Operating System 13 | Signals and Interrupts
Operating System 13 | Signals and Interrupts

- Introduction to the Signal and Interrupts
(1) The Definition of the Interrupts
Interrupts are events that are generated externally to the CPU by components that are other than the CPU where the interrupt is delivered (i.e. I/O devices (i.e. network packet arrivals), timers (i.e. for time out), other CPUs (i.e. for context switch), etc.).
Particular interrupts can occur on a given platform depends on the specific configuration of the platform. So the hardware architecture and the type of devices can determine the signals.
Another important characteristic about interrupts is they appear asynchronously. That’s to say that they’re not in direct response to some specific action that is taking place on the CPU.
(2) The Definition of the Signals
Signals are events that are triggered basically by the software that’s running on the CPU. The signals are either generated by software, sort of like software interrupt, or the CPU hardware itself triggers certain events that are basically interpreted as signals.
Signals that can occur on a given platform depend very much on the operating system of this platform. So two identical platforms will have the same interrupts, but if they are running different operating systems they will have different signals.
Unlike hardware interrupts, signals can appear both synchronously and asynchronously. By synchronous here we mean that they occur in response to a specific action that took place on the CPU, and in response to that action, a synchronous signal is generated. For instance, if a process is trying to touch a memory that has not been allocated to it, then this will result in a synchronous signal.
(3) Similarities between Interrupts and Signals
There are some aspects of interrupts and signals that are similar,
- both of them have a unique ID depending on hardware or OS
- both of them can be masked. We use either a per-CPU mask for the interrupts or a per-process mask for the signals. The interrupt mask is associated with a CPU because interrupts are delivered to the CPU as a whole. Whereas, the signal mask is associated with a process because signals are delivered to individual processes.
- If the mask indicates that the signal or the interrupt is enabled, then that will result in invoking the corresponding handler. Interrupt handlers are specified for the entire system by the OS, but signal handlers are specified per process by the process.
(4) Interrupts and Signals Metaphor
Now, suppose we receive two warnings on our mobile phone. The first one is a snowstorm warning, and the second is a low-battery warning. Because the snowstorm is external to the mobile phone (processor) and it depends on the location (hardware architecture), it can be seen as an interrupt. And because the low battery warning is raised by the operating system of the mobile phone, it can be seen as a signal.

First, each of these types of warnings needs to be handled in specific ways, which is correspond to the concepts of interrupt handlers and signal handlers. Second, both of them can be ignored, and this matches the concept of the interrupt mask and the signal mask. And last, we can think about both of them as being expected (synchronously) or unexpected (asynchronously).
2. Interrupt and Signal Handling
(1) Interrupt Handling
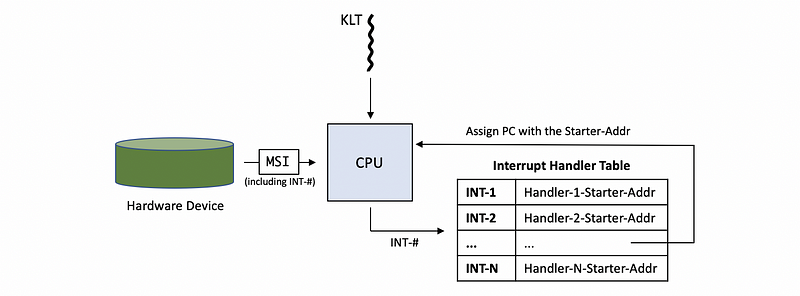
The device interrupts the CPU via the wires that connect it with a unique message with the interrupt ID INT-# (i.e. like INT-1, INT-2, …) (INT means interrupt), and this message is called the message signal interrupter (MSI).
The MSI is then looked up in a table called interrupt handler table (IHT) and the corresponding handler is called. The PC is moved to that address of the handler code and the handler routine is then executed.
(2) Signal Handling
For handling a signal, the OS defines the possible signals, e.g. SIGNAL-11, instead of the hardware. Similarly, a signal handler table (SHT) is used to map the OS defines the possible signals to the hander’s starter address.

There are default actions defined by the OS in response to these signals including,
- terminate: terminate the process
- ignore: ignore the signal
- terminate and core dump: so that one can inspect the core dump
- stop or continue
for most of the common OS, each process can have its own customed signal handlers which respond in a user-defined way in response to the OS signal by the signal() call and the sigaction() call. However, there are also some signals that can not be “caught” by the process (i.e. some signals will always kill the process).
(3) Examples of Synchronous Signals and Asynchronous Signals
a. Synchronous Signals
- SIGSEGV: attempt to access the illegal/protected memory
- SIGFPE: divide by zero
- SIGKILL(kill, id): direct to another thread
b. Asynchronous Signals
- SIGKILL(kill): cause a process to terminate
- SIGALARM: timer expiring (timeout) issue
3. Interrupt and Signal Masks
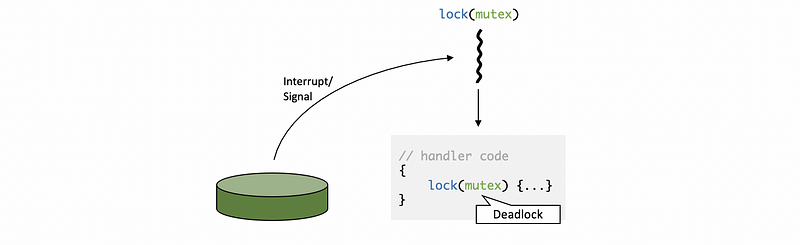
(1) Interrupt/Signal Deadlock Issue
If the interrupted thread has a locked mutex, and the handler also needs to acquire the same mutex, then a deadlock will occur. This issue is caused because of the interrupts and signals executed in the context of the thread that was interrupted.
This can be remedied by the thread first disabling the ability to be interrupted before it acquires the mutex. Likewise, it enables the ability to be interrupted after it releases the mutex.
One possible way to deal with this issue is to keep the handler code simple by removing its lock for the mutex. If there’s no possibility for the handler code to block some mutex operations, then the deadlock will not occur. The problem with this method is that it can be too restrictive. Thus, we will use masks to ignore the interrupts/signals.
(2) The Definition of Masks
The masks allow us to dynamically enable or disable based on whether the handling code can interrupt the executing mutex. These masks are called interrupt masks or signal masks.
The mask is a sequence of bits where each bit corresponds to a specific interrupt or signal in the value of 0 (means disable) or 1 (means enable) that indicates whether the specific interrupt will be disabled or enabled.
(3) Disable Interrupts and Signals by Masks
Now, let’s see an example of how the masks work. At some point of the execution, an interrupt occurs. As a result, the PC will change and it will start to point to the first instruction in the handler. The stack pointer will remain the same. And this can be nested if there are multiple singles/interrupts.
In a nested fashion, they will keep executing on the stack of the thread which was interrupted. The handling routine needs to access some state perhaps some other thread is accessing, so we need to use the mutex. However, if the thread that was interrupted already has the mutex that was needed by the handler routine, we have a deadlock situation.
When an event occurs, first the mask is checked. If the event is enabled, then we proceed with the handler procedure. If the event is disabled, then the interrupt/signal will remain suspended until a later time when the mask value changes.
To solve the deadlock situation, the thread before acquiring a mutex disables the interrupt. So even when the interrupt occurs, it will be disabled and not interrupt the execution of the critical section. If the mask indicates the interruption is disabled, then it will remain pending until a later time.
After the mutex is unlocked, the mask value is reset to its proper value. As a result, the interrupt will become enabled. The operation will allow the execution of the handler code. Now at this time, it is ok to execute this code since we are no longer holding the mutex. The deadlock is avoided.
(4) Basis for Interrupts and Signals
Interrupt masks are maintained on a per CPU basis. What this means is that if the interrupt mask disables a particular interrupt, the hardware support for routing interrupt will just not deliver that interrupt to the CPU.
The signal masks are per execution context. If a signal mask is disabled, the kernel sees that, and in that case, it will not interrupt the corresponding thread. It will not interrupt the execution context.
4. More Topics About Interrupts and Signals
(1) Interrupts and Performance for Multiple CPUs
We can specify that only one of the CPUs/cores is designated for handling interrupts. That will be the only CPU that has interrupts enabled, so we will be able to avoid any of the overheads or perturbations related to interrupt handling from any of the other cores. The result will be improved performance. Therefore, the conclusion is that instead of all CPUs receiving an interrupt, let only one CPU receive it.
(2) Types of Signals
Generally, there are two types of signals.
- One-shot signal (overwrite behavior)
If there are multiple instances of the same signal that occur, they will be handled at least once. So the situation with N same signals pending is equivalent to the situation with only one of that signal pending.
The other thing about one-shot signals is that the handling routine must be re-enabled every single time. So if the process wants to install some custom handler for that signal, then invoking the operation will mean once when the signal occurs, the process handler for that signal will be invoked. However, any future instances of that signal will be handled by the default operating system action. Or if the operating system decides to ignore that set of signals, then they will be lost.
Thus, if a one-shot signal is not re-enabled, the next time the particular signal comes, it will be handled by the default OS handler or ignore the signal instead of the specific handler for that process.
- Real-Time Signals (queue behavior)
Real-time signals that are supported in an OS like Linux. And their behavior is that if a signal is called n times, then the handler is guaranteed to be called n times as well. So, they have sort of a queueing behavior as opposed to an overwriting behavior, as is the case with the one-shot signals.
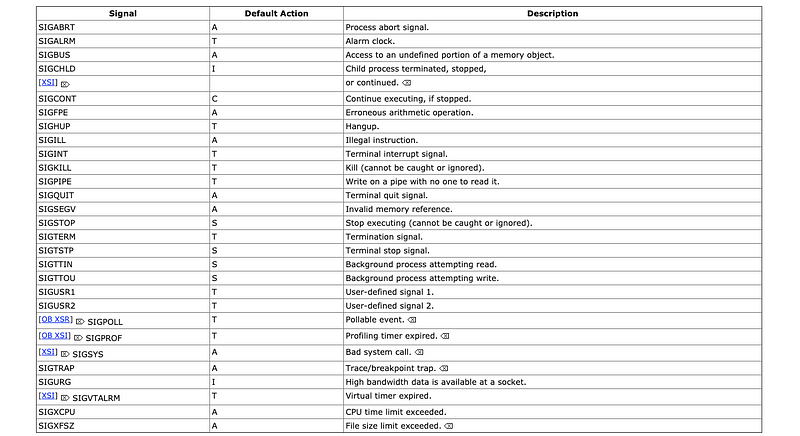
(3) POSIX Standard Signal Names Example
We have talked about the signals and now let’s look at the POSIX standard (POSIX.1-2008) for the signal names of different events. The POSIX standard library documentation can be found here, and you need to search for the signal.h file which controls the signals.
From the page of signal.h , we can find a list of signal names are provided with their descriptions.
5. Interrupts and Threads
(1) Handling Interrupts as Threads
Now let’s look at the relationship between interrupts and threads. In the previous example, when an interrupt/signal occurs there is a possibility of deadlock.
One way as illustrated in the Sun OS paper is to allow interrupts to become full-fledged threads (aka. complete threads), and this should happen every time it is performing blocking operations. In this case, the interrupt handler is blocked at this point. It has its own context, stack, thus it can remain blocked.
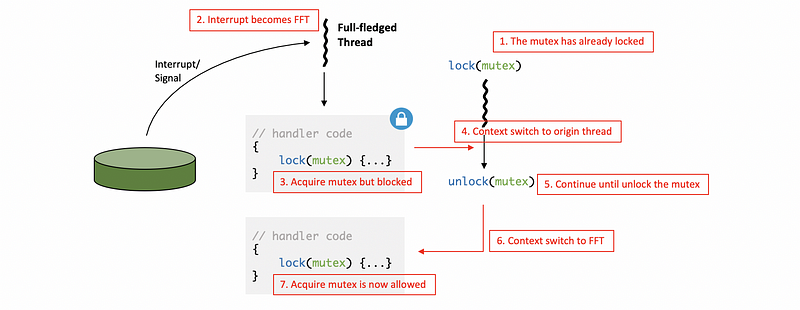
However, there is a problem with this operation because creating dynamic thread creation is quite expensive. So we can not simply turn interrupts to threads all the time with respect to the performance. The rule of whether or not creating a dynamic thread described in Sun OS paper is that,
- if the handler does not include a lock, then no dynamic thread will be created
- if there is a possibility for the thread to be blocked, then we turn it into a real thread
To limit the need to dynamically create a thread whenever there is a potential to block the thread, the kernel can pre-create and pre-initialize a number of threads (i.e. 2 threads) for the variable interrupt routine. As a result, the creation of a thread from the fast path of the interrupt processing and we don’t pay the cost when the interrupt occurs.
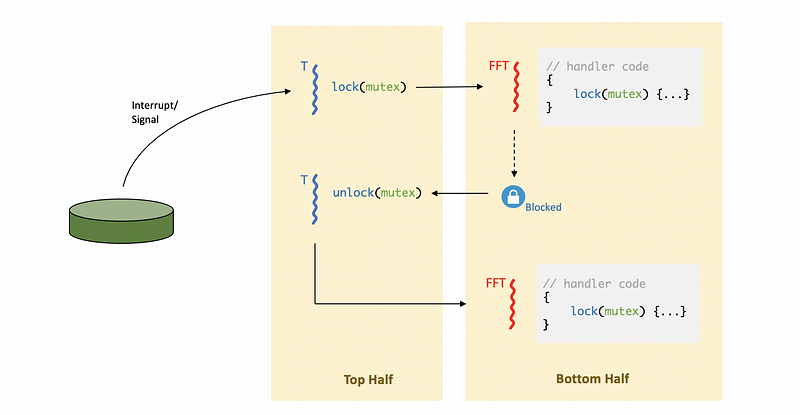
(2) Top Half & Bottom Half Technique
We intentionally chose the words top and bottom to describe what’s happening for a situation with handling interrupts as threads because this is exactly the description of how Solaris uses threads to handle interrupts. If we use the top&bottom-half technique, we don’t have to worry about the deadlocks anymore because the interrupt is executed in a separate thread.
The top half will,
- handle a minimum amount of processing
- be required to be non-blocking
- execute immediately when the interrupt occurs
The bottom half is allowed to,
- have any arbitrary/complex processing
- like any other thread, be scheduled for a later time
- be blocked
(3) Performance of Handling Interrupts as Threads
The behavior of using threads to handle interrupts is really motivated by performance. It is best to handle interrupts by using threads instead of doing the mask/unmask/check mutex/etc.
The operations that are necessary to perform the appropriate checks of whether to use a thread for handling an interrupt add about 40 SPARC instructions per interrupt. Without changing the interrupt masks whenever a mutex is locked and then switch it back again, we can save about 12 instructions per mutex.
Because the number of the mutex lock/unlock operations is much more than the number of the interrupts, we can expect that we end up saving much more instructions on the mutex than the cost on interrupts. This brings to an important conclusion in the system design: optimize for the common case.
(4) Different UL and KL Masks Issue
Signal masks are associated with the ULT and the KLT (or attached LWP). When ULT wants to disable an interrupt/signal, it changes the bit in the ULT mask to 0. However, the ULT mask is not visible to the kernel (and vice versa), so that the kernel mask will remain the same. If the kernel visible signal mask is enabled (bit set to 1), it wants to respond to the signal.
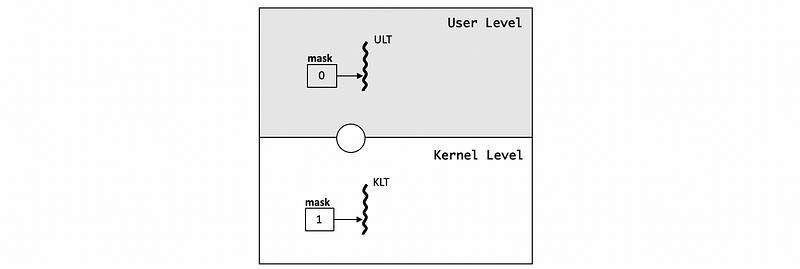
So either we need a method to cross the user/kernel barrier and set the kernel mask in this case to 0 (since UL mask is 0), or we need to have a policy that deals with the situation where the user level and KL masks are different. In fact, the SunOS paper describes the lightweight user-level threading library (LWULTlib) that proposes a solution to how to handle this situation.
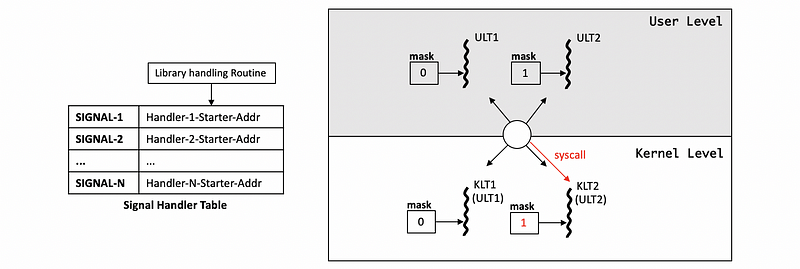
(5) Different UL and KL Masks Case1: 2 ULTs with 1 KLT
Suppose we have two ULTs, ULT1 and ULT2, and the ULT1 is currently running on the single KLT. The ULT2 is runnable but it is currently pending in the run queue. Because the KLT has a mask of 1, it will then see that the process overall knows how to handle the signal/interrupt. However, the ULT1 has a mask of 0 and this means a signal/interrupt disabled for this ULT. We should figure out a way on how to get to the LWULTlib because it knows that the ULT2 would be able to handle a signal/interrupt.
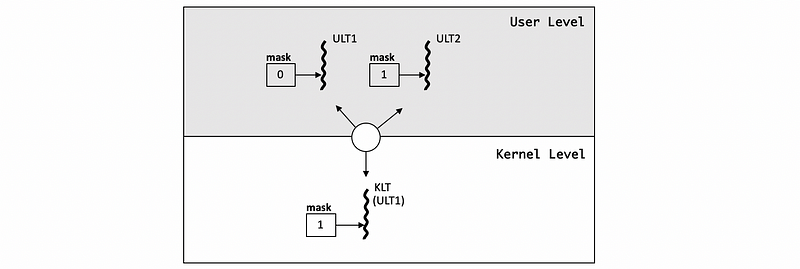
There exists a library handling routine that serves as a wrapper class for the signal handlers. When a signal occurs, the KLT runs the wrapper routine. The wrapper routine has access to all the threads running in the process so it will see that ULT2 has the mask enabled and will then switch ULT2 to be running on KLT.
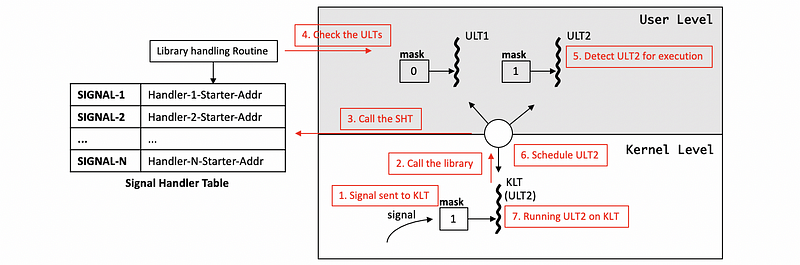
Recall the way signals are handled. When the signal interrupts the process or a thread that is running in the process, the corresponding handling routine (aka. the handling code segment) needs to be executed is specified in the signal handler table (SHT) by the starter addresses of these routines.
Thus, for all the signals in the system, we can have a special library routine that will wrap the signal handling routine. So when the signal occurs, we start to execute the handler provided by ULTlib which can see all the masks of the ULTs. Then the LWULTlib will be able to detect the situation that the currently ULT can not handle the schedule, but there’s another runnable user-level thread that can handle the signal. The library handling routine will then call the library scheduler and it can now make the ULT2 running on the KLT so that the signals can be handled.
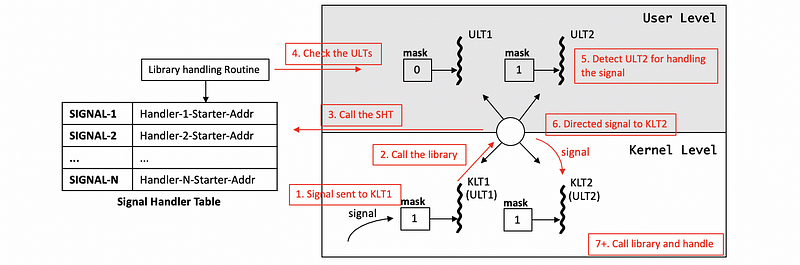
(6) Different UL and KL Masks Case 2: 2 ULTs with 2 KLTs (with enabled)
Here, in this case, we have 2 ULTS, ULT1 and ULT2. The ULT1 is currently running on the KLT1 pinned to the CPU1, and the ULT2 is currently running on the KLT2 pinned to the CPU2. Let’s suppose that the mask for the ULT1 is set to 0 at the beginning and this means that it has signal disabled. However, the masks for the other threads (including ULT2, KLT1, KLT2) are all set to bit 1, and this means the signal is enabled.
So when the signal is delivered in the context of the KLT1, the library handling routine will kick in and it knows that there is a ULT2 that can handle this particular signal, but this ULT is associated with another KLT (KLT2). Then the library will generate a directed signal to the KLT2 where the ULT2 is currently executing.
After the OS sends this signal to the KLT2, it will again call the library handling routine and handle the signal because ULT2 is enabled for signals.
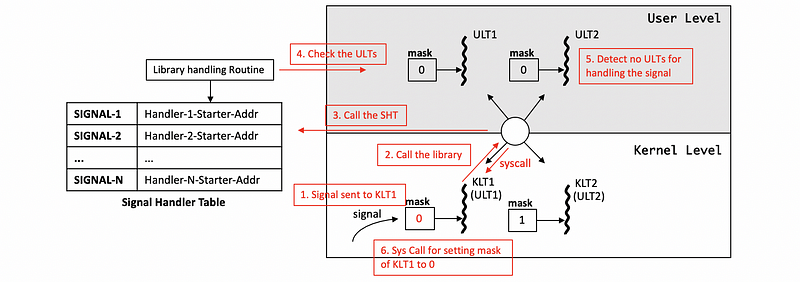
(7) Different UL and KL Masks Case 3: 2 ULTs with 2 KLTs (all ULTs disabled)
We have one case left for us, and you may be curious about what will happen if we have all the ULTs disabled with their masks all set to 0s. However, the KLT masks are still the bit 1, and they still think that the process can handle this particular signal.
So when a single is sent to KLT1, it goes up and calls the library handling routine as normal because it thinks that we can handle this signal. Whereas the library handling routine then sees all the particular threads have the mask 0, so it doesn’t have any ULTs to handle the signal.
Then the library will call a system call and set the mask of the KLT1 (the KLT that receives the signal) to 0.
The library does not stop at this point. Instead, it will continue updating all the masks of the KLTs until all of them become 0s so that all the KLTs will know that they can neglect the future signals. Thus, the library will re-issue the signal for the other processes and then they will execute the same process and thus all the masks will be updated to 0s.
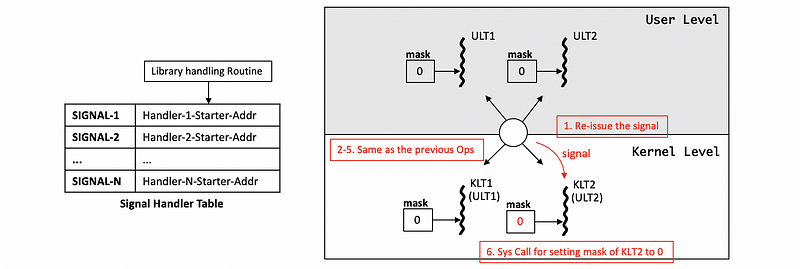
(8) Different UL and KL Masks Case 4: 2 ULTs with 2 KLTs (all KLTs disabled)
Let’s continue with the last case. Let’s say that in the last example, we have a final state that all the masks are set to 0, and all the threads are signal disabled. At this moment, there is a possibility that one of the ULTs (let’s say ULT2) finishes whatever they were doing and enables the signal by setting its mask to bit 1 again.
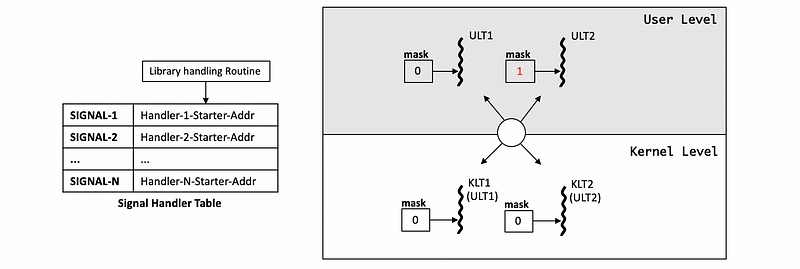
Because the threading library knows that it has already disabled all of the KL signal masks, it will at that time performs a system call to update one of the signal masks. So that the mask of the KLT2 can now properly reflects the state of the ULT and now it can start to handle the signals.
(9) Performance of Handling UL and KL Masks
The actual signals can be rare to happen compares to the need of updating the signal masks. So the updates for signal masks are the common case for performance improvement. This is because whenever we would have a certain critical portion of the code, we would first disable the signal and then enable the signal. However, in most of these cases, the signal doesn't really occur.
In order to make the common case cheap, we just apply the updates of the signal mask for the UL signal masks, and actually, the system call for updating the KL signal masks tends to be avoided. With respect to that, we have to make the actual signal handling a little bit more complex than what we have discussed.
6. Linux Supporting For Multithreading
(1) The Definition of Task
Like all OSes, Linux has an abstraction to represent the processes. And the main abstraction it uses to abstract the main execution context is called the task. And this abstraction is represented via a structure called task_struct. A task is exactly the execution context of a KLT. It is also direct to know that a single-threaded process has only 1 task, while a multi-threaded process can have many tasks.
(2) Source Code of task_struct
Our following discussion is based on the Linux kernel v3.17 and you can find the task_struct source code from the file sched.h at here (from line 1190 to line 1551). A brief version of this structure is as follows,
struct task_struct {
/* some codes ... */
pid_t pid;
pid_t tgid;
int prio;
volatile long;
struct mm_struct *mm;
struct files_struct *files;
struct list_head tasks;
int on_cpu;
cpumask_t cpus_allowed;
/* some other codes ... */
}Each task is identified by a task identifier called pid (or process ID, because of historic reasons although it can be misleading). If we have a single-threaded process, then pid and the actual process ID will be the same. Whereas, if we have a multi-threaded process, then we will have several pids for this process for these tasks. The tgid (group ID) is actually the very first pid that we have created for this process and it is the same as the actual process ID.
The task_struct also contains a data structure of listed tasks by tasks , so that we can easily refer to all the tasks of the process.
Unlike the SunOS, Linux doesn’t have one continuous PCB. Instead, the process state is always represented by references of to data structures like the memory management data structure mm_struct and file management data structure files_struct. This design makes it easy for tasks to share some portions of the address space.
(3) Task Creation
The Linux uses the clone function to create a task and the manual of this function can be found here. An arbitrary synopsis is,
clone(function, stack_ptr, sharing_flags, args)The sharing_flags is the most important portion of this function and the flag parameter is used to specify which portion of the state of a task will be shared between a parent and a child task. It has to do with the sharing of parent task_struct info with the child.
If flags are set, then it is like creating a new thread since a new thread shares the parent’s address space and only has its own stack and registers. When the flags are cleared, it is like creating a new process since a new process doesn’t share the parent’s information, it copies them.

(4) Process Forking in Multi-Threaded Process
Moreover, for forking a new process in a single threaded process, we actually copy with same address space. However, if we fork a new process in a multi-threaded process, then the new process will only contain a portion of the parent’s address space.
This also has lots of discussions, but it is beyond the scope of the present series.
(5) Linux Threading Model
The current implementation of a Linux threading is called Native POSIX Threads Library (NPTL). This is a one-to-one (1:1) model, so there will be a KL task for each of the ULTs. Because the NPTL is a 1:1 model, the kernel can see the information of each ULT. So the kernel traps become cheaper (the user to kernel level crossing can be much faster) but we pay a cost more resources. Because modern architectures have more resources to use, so it would not be a problem anymore.
The NPTL implementation actually replace an earlier threading mode called LinuxThreads, which is a many-to-many model. This design is quite similar to the one that is described in Solaris papers.