Operating System 14 | Event-Driven Model with the Flash Server Example, Experiment Design, Metrics…
Operating System 14 | Event-Driven Model with the Flash Server Example, Experiment Design, Metrics, and Results

- Recall: Boss-Worker Model Vs. Pipeline Model Performance
Let’s recall the boss-worker model and the pipeline model for multithreading systems. Suppose we have 11 tasks and 6 working threads for each model. A worker in the boss-worker model takes 120ms to complete a task, while each stage in the pipeline mode takes 20ms.
Let’s compare the performance of these two models.
For the boss-worker model, we have 1 boss thread and 5 worker threads. In order to handle these 11 tasks, we need at least ([11/5]+1) * 120 = 360ms.
For the pipeline model, because we have to fill the pipeline at the beginning, 6*20 = 120 ms is taken for completing the first task. Then each of the other tasks will take only 20 ms more for completion. So in conclusion, we need 120 + 10*20 = 320 ms for finishing all the tasks.
Then the average execution time for these two models would be,
- For the boss-worker model, the avg. execution time should be
360/11 = 32.72 ms - For the pipeline model, the avg. execution time should be
320/11 = 29.09 ms
Now, let’s consider another performance metric, the completion time for each task. The completion time for a thread is defined as the time it takes from the start of the program and the completion of this task. Take the pipeline model as an example, the first task completes at 120 ms, the second task completes at 140 ms, etc.
Then the average completion time for these two models would be,
- For the boss-worker model, the avg. execution time should be
(5*120 + 5*240 + 360)/11 = 196 ms - For the pipeline model, the avg. execution time should be
(120 + 140 + 160 + ... + 320)/11 = 220 ms
So, when we are thinking about comparing the performance, we should specify the metrics used to evaluate the performance. In the example above, if we consider the average execution time, we should pick the pipeline model. However, if we consider the average execution time, we should pick the boss-worker model.
2. Performance Metrics
(1) Reasons for Using Threads
We have known that the threads are quite useful for us, and here are some reasons why these threads can be useful.
- Parallelization: the threads can be used to parallelize problems so that we can gain some speedups
- Hot Cache: the threads allow us to benefit from a hot cache because we can specialize what a particular thread is doing on a given CPU
- Efficiency: because different threads can share the same address space, the memory footprint for a multi-threading system is reduced. What’s more, different threads are easier to synchronize with each other compared with communication between the processes. The threads are useful even on the signal CPU because it allows hiding the latency of the I/O operations by context switch to other threads.
(2) The Definition of the Performance Metrics
Ideally, metrics should be represented with values that we can measure and quantify. The definition of the term metrics according to Webster’s, for instance, is that it's a measurement standard. In our analysis of systems, a metric should be measurable, it should allow us to quantify a property of a system so that we can evaluate the system’s behavior or at least compare it to other systems.
(3) The Features of the Performance Metrics
To check whether or not it is a metric, we have to consider the following features.
- the metrics should be measurable (i.e. execution time)
- if the metrics can not be measurable, they should have a quantifiable property
- the metrics are associated with the system (i.e. implementation of a particular problem)
- the metrics can be used to evaluate the system behavior (i.e. the utilization improvement of the hardware compared with the others)
(4) Examples of Performance Metrics
So far in the lesson, we mentioned several useful metrics. For instance,
- Execution time
- Throughput
- Request rate
- CPU utilization
But there are also many other useful metrics to consider,
- Wait time: the user may not just care when they will get an answer, but they may also care when their job will actually start being executed
- Platform efficiency: although throughput helps evaluate the utility of a platform, if we are the owners of a data center, we also care bout the platform efficiency. The reason for this is that we have to spend money to run the machines, to buy more servers, so it's important to have a good ratio, so the platform efficiently will capture that.
- Performance per dollar: if we are considering buying the next greatest hardware platform, then we can think about whether the cost that we will pay extra for that new piece of hardware will be compensated with some impact on the performance that we are seeing
- Performance per watt: we are also concerned about the amount of power (watts) that can be delivered to a particular platform or the energy that will be consumed during the execution. This is because we have to pay for the power of running the machine
- Percentage of SLA (Service Level Agreement) violations: because enterprise applications will give typically SLAs to their customers. This is an agreement like “you will get a response within 3 seconds”. Sometimes, the SLA for the enterprise can be more subtle than that. For example, a service like Expedia has an SLA with its customers (i.e. Delta Airlines, American Airlines) that it will provide the most accurate quote for 95% of the flights that are being returned to customers. Thus, a metric like the percentage of SLA violations would capture that information.
- Slack in the application: for instance, humans cannot perceive more than 30 fps (frames per second), so making sure that there are at least 30 fps so that the users don’t start seeing some random buffering pauses during the video
- Client-perceived Performance: except for the request rate and the wait time, a metric that is really concerned about is the client-perceived performance (the service is performing well or not).
- Aggregate performance: the aggregate performance metric tries to average the execution time for all tasks or average the wait time for all tasks, or maybe even this would be a weighted average based on the priorities of the tasks
- Resource usage or average resource usage: similar to the CPU utilization, there are a number of other resources that we may be concerned about, memory, file system, so the storage subsystem
(5) Obtain Measurable Quantity of the Metrics
Ideally, we will obtain these metrics or gather these measurements by running experiments using real software deployments on the real machines using real workloads.
However, sometimes that really not an option, we cannot wait to actually deploy the software before we start measuring something about it or analyzing its behavior. In those cases, we have to resort to experimentation with some representative configurations that in some way mimic as much as possible (i.e. on the workload, the machine type, the aspects of the real system). This can be realized by using some simulation software.
(6) The Definition of Testbed
If we choose to simulate the metrics, it requires viable settings where one can evaluate a system and gather some performance metrics about it. We refer to these experimental settings as a testbed. So the testbed tells us where were the experiments carried out and what were the relevant metrics that were measured.
(7) More Thoughts on the Reasons for Using Threads
So now, if we go back now to our question about the reasons for using threads, the answer can not be that simple at this time. When we are considering whether or not threads are useful, we have to think about the metrics we took into consideration. Whether or not using threads may depend on,
- metrics
- workload (different number of tasks)
- algorithms we use (for graph processing)
- file systems (for handling file patterns)
- etc.
Thus, whether or not threads are useful really depends on the context we made.
3. Example: Flash Web Server Implementation
(1) Methods for Providing Concurrency
To understand when threads are useful, let’s start by thinking about what are the different ways to provide concurrency. So far we have discussed two methods to provide the concurrency operations,
- multiple threads (MT)
- multiple processes (MP)
In addition, for this part, we will introduce a new method for providing concurrency,
- event-driven model (EDM)
Our discussion will be based on the implementation of a simple webserver Flash and it is a must for us to refer to the paper Flash: An Efficient and Portable Web Server by Vivek. We use the example of a web server because it is important to be able to concurrently process client requests.
(2) Working Routine of A Simple Web Server
Before we continue, let’s talk about the steps involved in the implementation of a simple HTTP web server. Remember this is very similar to the GETFILE server that we have implemented for the project 1. So the steps in a simple web server are,
- Web server accepts connection
- Client/Browser sends request
- Web server reads request
- Web server parse request
- Web server find the file requested
- Web server computes respond header
- Web server sends header
- Web server reads file and sends data repeatedly until data completely transfered
- End of service
The basic sequential steps for serving a request for static content are also illustrated and described by Figure 1 in the Flash paper by Vivek Pai,

(3) Multi-Process (MP) Web Server
One easy way to achieve concurrency is to have multiple instances of the same process and that way we have a multi-process (MP) implementation. This implementation is also illustrated by Vivek Pai’s paper,
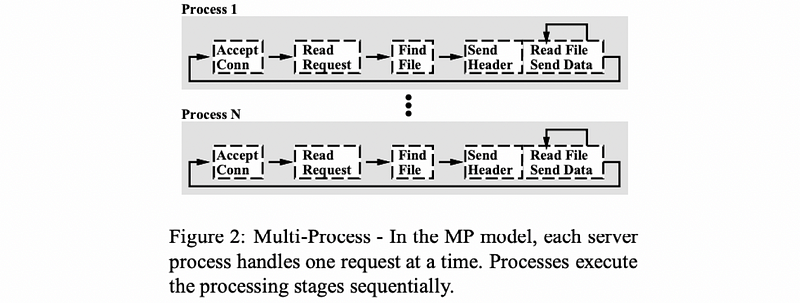
The benefit of this approach is that it is simple to implement because we can directly fork the initial process to spawn more processes once we developed the sequential steps for one process.
However, the downside of this method is that we have to allocate memory for every one of the processes, and this will ultimately put a high load on the memory subsystem and will hurt performance. Also, there will be a high cost of context switching among processes. In addition, it can be rather expensive to maintain a shared state across processes because of the communication mechanisms and the synchronization mechanisms that are available across processes.
(4) Multi-Threaded (MT) Web Server
An alternative to the multi-process model is to develop the web server as a multi-threaded (MT) application. Again, the following illustration is taken from Figure 3 of Pai’s Flash paper,
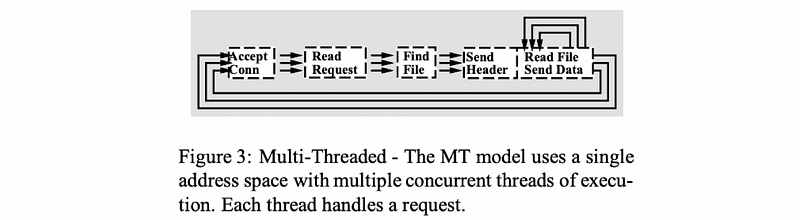
Basically, we have two approaches to implement this MT web server. One is to treat all the threads equally as workers, the other is to use a boss-worker model.
As it is described in the paper, every single one of the threads executes all the steps, starting from the accept connection call to completely sending the file. Thus, we will then have multiple execution contexts for multiple threads within the same address space, so every single one of the threads is processing a request.
Another approach to implementing this multi-threaded web server is by a boss-worker model where a single boss thread performs the accept connection and every single one of the worker threads performs the remaining operations, from reading the request to completely sending the file.
The benefits of this method are,
- memory efficiency: because threads share the same address space, the memory requirement will be much lower compared with the MP method
- shared states: threads don’t have to perform system calls in order to coordinate with other threads as the MP method does
- cheap context switch: because the context switching can be done at the multi-threading library level, it is relatively cheap for us
However, there are also some downsides for this method,
- complicated for implementation: the downside of the approach is that it is not so simple and straightforward to implement the MT program
- needs synchronization: also, synchronization tools (i.e. mutex and condition variables) are needed when different threads are accessing/updating the shared address space or the shared states
- needs OS’s underlying supports on threads: although all of the modern OS are regularly multi-threaded, it is not the case back to the time of the Flash paper (i.e. FreeBSD 2.2.6 at that time only supports ULTs without KLTs)
(5) Single-Process Event-Driven (SPED) Model Web Server
Now let’s talk about an alternative model for structuring server applications that perform concurrent processing. The model we’ll talk about is called the event-driven model. The application is implemented in a single address space, there is basically only a single process and a single thread of control. Then it is called a single-process event-driven model (SPED). Here is the illustration of this model and this is taken from Vivek Pai’s Flash paper as well,
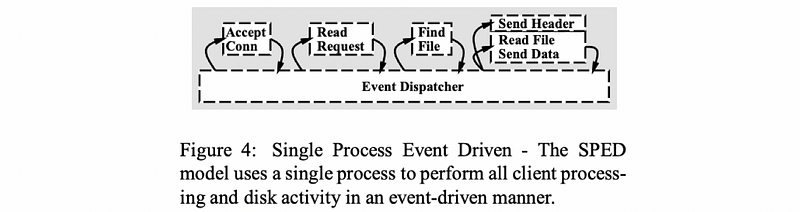
Now, let’s then analyze some of the main components of the SPEDM,
- Event Dispatcher
The main part of the process is an event dispatcher that loopingly looks for the incoming events. Then based on those events, the dispatcher invokes one or more event handlers. The events including things like the receipt of a request, the completion of send, the completion of a disk read operation, and etc.
The dispatcher has the ability to accept any of these types of notifications. And then based on the notification type, invoke the appropriate handler. So in that sense, it operates very much like a state machine.
- Event Handlers
The event handlers are called after the dispatcher receives a particular notification. Invoking a handler for a single-threaded process simply means to jump to the appropriate location in the process’ address space where the corresponding handler is implemented. At that point, the handler execution can start.

(6) Concurrency For SPED
In the MP models and MT models, to achieve concurrency, we would simply add multiple execution contexts. If we have fewer CPUs than context, then we would have to context switch among them.
The way that EDM achieves concurrency is by interleaving the processing of multiple requests within the same execution context.
Now let’s see an example. Suppose we have a request for client C1. After that,
- Step 1: the connection event handler is called by the dispatcher and the accept operation gets processed.
- Step 2: the actual request message gets processed and the message gets parsed
- Step 3: the files are extracted so now we actually need to read the file. We initiate I/O from the reading-file handler
At this moment, the request for client C1 is waiting on disk I/O to complete because it takes time for memory accessing.
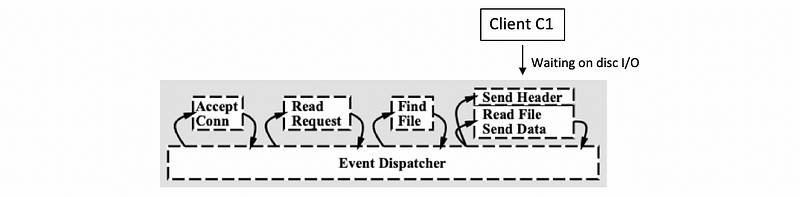
Meanwhile, suppose that two more requests have come in, so client C2 and C3 have sent requests for connections. Let’s say the C2 request was picked up first, the connection was accepted, and now for the processing of C2, we need to wait for the actual HTTP message to be received. Assume the processing of C2 is waiting on the request message to be received.
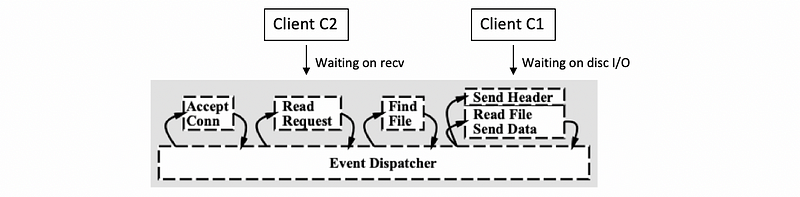
And let’s say C3, its request has been accepted and is currently being handled, so the C3 request is in the accept-connection handler.
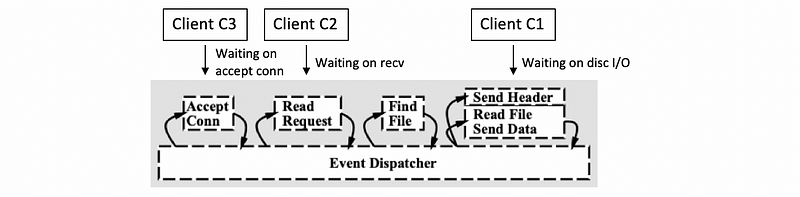
Some amount of time later the processing of all of these three requests has moved a little bit further along. Then we may find out that the execution context turns out to be,
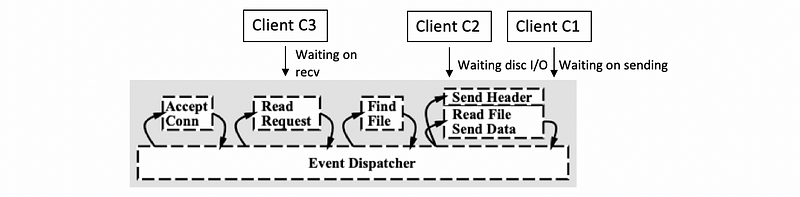
Thus, although we have only one execution context with only one thread, we can also have concurrent execution of multiple client requests that happen to be interleaved. So even if we have a SPED model, there can be multiple client requests being handled at the same time.
(7) Why SPED Works?
In the SPED, a request will be processed in the context of a single thread as long as it doesn’t have to wait. Whenever a wait needs to happen then the execution thread will switch to servicing another request. As a result, the latency for waiting is hidden.

If we have multiple CPUs, the event-driven model will still make sense, especially when we need to handle more requests than the number of CPUs.
(8) SPED Implementation
We have known that both the sockets (for support network) and the files (for supporting disk I/O) are some sorts of OS abstractions, and they are actually identified by the identical data structure called file descriptors (FD). Thus, any of the events in the execution context of this web server is actually an input on any of the FDs that are associated with.
To determine which FD has an input, the Flash paper use the select() system call. This system call allows a program to monitor multiple file descriptors, waiting until one or more of the file descriptors become “ready” (or “input possible”) for some class of I/O operation. A file descriptor is considered ready if it is possible to perform a corresponding I/O operation without blocking.
However, there are also some other system calls that can be used to monitor multiple file descriptors, like poll() or epoll(). The problem with both the select and poll system call is that they really have to scan through a potentially long list of FDs before they can determine which FD has an input. However, commonly, very few FDs will actually have an input, so a lot of that search time will be wasted. The epoll system call is provided for eliminating some of the problems of select and poll , because a lot of the high-performance servers that require high data rates and low latency would use this kind of mechanism today.
(9) SPED Evaluation
The benefits of the event-driven model really come from its design including,
- single address space: saves the memory resource
- single flow of control: this makes it easy for us to implement
- lower overheads: no need for context switching.
- no synchronization: no need for shared access to variables
However, there’s still a problem with the SPED model. If one of the handlers issues a blocking I/O call to read data from the network or from disk, the entire event-driven process can be blocked. Let’s see how to deal with this problem.
(10) Blocking Solution 1: Asynchronous I/O Operations
One way to circumvent this problem is to use asynchronous I/O operations.
The asynchronous I/O operations have two properties,
- decide how to collect and return data: when the I/O system call is made, the kernel captures enough information about the I/O operation, and where and how the data should be returned once it becomes available
- proceed to execute and come back later: asynchronous I/O operations calls also provide the caller with an opportunity to proceed to execute something and then come back at a later time to check if the results of the asynchronous operation are already available. For instance, the processor to a thread can come back later to check if a file has already been read and the data is available in a buffer in memory or in the buffer.
(11) Asynchronous I/O Operations Requirements
To implement synchronous I/O operations, one necessary requirement is that the OS kernel should be multi-threaded. So while the caller thread continues execution, another kernel thread does all the necessary work and all the waiting that's needed to perform the I/O operation, to get the I/O data, and then to also make sure that the results become available to the appropriate UL context.
Also, asynchronous operations also require supports from the actual I/O devices. For instance, the caller thread can simply pass some request data structure to the device itself, and then the device performs the operation and the thread, at a later time, can come and check to see whether the device has completed the operation.
(12) Asynchronous I/O Operations Problem
The problem with asynchronous I/O calls is that they weren’t ubiquitously available in the past (especially at the time for the Flash paper), and even today they may not be available for all types of devices.
(13) Blocking Solution 2: AMPED Architecture
To deal with the blocking problem, Vivek Pai’s paper proposed the use of helpers. The following illustration is Figure 5 taken from the paper.
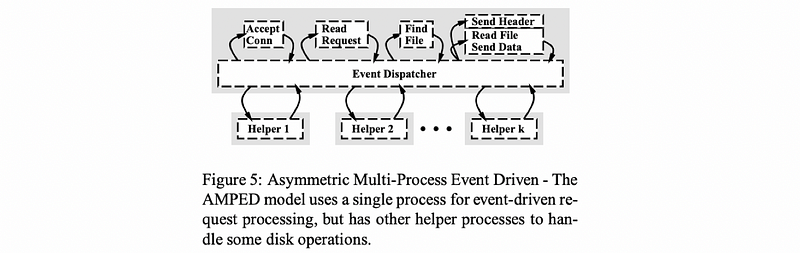
Instead of using a SPED model, we add some helper processes (or threads) that help us handle the disk operations. At the time of the writing of the paper, another limitation was that not all kernels were multi-threaded, so basically, not all kernels supported the one-to-one model that we talked about. In order to deal with this limitation, the decision in the paper was to make these helper entities processes. Then, because this model now has multiple processes, it is now called an asymmetric multi-process event-driven (AMPED) architecture. It is called “asymmetric” because the helper threads execute all the I/O operations while the main thread performs everything else.
When a disk operation is necessary, the event dispatcher instructs a helper process via. a socket-based interface or an inter-process communication (IPC) channel called a pipe. When a blocking happens for an I/O operation, the helper will be blocked, and the main event dispatcher can still be executing.
(14) AMPED Evaluation
The key benefits of the asymmetric model that we described are,
- deal with the potential blocking problem of the SPED model
- concurrency with a smaller memory requirement: we can finally achieve concurrency by AMPED instead of the normal MP or MT models, where each process/thread has to perform the whole request. So the memory requirement will be much less significant.
The downside are that,
- The AMPED model can not be arbitrarily used for many applications (except for the server applications)
- there are also some complexities with the routing of events in multi-CPU systems
(15) Features for the Flash Server
We will now talk about the features of the Flash paper,
- an event-driven web server that follows the AMPED model
- helper processes are used for disk reads
- just returns static files (because this is the old fashioned web 1.0 technology)
- helper-dispatcher communication via pipes
- dispatcher checks if a file in the main memory by
mincore - helper reads files from the memory by
mmapcall
Although the dispatcher’s check by mincore seems unnecessary, it actually results in big savings because it prevents the full process from being blocked if it turns out that a blocking I/O operation is necessary.
(16) Additional Optimization for Flash
- application-level caching: the files don’t need to be repeatedly looked up whenever we need to find the file. We also cache the header and the file path.
- scatter-gather support: the header and the actual data don’t have to be aligned, one next to the other in memory, they can be sent from different memory locations, so there is a copy avoided
At the time the paper was written, these optimizations were pretty novel and in fact, some of the systems they compared against did not have some of these things included.
(17) Example of the Apache Web Server
The apache web server is a popular modern open-source webserver and now let’s give a brief introduction of this server.
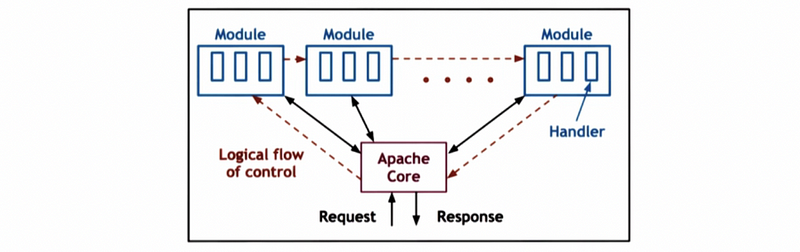
- Apache Core
The Apache core component provides basic server-like operations like accepting connections and managing concurrency.
- Modules
The various modules correspond to different types of functionality that are executed on each request. Specific Apache deployment can be configured to include different types of modules. For instance, the server can have certain security features, some management of dynamic content, or etc.
- Logical Flow of Control
The flow of control is sort of similar to the EDM that we saw, for instance, each request ultimately passes through all the handlers.
- MP + MT Model
Apache is a combination of an MP and an MT model. Each process is internally a multi-threaded boss-worker threading model. In addition, the number of processes can also be dynamically adjusted.
3. Experimental Methodology
(1) Comparing Criteria
In the Flash paper, the experiments are designed so that they can make stronger arguments about the contributions that the authors claim about Flash. Before we achieve a good experimental design, we have to ask ourselves about what we want to compare. So before we start, let’s think about the following questions,
- Define Comparision Points: what is the system we want to compare?
- Define Inputs: what workload will be used?
- Define Metrics: how will we measure performance?
(2) Comparision Points For the Flash Paper
Now, let’s see what we were comparing in the Flash paper,
- an MP version of the same kind of Flash processing (1 thread per process)
- an MT version that follows the Boss-Worker model
- a SPED model that we discussed first
In addition, we will also compare with two existing web server implementations,
- Zeus (SPED model with 2 processes)
- Apache (at the time Apache v1.3.1 was an MP configuration)
However, in the end, we would like to compare every single one of all these implementations with Flash,
- Flash (AMPED model)
(3) Workloads/Inputs For the Flash Paper
- Realistic Request Workload
To define useful inputs, they wanted workloads that represent a realistic sequence of requests because that's what will capture the real distribution of web page accesses over time
- Controlled Workload for Reproduction: Trace-based approach
To repeat the experiment with this same pattern of accesses, they also used a trace-based approach where they gathered traces from real web servers, and then they replayed those traces so as to be able to repeat the experiment with the different implementations. Therefore, different implementations will be evaluated against the same trace.
In the paper, the traces used were gathered at Rice University where the authors of this paper are from. These traces are called,
- CS Web trace: (LARGE) represents the Rice University web server for the Computer Science Department and it includes a large number of files and doesn’t really fit in memory
- Owlnet trace: (SMALL) a web server that hosted a number of student web pages and it was much smaller, so it would typically fit in the memory of a common server
In addition to these two traces, they also used,
- Synthetic workload: this is generated by a synthetic workload generator. With the synthetic workload generator, as opposed to replaying these traces of real-world page access distributions, they would perform some best or worst type of analysis or run some what-if questions, like what-if the distribution of the web page accesses had a certain pattern, would something change about their observations.
(4) Metrics For the Flash Paper
Finally, let’s look at what are the relevant metrics that the authors picked in order to perform their comparisons.
- Bandwidth: means the total amount of useful bytes, the unit of this metric is bytes per second or megabytes per second or similar
- Connection Rate: measures the ability of concurrent processing. This metrics is defined as the total number of client connections that service over a period of time.
Both of these metrics were evaluated with respect to the file size. For a larger file size, we can obtain higher bandwidth because the connection cost can be amortized. However, the more work that the server will have to do for each connection because of a larger file, the more negative impacts on the connection rate.
(5) Experimental Results For Best Case Numbers with Synthetic load
- Input: Synthetic load, N requests for the same file. This is the best case because the clients will not be asking for the same file every time. Because the file will be in cache, we don’t have to pay too much for disk I/O.
Now, let’s examine the result.
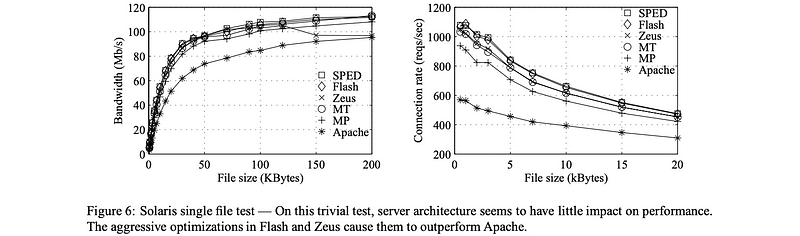
So our observations are,
- For all of the curves, initially, when the file size is small, bandwidth is low, and as the file size increases the bandwidth increases. So all of the implementations have very similar results.
- SPED is really the best model. That’s expected because it doesn’t have any threads or processes among which it needs to context switch.
- Flash is similar but it performs that extra check for the memory presence. In this case, because we are requesting the same file, there’s no need for blocking I/O, so none of the helper processes will be invoked. That’s why we see a little bit lower performance for Flash.
- Zeus has an anomaly, its performance drops a little bit after 100 bytes. This has to do with some misalignment for some of the DMA operations.
- For the MT and the MP models, the performance is slower because of the context switching and extra synchronization.
- Apache is the worst because it doesn’t have any optimizations that the others implement.
(6) Experimental Results For Realistic Workloads
Since real clients don’t behave like this synthetic workload, we also need to have a look at what happens with some of the realistic traces, the Owlnet and the CS trace.
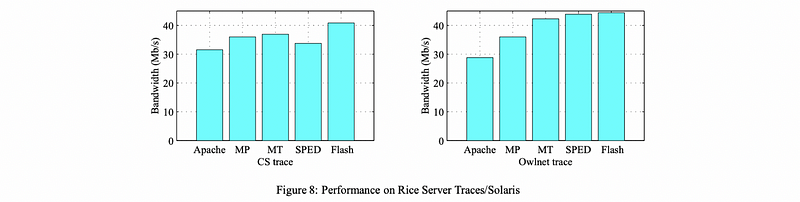
So our observations are,
- Owlnet Trace
Owlnet trace is very similar to the best-case performance with SPED and Flash being the best, and then MT, MP, and Apache dropping down. This is because that the Owlnet trace is a small trace, and most of it will fit in the cache. So we’ll have a similar behavior like what we had in the “best” case.
The reason why Flash surpasses the SPED is that, sometimes, the blocking I/O is required. Given the blocking I/O possibility SPED will occasionally block, whereas in Flash the helper processes will resolve the problem, we will therefore achieve a better result for the Flash.
- CS Web Trace
Because the CS trace is a larger trace, most requests will require a disk I/O operation and it is not going to fit the cache.
Since the SPED does not support asynchronous I/O operations, the performance of it drops significantly.
What’s more, we see that the MT model is better than the MP model. The main reason for that is that the MT implementation has a smaller memory footprint, which leads to more memories for caching files. It is also because the context switching between threads is much cheaper than processes.
In this case, we can also see that the Flash server performs best because,
- it has the smallest memory footprint with MP and MT
- no need for explicit synchronization
- helper threads for handling blocking I/O operation
In both of those cases, Apache performed worst.
(7) Experimental Results For Optimization
Let’s try to understand if there’s really an impact of the optimizations performed in Flash.
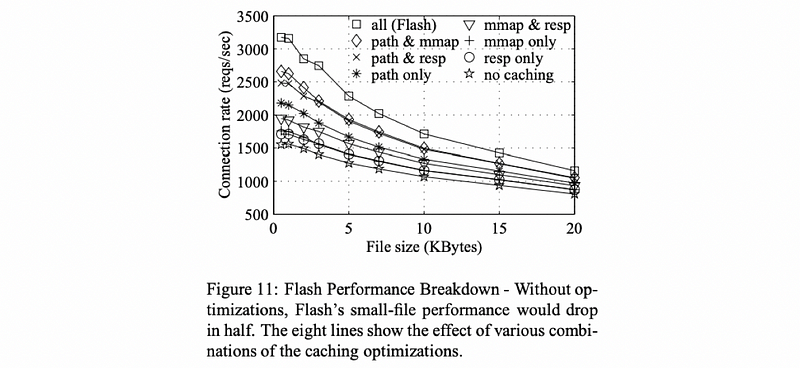
The performance that is gathered with Flash without any optimizations is the bottom line. While the final line at the top includes all of the optimizations. Thus, in conclusion, we can know that these optimizations for caching are indeed very important.
In both of the previous results, Apache performed worst. This is because Apache would have been impacted if it had integrated some of these same optimizations as the other implementations.
(8) Result Summary
Here’s a summary of the results above.
- When the data is in cache: SPED > AMPED Flash >> MT/MP
- With the disk-bound workload: AMPED Flash >> MT/MP > SPED