Operating System 20 | Introduction to Synchronization, Spinlock Implementation, and Spinlock…
Operating System 20 | Introduction to Synchronization, Spinlock Implementation, and Spinlock Alternatives

- Introduction to Synchronization
(1) Synchronization Metaphor
Before we introduce the implementation of a synchronization construct, let’s see a metaphor. Suppose you and other students are working on a group project together and you would like to synchronize the process of your work. In fact, you may do the following things to celebrate with others,
- Repeatedly check if you can continue: Are you done?
- Send signals to let others continue: Hey, I am done.
Sometimes, you may find it is terrifying to celebrate with your groupmates if they don’t respond to your messages. What you have to do is to keep waiting for others to respond and this hurts your performance.
(2) Spinlocks: Repeatedly Check
The spinlock is something like a mutex, but they have some differences. The spinlock can also be used to protect the critical section as follows,
spinlock_lock(s);
// critical section
spinlock_unlock(s);
The way that spinlock differs from mutex is that when the spinlock is busy, the thread that is suspended at the moment is not block like mutexes. Instead, the thread will be spinning and continue running on the CPU repeated checking to see whether this lock becomes free. With mutexes, the thread will have relinquished the CPU and allowed for another thread to run.
(3) Semaphores: Repeatedly Check
Another synchronization construction in the OS kernel is called the semaphore and this is also similar to a mutex. However, a semaphore can be more generalized than a mutex. Semaphore is originally designed by E. W. Dijkstra, who was a Dutch computer scientist and also a Turing award winner.
Semaphores are represented initially via a positive integer number, and this value is treated as the maximum number of threads that can access the critical section simultaneously. If we wait for a semaphore when the value of it is non-zero, the present thread will proceed and the semaphore will decrement by 1. When the semaphore is zero, then the current thread will be spinning.
It is quite clear that we can thus have two kinds of semaphores,
- binary semaphore: when the semaphore is initialized by 1
- general semaphore: when the semaphore is initialized by a value of more than 1
After exiting the critical section, we will post to the semaphore, and this operation will increment the semaphore’s counter. For a binary semaphore, this is equivalent to unlocking a mutex.
(4) POSIX Semaphore API
In the POSIX semaphore API, we can use the following statements. If we want to use this API, we have to first include the semaphore.h header file.
#include <semaphore.h>
The semaphore variable can be defined by sem_t , and it should be initialized after it is defined. We will use the function sem_init to initialize it,
sem_t sem;
sem_init(&sem, pshared, count);
The pshared flag is used to assign whether this semaphore is shared within a single process or it can be shared for all the processes. When this value is set to 1, it means that all the processes can access this semaphore. The count is clearly the initial value we would like to assign to this semaphore. If we want to have a binary semaphore, this argument should be set by 1.
Then, based on our discussions above, we can simply know that the critical section can be protected by,
sem_wait(&sem);
// critical section
sem_post(&sem);
(5) Semaphore Vs. Mutex
Finally, let’s see why the semaphore can be treated as a more generalized mutex. We have known that a mutex works within a single process and it will only allow a single thread to enter its critical section. As a result, we can find out that the mutex is a specific kind of semaphore. We can construct a mutex by,
sem_t mutex;
sem_init(&mutex, 0, 1);
Then this semaphore will act like a mutex.
(6) Reading/Writing to Shared files
Suppose we have several threads that would either read (means accessing without modifying) or write (means accessing with modifying) to a shared file. Then how can we synchronize between these threads?
Let’s suppose we are currently reading from the file, then if there is a reading access from another, we don’t have to block this thread because all these two reads can happen simultaneously. However, when there’s a thread with a writing request, we have to block it until we finish our reading.
What’s more, when if the thread is initially writing to the file, then it will simply block all the access to the file because both reads and writes will have wrong results without synchronization.
Therefore, we can find out that for different types of accesses, the reading threads can have shared accesses, while the writing threads can only have exclusive accesses. Because we have only one shared file in the critical section, have to use only one lock for this synchronization, and this specific lock used to synchronize reads and writes is called the reader/writer locks (aka. RW lock, rwlock).
(7) RW locks for Linux
The Linux OS provides us an in-built data type called rwlock_t for reader/writer locks. When we want to access and quit a reading section, we can use the provided interfaces read_lock and read_unlock. Similarly, when we want to access and quit a writing section, we can use the provided interfaces write_lock and write_unlock. These APIs are provided in the linux/spinlock.h header file.
#include <linux/spinlock.h>rwlock_t rwlock;read_lock(&rwlock);
// critical section: for reading
read_unlock(&rwlock);write_lock(&rwlock);
// critical section: for writing
write_unlock(&rwlock);(8) Monitors
What we have seen so far is that all these synchronizations require developers to pay attention to the use of the peer-wise operations lock/unlock, wait signal, etc. and these operations are significant causes of errors. Therefore, we would like to deal with the problem.
The monitor is a higher-level synchronization construct that helps. It will explicitly specify the shared resource, all the possible entry procedures (e.g. to differ reads and writes), and it will also specify any condition variables that potentially be used to wake up different types of waiting threads.
When performing certain types of access on entry, all of the necessary locking and checking will take place when the thread is entering the monitor. Similarly, when a thread is done with the shared resource and it’s exiting the monitor, all of the necessary unlock operations, checks, any of the signaling that’s necessary for the condition variables, all of that will happen automatically, will be hidden from the programmer.
Historically, monitors were included in the MESA language developed by SEROX PARC. Nowadays, Java also supports monitors. Every single object in Java has an internal lock and methods that are declared to be synchronized are entry points into this monitor. When compiled, the resulting code will include all of the appropriate locking and checking. The only thing is that notify() has to be done explicitly.
Monitors also refer to the programming style that uses mutexes and condition variables to describe the entry and exit codes from the critical section.
(9) More Synchronization Constructs
We have introduced some of the synchronization constructs like spinlock, semaphore, mutex, condition variable, RW lock, and monitor. Now, let’s talk about more constructs beyond them,
- serializer: make it easier to define priority, hide explicit use of condition variable
- path expressions: programmer specify regex captures the correct synchronization behavior
- barriers: a barrier will block threads until it figures all of them reach a certain condition. You can find a detailed explanation from this article.
- rendezvous points
- optimistic wait-free synchronization (RCU)
2. Spinlock Implementation
(1) An Incorrect Implementation
Now, let’s see a false implementation of the spinlock.
spinlock_init(lock):
lock = free; // 0=free, 1=busy
spinlock_lock(lock):
spin:
if (lock == free) lock = busy;
else goto spin;
spinlock_unlock(lock):
lock = free;
This is false because if we have two threads access the lock simultaneously when the lock is free, all of these two threads will be unlocked. This problem continues to happen even when we use a single while loop like,
spinlock_init(lock):
lock = free; // 0=free, 1=busy
spinlock_lock(lock):
while (lock == busy);
lock = busy;
spinlock_unlock(lock):
lock = free;
To deal with this problem, we need what are so-called hardware supported atomic instructions.
(2) Atomic Instructions
As the name of the atomic instructions implies, these instructions can only be accessed atomically supported by the hardware. In general, there are three common types of atomic instructions,
test_and_set: if fits the condition, then set the valueread_and_increment: get the value, and then increase itcompare_and_swap: compare the values, and then swap them
(3) Spinlock Implementation: by test_and_set
We can implement the spinlock simply by the test_and_set atomic instruction. The test_and_set function will first atomically check the value of the lock. Then if the lock is free (i.e. lock = 0), the value will be set to 1. Then the threads come after will know that the lock is currently busy and they should spin and wait.
3. Spinlock Alternatives
(1) Recall: Shared-Memory Multiprocessors
Before we move on to Anderson’s paper The Performance of Spin Lock Alternatives for Shared-Memory Multiprocessors, let’s first refresh the shared-memory multiprocessor systems.
In the past, all cores will communicate the coherence information through a single shared bus, but there will be a bottleneck of the performance because of the bus bandwidth.

Therefore, for a multicore system, it can be more reasonable if we use some interconnection links between cores for transferring the data. These links between the cores consist of a network called mesh,
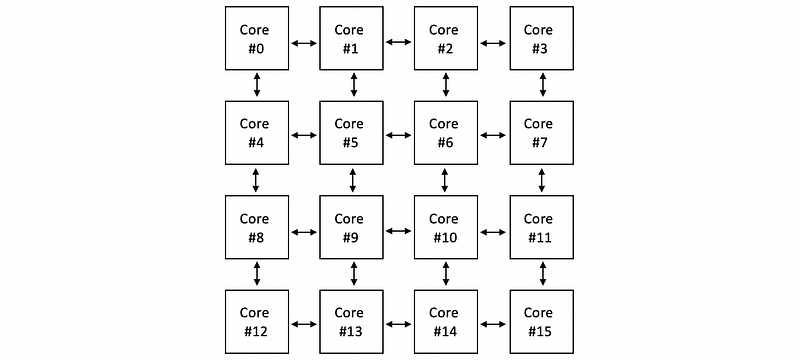
Because all these cores actually share 1 or more memories (DRAMs), they are also called the shared-memory CPUs (aka. shared-memory multiprocessors, symmetric processors, or SMPs). In addition, each of these CPUs in this kind of system can have caches. This is because the caches are faster so that we are able to hide the memory latency.
However, when the CPU performs a write to the memory, several things can happen,
- No-write to cache: because all the caches shared the data should be replaced now, the operation of writing to cache may not be allowed to happen. Instead, we may directly write to the memory and then invalidate all the previous copies of this memory location in the caches
- Write-through: there is another technique that the result will be writing both in the current cache and the memory. Then the all the previous copies of this memory location will simply be invalidated
- Write-back: We can also first write to the cache and invalidate all the previous copies of this memory location in others caches without writing to the memory. This is because the other caches can retrieve the data from the current cache instead of the memory for the reason that a memory I/O can be slow and inefficient. Only when the dirty block (means the block with the data not written to cache) is kicked out from the cache, we will write the data back to the memory.
(2) Cache Coherence: Software VS. Hardware
From the previous discussion, when we have an SMP system, the read and write to the memory is not that simple. We have to maintain cache coherence so that different caches will always have the same data of a specific memory location. There are several ways to maintain the cache coherence,
- Non-Cache-Coherent (NCC): NCC means that we actually support no hardware cache coherence and all these coherent operations should be adopted by the software.
- Cache-Coherent (CC): while on some other platforms (called cache-coherent platforms), the hardware can actually take care of all of the necessary steps to make sure that all the caches are coherent.
(3) Cache Coherence: Write-Invalidate Vs. Write-Update
The basic methods that are used for managing the cache coherence are called the write-invalidate (WI) and the write-update (WU). The method we have talked about when introducing the write-through and write-back is the write-invalidate method. Now, let’s discuss both of them,
- Write-Invalidate: the write-invalidate method means that if we write to the cache, all the blocks in other caches corresponding to the same memory location will be invalidated
- Write-Update: the write-update method means that if we write to the cache, all the blocks in other caches corresponding to the same memory location will be updated. We don’t use this quite much because this method requires a higher bandwidth after each write, which can be costly for the general performance.
(4) Implementing Atomic Instructions
If we all the atomic instructions to read from the cache, there can be multiple problems we have to maintain. We will have multiple CPUs with multiple threads, we have WU and WI protocol, we have latency on the chip, and etc. Given all these concerns, it is very difficult to know if a particular atomic is applied to the cache on one CPU to know whether or not on another CPU, another atomic is attempted against the cache value in that core.
For that reason, the atomic instructions are designed to bypass the caches and they can directly issue to the memory controller. The benefit is clear, all the threads can be easily synchronized without considering the cache coherence issues when we access the memory.
However, the downside is that the atomic instruction will therefore take much longer than a normal instruction because we can not benefit from cache reads. In addition, in order to guarantee atomic behavior, we have to generate the coherence traffic after we read/write from the memory. Even if the memory doesn’t change after the atomic instructions, we have to force a cache coherence procedure for some safety purposes.
(5) Spinlock Performance Metrics
Finally, before our discussion on the paper, let’s discuss the standard for a good spinlock.
- Latency: first, we want to have low latency for our spinlock. Ideally, we want to acquire a free lock immediately, but we have just mentioned that the atomic instructions can be quite slow. And if there are more operations, it takes some time before we acquire the free lock
- Delay: next, we want our lock to have a low waiting time, which means that we want to reduce the time when the current thread stops spinning and then acquire the lock that has just been freed
- Contention: also, we want to reduce the traffic on the shared bus/network. Both the actually atomic memory references and the coherence traffic should be considered.
However, there is a conflict between our goals. If we want to have lower latency and a lower delay, we have to send more messages to the shared bus/network so that we don’t have to read from the memory. So these attempts will result in a higher contention with more traffics.
(6) Performance of Test-and-Set Spinlock
Now, let’s look back to discuss the performance of a test-and-set spinlock. As we have discussed briefly, the test-and-set spinlock can be implemented as follows,
spinlock_init(lock):
lock = free; // 0=free, 1=busy
spinlock_lock(lock):
while(test_and_set(lock) == busy);
spinlock_unlock(lock):
lock = free;
The latency and the delay of this implementation are very low because the lock and unlock are simplest. We only have atomic instructions in for the locking process and the delay is also maintained by the minimum requirements with spinning continuously on the automatic instructions.
However, as long as the thread is spinning, every processor will repeatedly go on to shared bus/interconnected links to the memory location. This will create contention on the shared bus/interconnected links which will scare out other CPUs or it will even delay the thread with the critical section.
(7) Alternative Implementation #1: Test-Test-Set Spinlock
In the previous case, we have found out that the contention is caused because we have to execute the atomic test-then-set instruction in every spinning. One way to deal with this problem is that we can add another test before the atomic instruction and only for those we have to write to the memory, we will conduct the test-then-set instruction.
spinlock_lock(lock):
while (1) {
if (lock == free)
while(test_and_set(lock) == busy);
else
while(lock == busy); // wait for lock becomes free
}
Now, let’s consider the performance of this lock. For the latency and delay, this lock is okay but it is worse than the previous case because we do one extra check before we enter the atomic instruction.
But if we consider the intention problem, this lock is much better because we are now allowed to spin on the cache without accessing the memory. However, this conclusion is only made when we have a write-update coherent protocol. When we have a write-invalidate protocol, we should also read from the memory and what’s worse, we will generate invalidation traffic. As a result, the WI situation will become horrible.
(8) Alternative Implementation #2: Delay Spinlock
A simple idea to improve the intention is that we can add a delay time after the thread figures out that the lock is free. By this delay time, we will have more threads entering the while(lock == busy) loop instead of entering the while loop of while(test_and_set(lock) == busy) with atomic instructions which will result in higher contention.
Another question is that how can we pick the time for this delay? Actually, we have two methods. We can use either a statistic delay or a dynamic delay.
- static delay: means that we can assign the delay time with some static value (e.g. CPU ID). This is simple but it will cause some unnecessary delay under low contention
- dynamic delay: means that each process will pick a random delay value on the current perception of contention in the system. If we have low contention, then the delay time is chosen from a smaller range. However, if we have higher contention, then the delay time is chosen from a larger range. The number we can the contention problem in the system is that we can check the filed
test_and_setoperations. If thetest_and_setoperation fails, there’s a higher possibility of a higher contention.
spinlock_lock(lock):
while (1) {
if (lock == free)
while(test_and_set(lock) == busy);
else {
while(lock == busy); // wait for lock becomes free
delay();
}
}
The latency is okay because we have to perform one extra check before we acquire the lock, but that can be tolerated. However, the delay becomes much worse because now threads have to wait for a longer time because we add a new delay time. If there’s no contention at a time, the delay will be just a wait of the time.
(9) Alternative Implementation #3: Queuing Spinlock
The alternative lock described in Anderson’s paper is called a queuing lock or Anderson’s lock. The idea of this lock is that a queue of flags is used to control who gets to execute and what needs to happen when a critical section is complete. This method makes each thread acquire the lock at a different time once the lock is freed.
The array has N elements, where N is the number of processors in the system times the size of the cache lines, and every single one of the elements will have one of the two values (has_lock or must_wait). In addition, we will have two pointers, which will indicate the current lock holder (with has_lock) and the index of the last element in the queue queuelast. So the initialization of this queue would be,
init:
flags[0] =has_lock;
flags[1 ... N-1] =must_wait;
queuelast = 0; // global
When a new thread arrives at the lock, it will get a ticket from the lock, and then a new element will be added to the end of the queue. Since multiple threads may be arriving at the lock at the same time, we will clearly make sure that this queue should be maintained atomically. Therefore, this queue depends on some sort of read_and_increment reads, and these are less common atomic instructions that are not generally supported. So the lock function should be,
lock:
myplace =read_and_increment(queuelast);myplace%N
// spin
while (flags[] == must_wait);
// now in critical section// finally reset the entry in the queue for next threadmyplace%N
flags[] = must_wait;
Releasing the lock means that we have to change the value of the next element to has_lock in the array,
unlock:
flags[myplace%N + 1] = has_lock;
For the latency concerns, this method is much worse because we have to execute some more inefficient read_and_increment instructions. However, the delay is quite good because we can directly signal the next CPU/thread to run without waiting. From a contention perspective, this lock is much better than any other alternatives we have discussed because the atomic instruction read_and_increment is only executed once upfront and it is not part of the spinning code.
(10) Experimental Results
Finally, let’s see one of the results from the performance of the locks that are shown in Anderson’s paper.
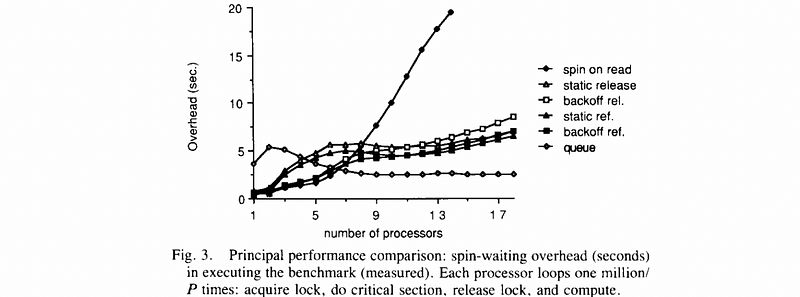
This figure is gathered from executing a program with multiple processes and each program contains a critical section that will be executed in a loop of 1 million times. The platform was cache-coherent with write-invalidate. The metrics computed was the overhead compared to an ideal performance with all the measurements bond to a theoretical limit.
So now let’s see the result when we have high loads with more threads/cores,
- queuing lock is the best one with the most scalable curve
- the test-test-set lock (i.e. spin on read) will perform worse because we have a very high contention of O(N²)
- the static delay locks (i.e. static release/ref.) are slightly better than dynamic delay locks (i.e. backoff release/ref.) since under high loads with static, we end up nicely balancing out the atomic constructions
However, for the lighter loads, we have,
- test-test-set lock performs pretty in this case because a spinlock will have low latency
- the dynamic delay locks perform better than the static delay locks because it has a lower delay
- queuing lock is the worst one because we have a pretty high latency because of the
read_and_incrementinstructions