Operating System 15 | Midterm Review
Operating System 15 | Midterm Review

- Operating System Concepts
(0) Abstraction Vs. Arbitration
- Abstraction
Software that hides lower level details and provides a set of high-level functions. This is because the code needed to control peripheral devices is not standardized.
- Arbitration
The set of rules in a computer’s operating system for allocating the resources of the computer. It allows its peripheral devices or memory to be run by more than one user.
(1) OS Key Roles
- Direct Operational Resources
OS controls the resources of operational resources like CPU, memory, peripheral devices.
- Enforce Working Policies
OS manages fair resource access and imposes certain limits.
- Mitigates difficulty of complex tasks
OS simplifies and abstracts the view of the underlying hardware that’s observed by the applications that are running on that particular platform.
(2) OS Elements
- OS Abstractions
Concepts the OS uses to manage privileged components.
- OS Mechanisms
Mechanisms are used by abstractions to accomplish tasks.
- OS Policies
Policies determine how mechanisms are used.
(3) OS Designs
- Monolithic OS
With all the management codes implemented in the kernel.
- Modular OS
All the management codes can be added to the kernel if needs.
- Microkernel
A kernel requires only the most basic primitives.
Example 1-1. Specify the following statements to OS abstractions (A), OS mechanisms (M), or OS policies (P).
- A process or thread that the OS can execute.
- The OS represents communication endpoints as sockets.
- Which parts of data will be removed from memory.
- Files as data organization on the disk by OS.
- To open or write to a file.
- A process can wait for incoming connections on sockets via accept().
- To create or schedule a process to run on the CPU.
- Memory pages used to mapping the memory.
- The OS allocates a range of memory for a data structure.
- A mutex that can be used to lock the critical section.
- A condition variable that allows more fine-grained controls.
Ans:
A
A
P // by LRU or EDF
A
M
M
M
A
M
M
M
Example 1-2. Select all the TRUE statements.
- Memory management mechanism might use different policies depending on the situation
- Optimize for the common case answers questions like where will the OS used
- A trap instruction is performed to switch from kernel mode to user mode
- User-level thread library is the interface for applications to operating system communications
- OS is an interface between the hardware and application programs
- Generally, the system calls are functions written in C and C++
- Open, Close, Read, Write are some of the most prominently used system calls
- Signals is a mechanism for the operating system to pass notifications to the applications
Ans:
T
F // not answers, but based on the answer of
F // from user mode to kernel mode with no privilege
F // system calls are the interfaces
T // apps <-> syscalls <-> OS <-> hardwares
T
T
T
Example 1-3. Fill in the blanks of with Monolithic, Modular, and Microkernel.
- Size: ____________ > _____________ > _____________
- Resource-intensive: ____________ > _____________ > _____________
- Portablility: ____________ > _____________ > _____________
Ans:
Size: Monolithic > Modular > Microkernel
Resource-intensive: Monolithic > Modular > Microkernel
Portablility: Modular > Monolithic > Microkernel
Example 1-4. For the following options, indicate if they are examples of abstraction (B) or arbitration (R).
- Allocate CPU time for different user-level threads
- Distributing memory between multiple processes
- Supporting different types of speakers
- Interchangeable access of a hard disk or SSD
- Arbitrate access to a shared device
Ans:
R // because OS can directly allocate CPU time
R // because OS can directly allocate memory
B // OS uses drivers for abstracting different speakers
B // OS uses file abstraction for access a hard disk
R // an arbitrate access means a direct access
The key for answer this type of question is that you need to determine whether the OS abstracts a hardware or it accesses the hardware directly or arbitrarily.
Example 1-5. Which of the following are likely components of an OS? Check all that apply.
- [ ] File editor
- [ ] File system
- [ ] Device driver
- [ ] Cache memory
- [ ] Web browser
- [ ] Schedular
Ans:
[ ] File editor
[✓] File system
[✓] Device driver
[ ] Cache memory
[ ] Web browser
[✓] Schedular
Note that OS can not directly manage cache and it is actually managed by the hardware.
2. Threads and Processes Concepts
(1) Process Creation
fork: creates a new process with the same content of the parentexec: rewrite the content of a process with some other program
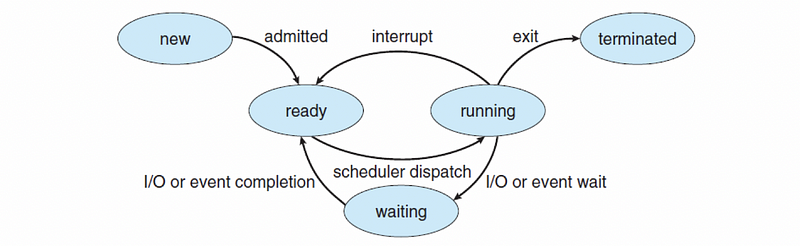
(2) Process and Thread Life Cycle
- PLC
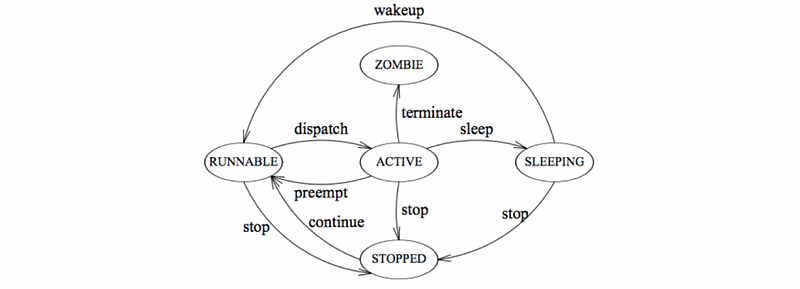
- TLC
(3) Process and Thread Execution Context
Process-wide Items:
- Virtual to physical memory address mappings
- Global variables
- Open files
- Child processes
- Pending alarms
- Signals
- Signal handlers
- Accounting information
Thread-specific Items:
- Program counter
- Thread-specific register values
- Signal mask
- Stack pointer
- Stack
(4) Process and Thread Context Switch
- Direct Cost: the number of cycles that have to be executed to load/store all the values from the process control blocks to/from memory
- Indirect Cost: caused by cache missing problems like cold cache or cache pollution
(5) Intro to Inter Process Communication (IPC)
There are two models of IPC:
- Shared-memory Based Communication: need synchronisation (e.g. mutex, cv, …). Cost for synchronisation setups.
- Message-passing Communication: asynchronously or synchronously send/recv message. Cost for the approach implementation.
Example 2-1. How is a new process created? Select the best option.
- only via fork
- only via exec
- only via fork followed by exec
- only via exec followed by fork
- via fork or exec followed by fork
- via fork or fork followed by exec
- via exec or exec followed by fork
- via exec or fork followed by exec
Ans:
via fork or fork followed by exec
- The term
fork followed by execmeans that we first callfork, and then we callexec. exec followed by forkwill callexecfirst. Then the program contentexecwill be replaced by some other program and theforkis never called.
Example 2-2. Specify the following statements refer to which process states they are entering at the moment. The states are New (N), Ready (R), Running (RUN), Terminated (T), and Waiting (W).
- Once the process has been created
- Once the process has been allocated and initialized
- Once the OS performs admission control
- Once the process has been dispatched to the CPU
- Once the process gets scheduled to run on the CPU
- Once the process is interrupted by some other process
- Once the process is preempted and context switched to another process
- Once the process starts waiting on a signal
- Once the process issues an I/O operation
- Once an I/O operation completes for the process
- Once the process created via the
forkcall (means initialized) - Once the process has its time slice expired
Ans:
N
R
R
RUN
RUN
R
R
W
W
R
R
R
Example 2-3. DELETED
Example 2-4. DELETED
Example 2-5. The CPU is able to execute a process when the process is in which state(s)?
- Running
- Waiting
- Ready
- New
Ans:
Running
Ready
It is a little bit tricky for this problem because we the CPU is able to execute a process in the ready state. The reason why it is not being executed is that this process is waiting for the scheduler to allocate a CPU for this process. So it is basically the moment when process is scheduled to run after some execution.
Example 2-6. Do the following statements apply to processes(P), threads(T) or both(B)?
- Can share a virtual address space
- Take longer to context switch
- Have an execution context
- Usually result in hotter caches when multiple exists
- Make use of some communication mechanisms
Ans:
T
P
B
T
B
3. Mutex and Condition Variable
Example 3-1. In the (pseudo) code segments for the producer code and consumer code, mark and explain all the lines where there are errors.
- Global Section
int in, out, buffer[BUFFERSIZE];
mutex_t m;
cond_var_t not_empty, not_full;- Producer Code
1. while (more_to_produce) {
2. mutex_lock(&m);
3. if (out == (in + 1) % BUFFERSIZE)) // buffer full
4. condition_wait(¬_full);
5. add_item(buffer[in]); // add item
6. in = (in + 1) % BUFFERSIZE
7. cond_broadcast(¬_empty);
8.
9. } // end producer code- Consumer Code
1. while (more_to_consume) {
2. mutex_lock(&m);
3. if (out == in) // buffer empty
4. condition_wait(¬_empty);
5. remove_item(out);
6. out = (out + 1) % BUFFERSIZE;
7. condition_signal(¬_empty);
8.
9. } // end consumer codeAns:
- Producer Code
line 3: using if instead of while
line 4: condition_wait doesn’t specify a mutex
line 7: using signal instead of broadcast
line 8: missing the mutex_unlock
- Consumer Code
line 3: using if instead of while
line 4: condition_wait doesn’t specify a mutex
line 7: should signal not_full
line 8: missing the mutex_unlock
Example 3-2. DELETED
Example 3-3. Does the following code suffice to protect a critical section with two processes p0 and p1 running on separate processors on a two-processor shared-memory machine? That is, does it meet all of the requirements for protecting a critical section? Variable turn is a shared variable.
/* Code for p0 */
// non-critical-section code
while(turn != 0) {}
critical section
turn = 1;
// non-critical-section code
/* Code for p1 */
// non-critical-section code
while(turn != 1) {}
critical section
turn = 0;
// non-critical-section code
Ans:
Yes
Example 3-4. Suppose that two threads have several critical sections, protected by different mutexes. The following are two of those critical sections, with their protection code.
/* code segment 1 */
lock(m1);
… /* code protected by m1 */
lock(m2);
… /* code protected by m2 */
unlock(m2);
unlock(m1)
/* code segment 2 */
lock(m2);
… /* code protected by m2 */
lock(m1);
… /* code protected by m1 */
unlock(m1);
unlock(m2)
Is that a sensible way to protect this critical code? If not, how to protect this critical code?
Ans:
No, because there is a deadlock problem
We have two ways to protect this critical code,
- Method 1
/* code segment 1 */
lock(m1);
… /* code protected by m1 */
lock(m2);
… /* code protected by m2 */
unlock(m1);
unlock(m2)
/* code segment 2 */
lock(m1);
… /* code protected by m2 */
lock(m2);
… /* code protected by m1 */
unlock(m1);
unlock(m2)
- Method 2
/* code segment 1 */
lock(m1);
… /* code protected by m1 */
unlock(m1);
lock(m2);
… /* code protected by m2 */
unlock(m2)
/* code segment 2 */
lock(m1);
… /* code protected by m1 */
unlock(m1);
lock(m2);
… /* code protected by m2 */
unlock(m2)
Example 3-5. A shared calendar supports three types of operations for reservations:
- read
- cancel
- update
Requests for cancellations should have priority above reads, who in turn have priority over new updates. In pseudocode, write the critical section enter/exit code for the read operation.
Ans:
cs_enter_read {
mutex_lock(m);
read_waiting++;
while (read>0 || cancel>0 || update>0 || cancel_waiting>0)
wait(read_cv, m);
read++;
read_waiting--;
mutex_unlock(m);
}
cs_exit_read {
mutex_lock(m);
read--;
if (cancel_waiting>0) signal(cancle_cv);
else if (read_waiting>0) signal(read_cv);
else if (update_waiting>0) signal(update_cv);
mutex_unlock(m);
}4. Boss-worker Model and Pipeline Model
Example 4-1. An image web server has three stages with average execution times as follows:
- Stage 1: read and parse request (10ms)
- Stage 2: read and process image (30ms)
- Stage 3: send the image (20ms)
Suppose we can create a maximum of 6 threads. You have been asked to build a multi-threaded implementation of this server using the pipeline model. Using a pipeline model, answer the following questions:
a. How many threads will you allocate to each pipeline stage to create a balanced pipeline?
b. What is the expected execution time for 100 requests (in sec)?
c. What is the average throughput of the system in Question 2 (in req/sec)? Assume there are infinite processing resources (CPU’s, memory, etc.).
d. Suppose we have a non-balanced pipeline model with 2 threads assigned to all three stages. What is the expected execution time for 100 requests (in sec)?
e. Which performs better, a balanced pipeline or a non-balanced pipeline?
Ans:
// a.
stage 1 (10ms) = 1 thread
stage 2 (30ms) = 3 threads
stage 3 (20ms) = 2 threads
// b.
exe_time_1 = (10+30+20) + (100-1)*10 = 1050 ms = 1.05 s
// c.
throughput = # of reqs/exe_time = 100/1.05 = 95.24 req/s
// d.
It is eqvilent to the situation that we have 2 same pipelines, and each of them has a longest stage time of 30ms.
exe_time_2 = (10+30+20) + (100/2-1)*30 = 1530 ms = 1.53 s
// e.
It depends on our metrics. With the execution time, we can conclude that the balanced pipeline has a better performance.
Example 4-2. Suppose we have a boss-worker model and a pipeline model, and we assign 11 tasks and 6 working threads for each model. A worker in the boss-worker model takes 120ms to complete a task, while each stage in the pipeline mode takes 20ms.
Answer the following questions.
For the boss-worker model,
a1. The execution time is __________ ms.
b1. The throughput is __________ req/sec.
c1. The average execution time is ____________ ms.
d1. The average completion time is __________ ms.
For the pipeline model,
a2. The execution time is __________ ms.
b2. The throughput is __________ req/sec.
c2. The average execution time is ____________ ms.
d2. The average completion time is __________ ms.
Ans:
a1. 3*120 = 360 ms
b1. 11/0.36 = 30.56 req/sec
c1. 360/11 = 32.73 ms
d1. (120*5 + 240*5 + 360)/11 = 196.36 ms
a2. 20*6 + 10*20 = 320 ms
b2. 11/0.32 = 34.38 req/sec
c2. 320/11 = 20.09 ms
d2. (120 + 140 + 160 + ... + 320)/11 = 220 ms
Example 4-3. DELETED
5. Solaris Papers
Example 5-1. For each of these data structures, list at least two elements they must contain:
- a. Process
- b. LWP
- c. Kernel-threads
- d. CPU
Ans:
All the possible solutions are,
a. Process:
pointer to List of KLTs
pointer to address space
user credentials
list of signal handlers
user structure
b. LWP
UL register values
system call arguments
signal masks
resource usage information
profiling pointers
c. Kernel-threads
kernel registers
dispatch queue links
stack pointers
scheduling class
pointer to the next KLT
d. CPU
pointer to currently executing KLT
pointer to idle KLTs for the CPU
dispatch handling information
interrupt handling information
Example 5-2. DELETED
Example 5-3. Specify whether the following data structures in the Solaris papers are SWAPPABLE (S) or NON-SWAPPABLE (N).
procstructureuserstructure- kernel thread structure
- LWP structure
- Stack
- CPU structure
Ans:
N
S
N
S
S
S
Example 5-4. Based on the mechanisms described in the Solaris papers,
a. Answer the following questions with one-to-one(1:1), many-to-one(M:1), or many-to-many(M:N)
- a1. Linux uses a __________ threading model.
- a2. Solaris uses a __________ threading model.
- a3. LWPs have a __________ mapping pattern to the kernel-level threads.
- a4. LWPs have a __________ mapping pattern to the user-level threads.
b. Answer the following questions with Multiprocessing, Multithreading, Synchronization, and Visibility
- b1. Solaris provides configurations for concurrency because of ____________.
- b2. Solaris designs LWPs because of ____________.
- b3. Solaris implements full-fledged threads for interrupts because of ___________.
c. Answer the following questions with DISPATCH and SLEEP.
- c1. When a thread is runnable, it will be put on the _________ queue.
- c2. When a thread blocks on a local synchronization object, it will be put on the ___________ queue.
- c3. When the ____________ queue is empty, the LWP goes back to idling.
d. Answer the following questions with PARK and IDLE.
d1. When an unbound thread exits and there are no more RUNNABLE threads, the LWP becomes __________.
d2. When an unbound thread becomes blocked and there are no more RUNNABLE threads, the LWP becomes __________.
d3. When an bound thread blocks on a process-local synchronization variable, the LWP must __________.
Ans:
a1. 1:1
a2. M:N
a3. 1:1
a4. M:N
b1. Multithreading
b2. Visibility
b3. Synchronization
c1. DISPATCH
c2. SLEEP
c3. DISPATCH
d1. IDLE
d2. PARK // note that PARK is faster than IDLE
d3. PARK
6. The Flash Paper /* a bug in this line, if you can see this, just ignore*/
6. The Flash Paper
(1) Summary of Different Servers
a. SPED
- Perfect for the situation when cache/memory resource is large
- Perfect for requesting a single small file many times (Cache hit, best case numbers)
- Good for requesting different small files (Owlnet trace, some I/O blockings)
- Bad for requesting different large files (CS trace, many I/O lockings)
- I/O operation blocking issues add overheads (only for cache miss)
- Can’t make full use of multicores (only one event dispatcher process)
b. Flash (AMPED)
- Perfect for requesting different small/large files
- Not good for requesting a single small file many times (add cache checking overheads for helpers)
- Can’t make full use of multicores (only one event dispatcher process)
c. MP
- Good for multicore architectures (e.g. a quad-core platform, not perfect because the memory cost for MP is higher than MT)
- Cost for context switching
- Cost for synchronization tools (e.g. mutex, condition variable)
- Cost for process execution contexts in memory (more cache for process execution contexts, less cache for the file data)
d. MT
- Perfect for multicore architectures (e.g. a quad-core platform)
- Cost for context switching
- Cost for synchronization tools (e.g. mutex, condition variable)
- Cost for process execution contexts in memory (more cache for process execution contexts, less cache for the file data)
e. Zeus (SPED model with 2 processes)
- Cost for some misalignment for some of the DMA operations
f. Apache (an unoptimized MP configuration)
- Worst because it doesn’t have any optimizations that the others implement
(2) Advanced Implementation AMTED
If we convert the AMPED model to the AMTED (async multi-threaded event-driven) model, we can expect that the performance will be improved because the cost for thread memory and the cost for thread context switch is much lower. This is actually a follow on work that actually does to the Flash.
Example 6-1. Here is a graph from the paper Flash: An Efficient and Portable Web Server, that compares the performance of Flash with other web servers.
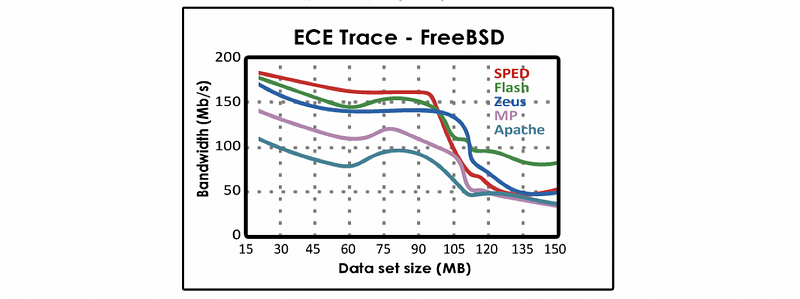
For data sets where the data set size is less than 100 MB why does,
a. Flash perform worse than SPED?
b. Flash perform better than MP?
For data sets where the data set size is greater than 100 MB why does,
c. Flash perform better than SPED?
d. Flash perform better than MP?
Ans:
// a.
In both cases the dataset will likely fit in cache, but Flash incurs an overhead on each request because Flash must first check for cache residency. In the SPED model, this check is not performed.
// b.
When data is present in the cache, there is no need for slow disk I/O operations. Adding threads or processes just adds context switching and extra synchronization overheads, but there is no benefit of “hiding I/O latency”.
// c.
Because the dataset is large, it is not likely to fit in cache, and thus, the blocking I/O is required. Given the blocking I/O possibility SPED will occasionally block since the SPED does not support asynchronous I/O operations, whereas in Flash the helper processes will resolve the problem, we will therefore achieve a better result for the Flash.
// d.
When we should read from the memory, there is some needs for context switching to hide the I/O latency. However, the MP has a larger memory footprint, which leads to less memories for caching files. So Flash performs better than MP.
Example 6-2. DELETED
Example 6-3. If we have the MT GETFILE server for the project 1 and it is used for two differences,
- (i) many requests for a single file
- (ii) many random requests across a very large pool of very large files
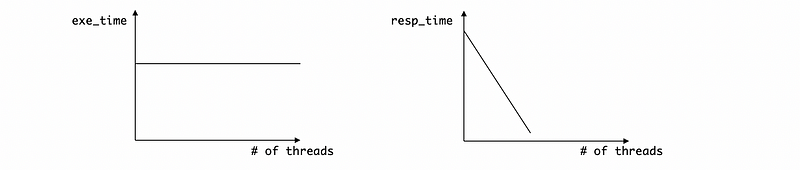
Sketch 2 hypothetical graphs for each of these two situations. One graph is used to show the average execution time for a request against the number of threads, the other is to show the average respond time for a request against the number of threads.
Ans:
For situation (i),
The file will be out of the cache and we have to do I/O operations if we keep increasing the number of the threads. This is because the execution contexts of threads take up the memory for the file. Thus, the average execution time will be higher when we need to conduct I/O operations.
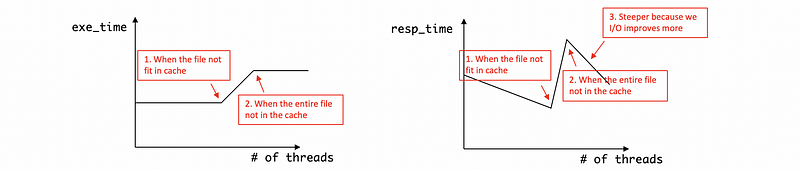
For situation (ii),
Because all the files are not fitted in cache initially and we have to operate I/O for each of them. So the average execution time and the average respond time will be higher at the beginning. But thanks to the help of increasing number of threads, we can finally have a relatively low average responding time because of concurrency.
7. Interrupts and Signals
Example 7-1. Operating systems’ (e.g. in Linux or UNIX in general) signals are: (select all that apply)
- an interface from the kernel to the user-level process
- a synchronous notification mechanism from the kernel to a process or a thread within the process
- an asynchronous notification mechanism from the kernel to a process or a thread within the process
- a way to notify a user-level thread waiting on a condition variable
- a way to notify many user-level threads waiting on a condition variable (e.g. via broadcast)
- invented so that the kernel can engage the user-level threading library scheduler
Ans:
- a synchronous notification mechanism from the kernel to a process or a thread within the process
- an asynchronous notification mechanism from the kernel to a process or a thread within the process
- invented so that the kernel can engage the user-level threading library scheduler // no sure, needs clarify
Note the other definitions are for,
OS provides an interface from the kernel to the user-level process
PThread signal function provides a way to notify a user-level thread waiting on a condition variable
PThread broadcast function provides a way to notify many user-level threads waiting on a condition variable
Example 7-2. Which of the following statements are TRUE. Select all that apply.
- Each instruction trap triggers an interrupt
- Peripherals may send interrupts to the processor
- A timer interrupt is a trap
- An external interrupt from a peripheral is called a trap
- Software interrupts are interrupts sent to the processor by the software
- Traps are being used for software interrupts
- Interrupts can be used for transition from user mode to kernel mode
- Interrupts can cause context switching
T // all traps are interrupts
T
F // timer interrupts are not traps
F // peripheral interrupts are not traps
F // by hardware, caused by software
T
T
T
Example 7-3. Which of the following statements are TRUE. Select all that apply.
- Processes may send each other signals by IPC
- Kernel may send signals internally
- Each signal is maintained by a single bit
- Linux syscall
killsends a signal - It is possible for an interrupt to result in a signal
- Both of the signals and interrupts can be masked
T
T
T
T
T // e.g. divide by zero
T
Example 7-4. Check all the components used for dealing with the signal mask visibility problem in each of the following situations. Note that 1 ULT (0) means that we have 1 ULT with a signal mask of 0, and 2ULT (0,1) means that we have 2 ULTs with signal masks of bit 0 and bit 1.
a. 1 ULT (0), 1 KLT (1)
- a1. lightweight user-level threading library
- a2. signal handler table
- a3. signal handling routine
- a4. system calls for changing signal masks
- a5. schedular
b. 2ULT (0, 1), 1KLT (1)
- b1. lightweight user-level threading library
- b2. signal handler table
- b3. signal handling routine
- b4. system calls for changing signal masks
- b5. schedular
c. 2ULT (0, 0), 2KLT (1, 1)
- c1. lightweight user-level threading library
- c2. signal handler table
- c3. signal handling routine
- c4. system calls for changing signal masks
- c5. schedular
d. 2ULT (0, 1), 2KLT (0, 0)
- d1. lightweight user-level threading library
- d2. signal handler table
- d3. signal handling routine
- d4. system calls for changing signal masks
- d5. schedular
Ans:
// a.
a1, a2, a3, a4
// b.
b1, b2, b3, b5
// c.
c1, c2, c3, c4
// d.
d1, d4
7. Linux and MacOS
Example 7-1. Specify TRUE (T) or FALSE (F) for the following statements.
- The OS X has a hybrid kernel.
- The PThread library of Linux follows the 1x1 mapping model.
- Linux supports both one-shot signals and real-time signals.
- Linux uses the
clonecall to create a thread - Linux uses the
forkcall to create a thread - Linux is a monolithic kernel
- Linux can be modular
- Linux forking in a thread will create a process with its address space same to the parent
Ans:
T // Mach and BSD
T
F // only supports real-time signals
T
F // fork is used to create new process
T
T // Linux can be monolithic and modular
F // Only a portion is copied
Example 7-2. On a 64-bit Linux-based OS, which system call is used to,
- Create a process ____________
- Replace the execution context of the current process ____________
- Send a signal to terminate a process ____________
- Determine the termination of child process ___________
Ans:
fork
exec
kill
wait
8. More Details
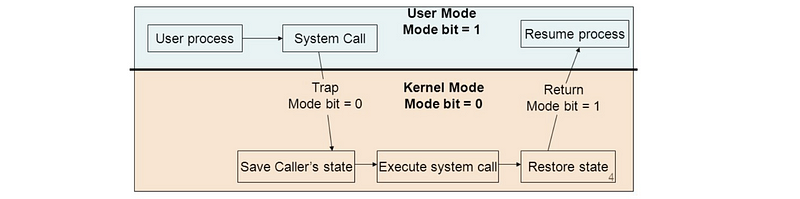
(1) User-Kernel Mode Crossing
- Step 1-1. Start with the user mode (code = 1)
- Step 1-2. UL process needs a hardware access, raise a system call
- Step 1-3. UL process passes arguments and data to that system call
- Step 2-1. Change the code to kernel/privileged mode (code = 0)
- Step 2-2. Kernel sees the system call and get its arguments and data
- Step 2-3. Kernel context switch to the location of the system call and execute it
- Step 2-4. Kernel returns the result to the UL process and context switch to its original content
- Step 1-4. Change the code to user mode (code = 1)