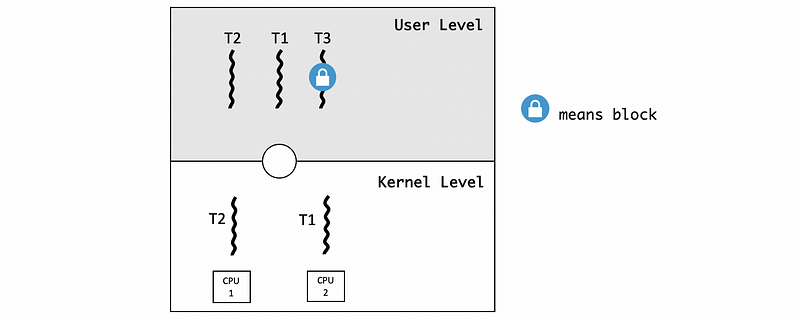
At a later point, T2 releases the mutex (but is still running on the CPU), and as a result T3 becomes runnable. When all three threads are runnable, we have to make sure the ones with the highest priority are the ones that get executed. This means T1 needs to be preempted and we need to context switch T1 for T3.
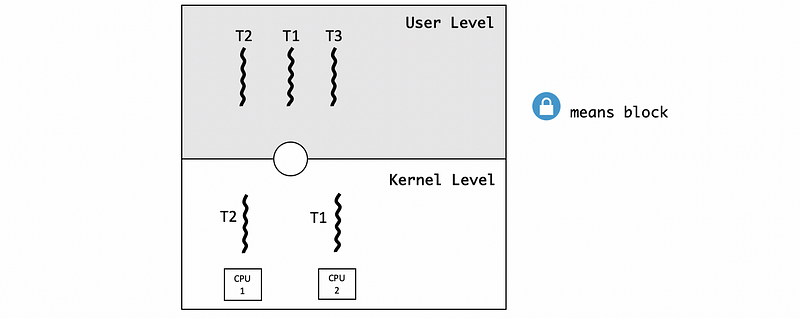
However, T1 is running on a CPU, so we need to notify the CPU to update its registers and program counter. We cannot directly modify the register of one CPU when executing on another CPU.
What we need to do instead is send some kind of signal/interrupt from the context of one KLT on one CPU to the KLT on the other CPU, and tell the other CPU to execute the library code locally.
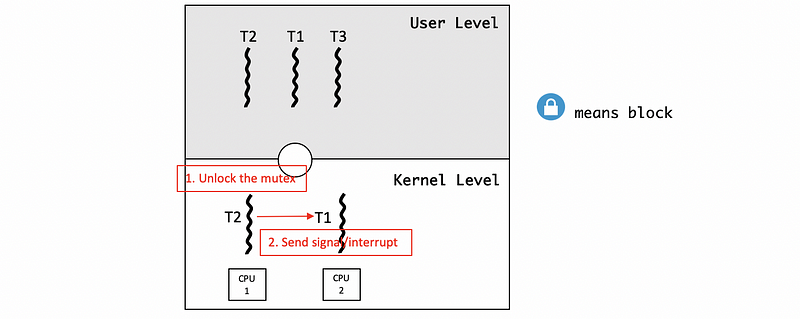
Because the library needs to make a scheduling decision and change who it is executing. Once the signal happens, the ULTlib on the second CPU will determine that it needs to schedule the highest priority thread T3 by blocking the lower priority thread T1.

(11) Multiple CPUs: Synchronization-Related Issues
Let’s see another issue of the multiple CPUs. Consider a situation where ULT1 is currently running on the KLT1 spinned to the CPU1 owns a mutex. This mutex blocks the ULT2 and ULT3 because they have requested the mutex that ULT1 holds.
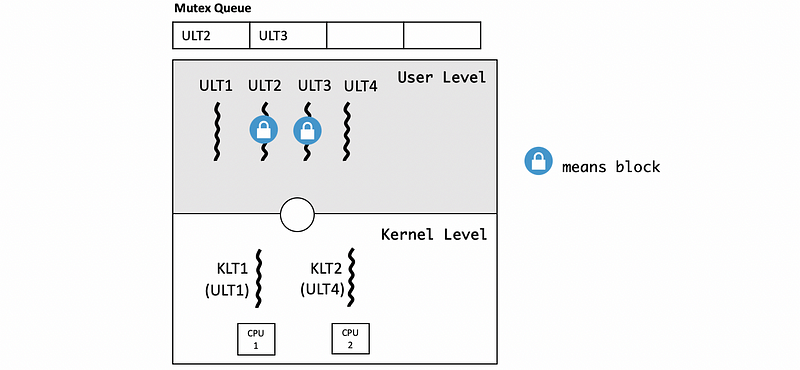
Suppose ULT4 running on the KLT2 spun to the CPU2 requests the mutex that ULT1 is holding, then ULT4 should be enqueued into the mutex queue.
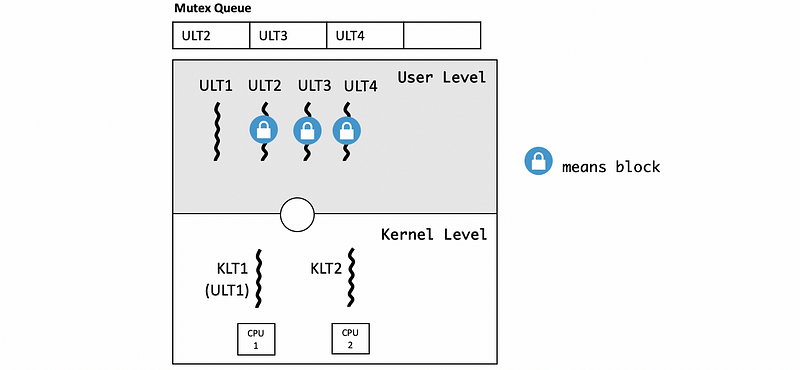
However, if the amount of time that T1 will take to finish is less than the amount of time T4 will take to be placed on the queue and context switch, then it makes more sense to just have T4 “spin, burn some cycles” and wait for the mutex.
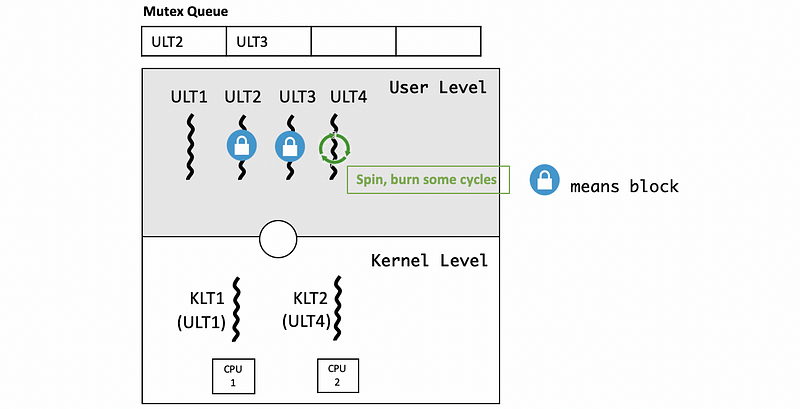
Mutex data structures should contain information about the current owner. With that information, a thread can determine if the owner of a mutex is running on a separate CPU. If another CPU is available and there is a short critical section for ULT1, then ULT4 should spin instead of blocking.
(12) Destroying threads
Finally, let’s discuss destroying threads.
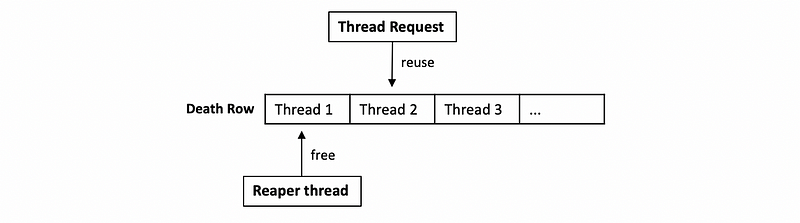
Once a thread is no longer needed, it can actually be destroyed, and the data structure, stack, etc. should be freed. However, since the thread creation takes some time that is quite expensive for us, it helps if we consider reusing threads instead of destroying them.
This is done by when a thread exits, it is not immediately freed. Instead, this thread will be put on death row. Periodically, a reaper thread will be executed to destroy some of the threads on death row. Otherwise, if a thread creation request comes in before the threads in the death row are properly destroyed, then its data structure and stack can be reused.
(13) Example: Threads Number For Linux
From the source code fork.c of the Linux kernel v3.17, we can find out that a minimum of 20 threads are needed to allow a system to boot (line 281–282), and this value can be changed by passing the parameter max_threads.