Operating System 22 | Introduction of Virtualization, Virtualization Models, Hardware Protection…
Operating System 22 | Introduction of Virtualization, Virtualization Models, Hardware Protection, Processor Virtualization, Memory Virtualization, and Device Virtualization

- Introduction of Virtualization
(1) History of Virtualization
Virtualization is an old idea. It originated in the 60s at IBM when the norm of computing was that there were a few large mainframe computers that were shared by many users and many business services. In order to concurrently run very diverse workloads on the same physical hardware, without requiring that a single operating system be used for all of the o- applications for all of the possible purposes, it was necessary to come up with a model where multiple operating systems can concurrently be deployed on the same hardware platform.
(2) The Definition of Virtual Resources
With virtualization, each of the operating systems that are deployed on the same physical platform has an illusion that it actually owns the underlying hardware resources. Or at least some smaller portion of them. Therefore, each OS thinks that it owns the hardware resources, and these resources are called the virtual resources.
(3) The Definition of Virtual Machine
Each operating system together with its applications as well as the virtual resources that it pings at us is called a virtual machine, or VM for short. This represents a virtual machine because it is distinct from the physical machine that is natively managed by some software stack. Virtual machines are often referred to as guests such as guest VMs or also referred to as domains.
Classically, in Popek and Goldberg’s paper, the virtual machine is taken to be an efficient, isolated, duplicate of the real machine, which is supported by a virtual machine monitor (VMM). The VMM is actually the layer that enables VMs to exist.
(4) Characteristics for VMM
As a piece of the software, the virtual machine monitor has three essential characteristics,
- It provides an environment that is essentially identical to the original machine. This means that the VMM must provide some fidelity that the representation of the hardware visible to the VM matches the hardware that’s available on the physical platform
- Programs show at worse only minor decrease in speed. The idea is that if the VM is given the exact amount of resources as the physical machine, then the OS and the processes would be able to perform at the same speeds. Therefore, the performance of the VMs should be as close as the physical machine.
- VMM is in complete control of the system resources. This means that the VMM has full control to make any decisions. This doesn't mean that every single piece of hardware has to be inspected by the VMM, but VMM determines if a particular VM is to be given direct hardware access. Once those decisions are put in place, a virtual machine can not just change those policies. So another goal for the VMM is that it needs to provide safety and isolation guarantees.
(5) Reasons for Virtualization
There are actually some reasons for doing virtualization,
- consolidation: enables to run multiple operating systems on a single physical platform. It decreases costs and improves manageability.
- migration: once the OS in its applications is nicely encapsulated, it can be easy to migrate the OS and the applications from one machine to another. This provides us the availability of the system, and it also provides solutions that improve the reliability.
- other reasons: there are some other benefits for doing virtualization, like security, debugging, support for legacy OSs, and so on.
2. Virtualization Models
(1) Two Types of Virtualization Models
Before describing the technical requirements for virtualization, let’s take a look at the two main Virtualization models. The two popular models for virtualization are called bare-metal (aka. hypervisor-based) model and hosted model. They are also often referred to as type 1 for the hypervisor-based model and type 2 for the hosted model for virtualization solutions.
(2) Bare-Metal Virtualization (BMV)
In the bare-metal model, a VMM (or called the hypervisor) is responsible for the management of the physical resources, and it supports the execution of the entire virtual machine.

But this model has an issue with the device drivers. According to the model, the hypervisor must manage all possible devices, or stated differently, device manufacture now have to provide device drivers not just for the different operating systems, but also for the different types of hypervisors. This can be wasteful in practice.
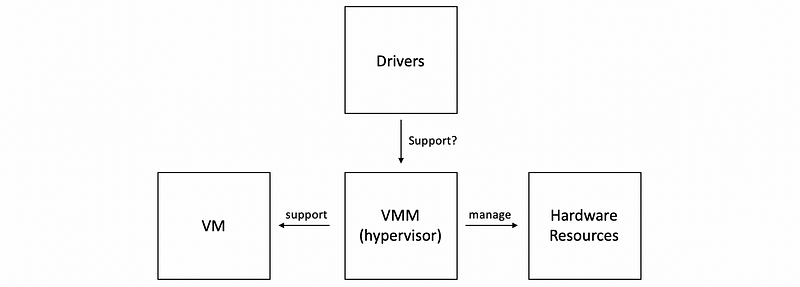
(3) Service VM
To eliminate this issue, the hypervisor model typically integrates a special virtual machine called service VM that runs a standard operating system and has full hardware privileges to access and perform any kind of hardware manipulation.
The privilege VM would,
- run all of the device drivers
- have control over how the devices on the platform are used
- run some other management tasks (e.g. how hypervisor allocate resources across VMs)
- run some other configuration tasks
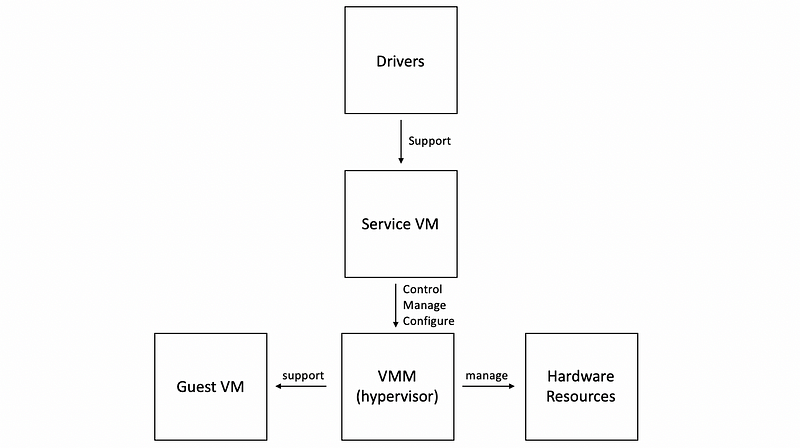
(4) Bare-Metal Virtualization Example #1: Xen
For both the open-source version and the version that’s supported by Citrix, VMs that are run in the virtualized Xen environment are referred to as domains. The organization of Xen is,
- domains: VMs
dom0: privileged domain, or service VMdomU: guest VMs- Xen: VMM or hypervisor
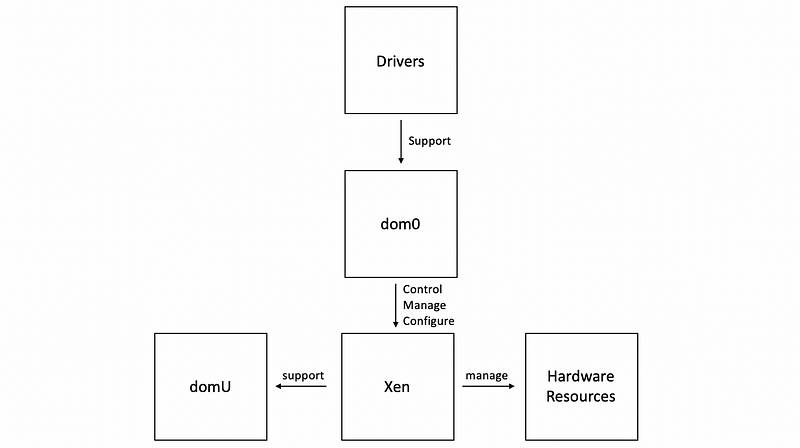
(5) Bare-Metal Virtualization Example #2: VMware ESX
Given that VMware and its hypervisors were first to market, VMware still owns the largest percentage of virtualized server cores.
For historical reasons, VMware is using an older model with all the drivers become part of the hypervisor. However, this is possible because of two reasons. Firstly, VMWare is mandated by the vendors so that they do provide the drivers for the different devices. Secondly, this is not as bad because VMware really targeting the server, and there will not be as many devices like the PC market.
To support a third-party community of developers, VMware actually also exports a number of APIs. And in the past, the ESX architecture was such that there was a control core based on Linux. But right now, all of the configuration-related tasks are configured via remote APIs.
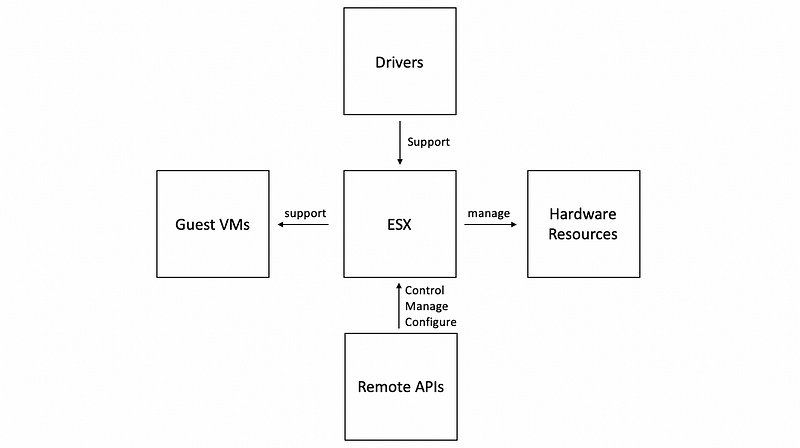
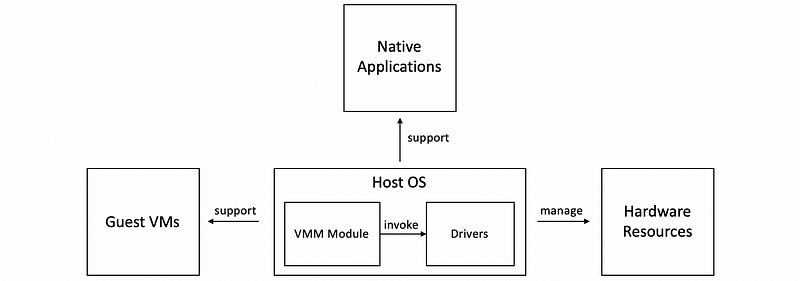
(6) Hosted Virtualization Model
The main difference between the bared-metal model and the hosted model is that, at the lowest level of the hosted model, there is a full-fledged host OS that manages all of the hardware resources.
The Host OS integrates a VMM module that is responsible for providing the virtual machines with their virtual platform interface and for managing all of the context switching scheduling, etc. In addition, this VMM module will invoke drivers or other components of the host operating system as needed.
There are several benefits of this model,
- Less functionality needs to be redeveloped for the VMM module because it can leverage all of the services and mechanisms that are already developed for the host OS.
- We can run guest VMs and native applications directly on the host operating system simultaneously.
(7) Hosted Virtualization Example: KVM
One example of the Hosted model is KVM, which stands for kernel-based VM, and this is based on the Linux OS. The support for running guest VMs is through a combination of the KVM module and a hardware emulator called QEMU, which is used as a virtualizer to provide identical hardware simulations like X86 Intel or AMD. This is because the intent of virtualization is to provide identical hardware, but it may be impossible for us to find the exact same hardware.
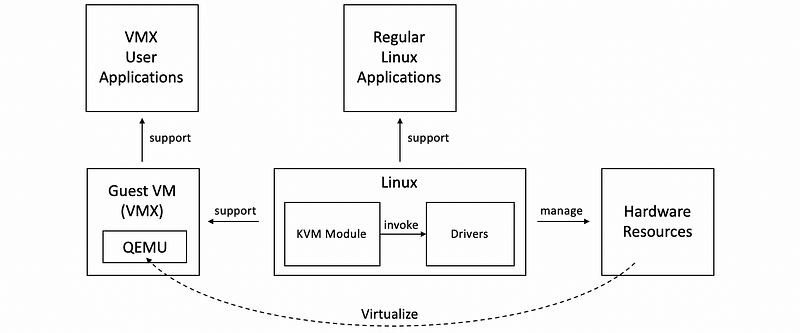
A huge benefit for KVM has been that it’s able to really leverage all of the advances that are continuously being contributed to the large Linux open-source community. Because of this KVM can quickly adapt to new hardware features, new devices, new security, bugs, or similar things.
In fact, the KVM Module was originally developed as a Linux module in order to allow regular use of Linux applications to take advantage of some of the virtualization-related hardware that started appearing in commodity platforms. All of the sudden, users realized that this can be useful to actually run guest VMs. And so three months later, KVM was an actual virtualization solution that was part of the mainstream Linux kernel.
3. Hardware Protection
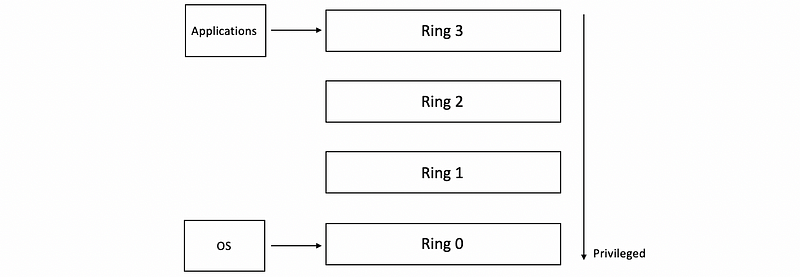
(1) Protection Levels for x86 Architecture
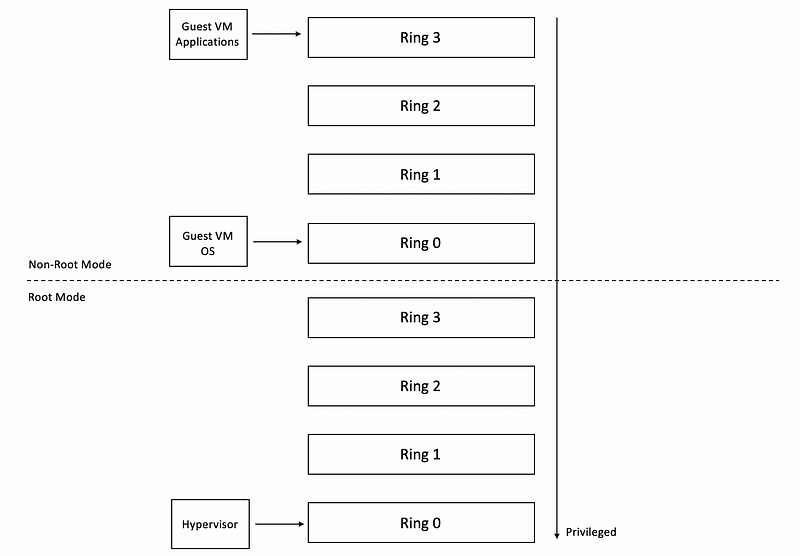
It is fortunate to observe that commodity hardware actually has more than two protection levels. Looking at the x86 architecture, there are 4 protection levels called rings.
- Ring 0 (OS): it has the highest privilege and can access all of the resources and execute all hardware-supported instructions, so this is where the OS would reside.
- Ring 3 (Apps): it has the lowest level of privilege, so this is where the applications would reside.
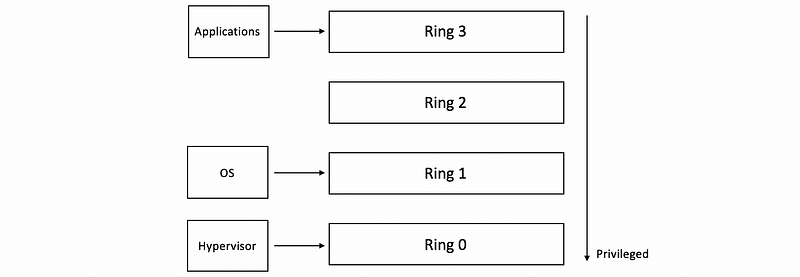
(2) Protection Levels for Virtualization
One way in which these protection levels can be used is to put the hypervisor now in ring 0, so that’s the one that has full control over the hardware, to leave the applications to execute at ring 3 level, and then the operating system would execute at ring 1 level.
(3) Protection Modes for x86 Architecture
More recent x86 architectures also introduce two different protection modes called the root mode and the non-root mode. Within each of these modes, the four protection levels exist, so there are two times these protection rings.
- Root Mode: the highest privileged mode with all of the operations are permitted, all hardware is accessible, all instructions can be executed.
- Non-root Mode: many operations will request root permissions
(4) Protection Modes for Virtualization
The ring 0 of the root mode is where we would run the hypervisor. In contrast, in non-root mode, because certain types of operations are not permitted, the guest VMs would execute in this non-root mode. Therefore, their applications will be running in ring 3 and their operating systems will be running at ring 0 privilege level in the non-root mode.
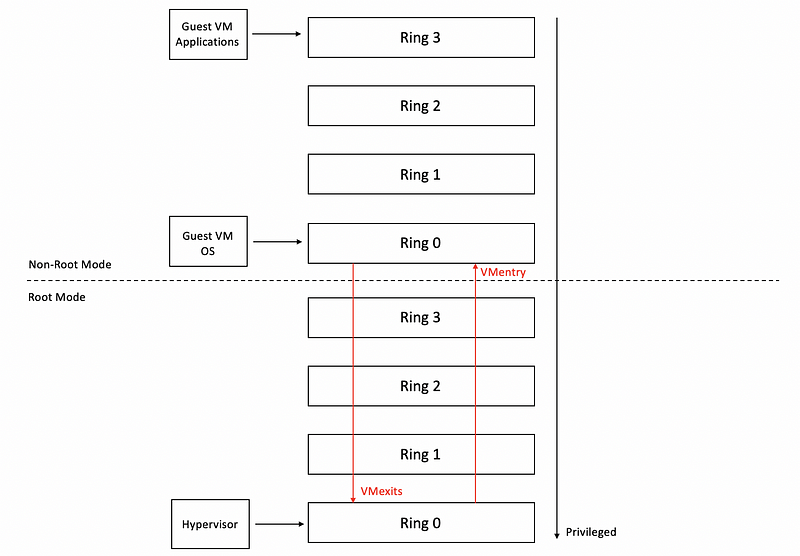
(5) Root-Non-Root Crossing: VMexits and VMentry
Sometimes the guest OS needs to perform some privileged operations, then we should pass the operation across the root-non-root boundary. Attempts by the guest OS to perform privileged operations are called VMexits. And these trigger a switch to this root mode and pass control to the hypervisor.
When the hypervisor completes its operation, it passes control back to the virtual machine by performing a VMentry which switches the mode into non-root mode, to ring 0, so that the execution continues.
4. Processor (CPU) Virtualization
(1) Trap-and-Emulate Technique
So now, let’s discuss what will happen when the guest OS starts executing the instructions.
We may have a question now. Could the guest instructions directly executed by the hardware concerning the protection issues? The answer to this question is yes, and the guest’s non-privileged instructions executed directly by the hardware. The VMM doesn’t interfere with every single instruction that is issued by the guest OS because one goal of the VM is efficiency and we want to achieve hardware speed. As long as the guest operating system and its applications operate within the resources that were allocated to them by the hypervisor, then everything is safe.
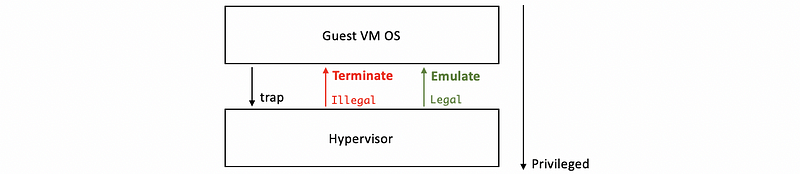
However, when we issue privileged instructions, things are quite different because the hypervisor should be involved for protecting the system. Whenever a privileged instruction gets accessed, then the processor causes a trap, and control is automatically switched to the most privileged hypervisor. At this point, the hypervisor can determine whether the operation is,
- illegal: if it shouldn’t be allowed, then the hypervisor can perform some action, for example, to terminate the VM
- legal: if it is allowed the hypervisor should perform the necessary emulation so that the guest operating system is under the impression that it actually does have control over the hardware. So from the guest's perspective, it should seem as if the hardware did exactly what it was expected to do given the instruction.
This trap-and-emulate mechanism is a key method on which virtualization solutions rely in order to achieve efficient CPU virtualization.
(2) Problem for Trap-and-Emulate Technique
Now, the trap-and-emulate technique seems good and beautiful for simulating processors for the guest VMs. However, in the 90s, the need to reapply virtualization solutions to the prevalent x86 architecture came up. And it turned out that there were certain problems with this model.
At the time, x86 platforms had just 4 rings. There wasn’t any support for root or non-root mode. And so the way to virtualize them would be to run the hypervisor in ring 0 and the guest OS in ring 1. It turned out that there were exactly 17 privileged instructions (expected illegal when issuing from ring 1, and expected legal when issuing from ring 0, e.g. POPF/PUSHF instructions) that did not cause traps if they were called from the ring 1 protection level or above. When these instructions are issued from ring 1 in the pre-2005 architecture, they just fail and the instructions pipeline is allowed to continue to the next instruction.
The problem with the situation that there is no trap because most real-world instruction sets, including x86, were not designed with virtualization in mind. As a result, there are privileged instructions that do not have any corresponding trap facility. So the control isn’t passed to the hypervisor, and the hypervisor has no idea that the OS wanted to change the interrupt status. Then the hypervisor will not do anything to change these settings.
At the same time, because the failure of the instruction was silent, the operating system, the guest OS doesn’t know that anything wrong happened. So the OS will continue its execution, assuming that correctly the interrupts were enabled or disabled as intended, which will result in a corrupt state or in a deadlock state. So clearly this is a major problem and makes this trap-and-emulate approach not applicable for this architecture.
(3) History of the Binary Translation Technique
One way to deal with the no trap problem is called binary translation. It is pioneered by professor Mendel Rosenblum at Stanford, and then this project is commercialized as VMware. VMware still owns by far the largest share of the virtualized cores in the server market.
Rosenblum later received the ACM Fellow reward, and in the recognition, he was specifically credited for reinventing virtualization. He served as VMware’s chief scientist for about ten years and now is back full time at Stanford.
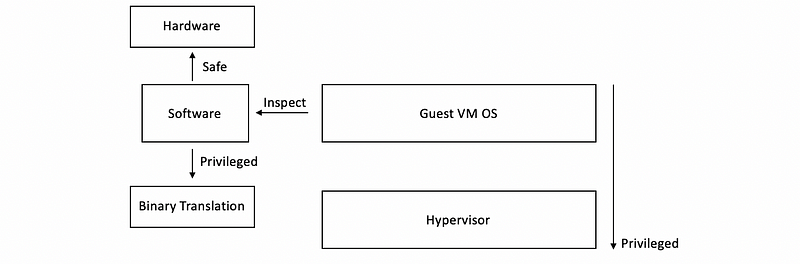
(4) Binary Translation Technique
The main idea of the binary translation is not difficult. Instead of depending on the processor itself to detect the privileged instructions and pass control over to the hypervisor or host, virtualization software inspects the instruction stream in software. When the software detects that we are issuing one of the 17 instructions, then the binary code of this instruction will be rewritten (or so-called translated) to some other codes. This translation should be done in a dynamic way because we may need some parameters when doing the translation. So a formal binary translation should have the following steps,
- The software will inspect the code blocks to be executed to see whether we have one of 17 privileged instructions
- If the instruction is safe (means that it is not one of 17 privileged instructions), then it is allowed to execute at hardware speeds
- If the instruction is one of the 17 privileged instructions, then the binary code of this instruction will be translated to some other instructions that avoid the undesired instructions, but in some way, emulates the desired behavior. This can possibly be achieved even by bypassing a trap to the hypervisor.
Certainly, binary translation adds overheads and the number of mechanisms is incorporated specifically in VMware’s solution for improving the efficiency of the process. These techniques include,
- caching code fragments
- distinguish binary for instruction code
- etc.
(5) Full Virtualization Vs. Paravirtualization
We have discussed that what we want for an ideal VM is that we want to have exactly the same copy of the guest OS and nothing needs to be modified so that the guest OS does not know that it is running on a virtual machine. This is called full virtualization.
However, a totally different idea is to give up on the goal of running unmodified operating systems. Instead, the primary goal is to offer a virtualization solution that offers performance and avoids some of the overheads that may be associated with any of the complexities that are necessary to support unmodified guests. In contrast to full virtualization, this is called paravirtualization.
(6) Hypercall Approach
With paravirtualization, the guest OS is modified so that it now knows that it’s running in a virtualized environment on top of a hypervisor as opposed to on top of native physical resources. A para-virtualized guest OS will not necessarily try to directly perform operations, which it knows that they will fail. And instead, it will make explicit calls to the hypervisor to request the desired behavior. These calls to the hypervisor are called hypercalls, which behave in a way like the system calls. So we have the following steps of making a hypercall,
- package the context info
- specify the desired hypercall
- trap to VMM
This approach of paravirtualization was originally adapted and popularized by the Xen hypervisor. And it was a popular virtualization solution and originally was an open-source hypervisor that started as a research project at the University of Cambridge in the UK. This was later commercialized as XenSource and XenSource is now owned by Citrix. But there still remains a lot of activity in the open-source Xen project.
5. Memory Virtualization
(1) Virtual Address Vs. Physical Address Vs. Machine Address
In the discussion of the previous sections, we have discussed the difference between the virtual address and the physical address. The virtual address space is the address space that can be viewed by the applications and the physical address space is the real address space the OS manipulates.
However, when we have virtualization, the physical address space viewed by the guest OS will not be the same as the real address. Instead, these will be the ones that the guest OS thinks are addresses of the physical resources. The machine addresses will then become the name of the actual addresses on the machine on the underlying platform.
(2) Full Memory Virtualization
The full memory virtualization means that all the guest VMs expect they have their own contiguous physical memory starting at the address 0. Note that at the hardware level, we have a number of the memory management units like MMU or TLB, and these can still help with the address translation process.
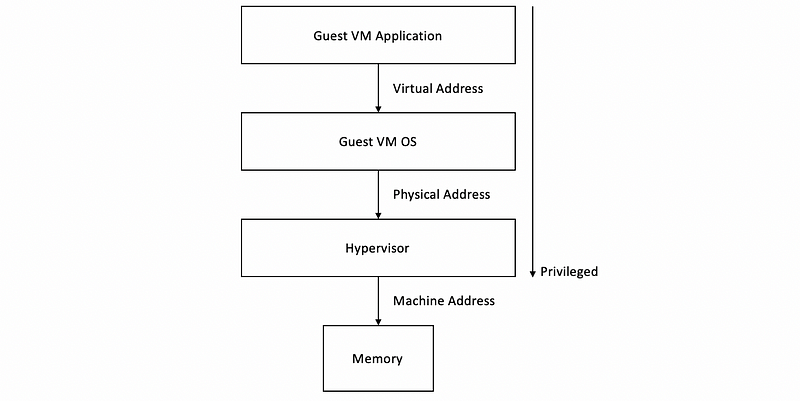
(3) Full Memory Virtualization Option #1: Direct Translation
The simplest idea is that we can do two translations to find the machine address. One is the traditional V2P translation supported by the guest’s page tables, the other is a P2M (physical to machine) translation supported by the hypervisor.
However, clearly, this option is going to be too expensive since it adds overheads on every single memory reference, and it will slow down the ability to run at near-native hardware speeds.
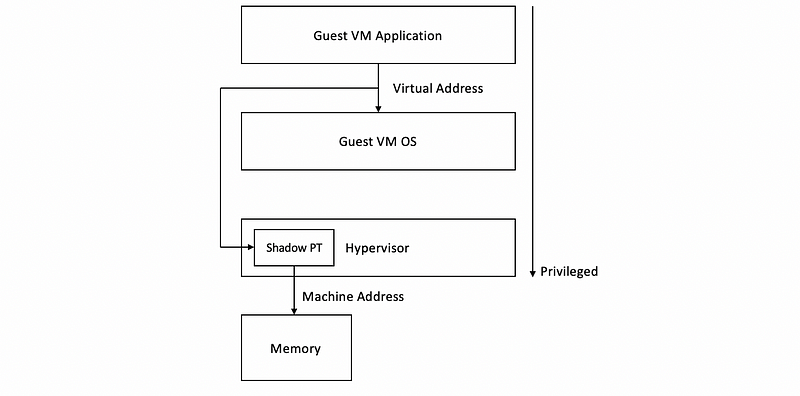
(4) Full Memory Virtualization Option #2: Shadow Page Table
One way to improve the previous model is that the hypervisor can maintain a shadow page table, in which it actually looks at what are the virtual addresses the guests have mapped to these physical addresses, and then in the shadow page table, it directly establishes a mapping between the VAs that are used by the guest and the MAs that are used by the hypervisor. If the MMU is using this shadow PT, then we can do directly V2M translations.
Whenever the guest OS tries to install new V2P address mapping in the PTs used by the guest, this will cause a trap to the hypervisor. Then the hypervisor will be able to pick up that VA, and then associate the corresponding machine address, and insert this mapping into the shadow PT used by the hardware MMU. This can be done completely transparently to guest OS.
(5) Memory Paravirtualized Virtualization
In para-virtualized systems, the operating system knows that it’s executing in a virtualized environment. So the physical addresses the guest would like to use has the following features,
- no strict requirement for using contiguous physical memory that starts at 0
- the guest OS can explicitly register the page tables that it uses with the hypervisor, so no need for dual page tables (one for the V2P, another for the shadow PT)
- the guest OS can batch a number of page table updates, and then issue a single hypercall to tell the hypervisor to install all of these mappings.
By the way, the two mechanisms for memory virtualization (full virtualization vs. paravirtualization) have substantially been improved given advances in the new hardware architectures. So, some of these overheads have completely been eliminated or at least substantially reduced if we take a look at what’s happening at the newer generation of x86 platforms.
6. Device Virtualization
(1) Diversity Problem of the Device Virtualization
We have talked about memory virtualization and processor virtualization, but they are not as diverse as device virtualization. Also, there is a lack of standardized interfaces and behaviors. To deal with this diversity, virtualization solutions adopt one of the three key models to virtualize devices.
(2) Passthrough Model
The way that the passthrough model works is that the VMM level driver is responsible for configuring the access permissions for devices. For instance, it will allow a Guest VM to have access to the memory where the control registers for the device are.
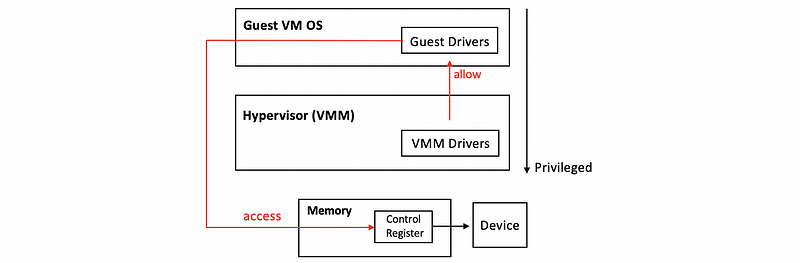
The benefits of this model are,
- VM can exclusively access the device
- VM can directly access the device without passing the VMM (also called VMM-bypass)
The downsides of the model are,
- Sharing the devices for different VMs can be difficult
- Guest VM should have the specific type of device driver
- VM migration would be difficult because the device is now bond to the VM
(3) Hypervisor-Direct Model
In this model, VMM needs to intercept all the device accesses. Once the VMM has the device accesses, it will perform the following operations to emulate device operation,
- translate to generic I/O operation
- traverse VMM-resident I/O stack, and the bottom of that stack is the actual real device driver
- revoke the VMM device driver and perform the I/O operation on behalf of the guest VM
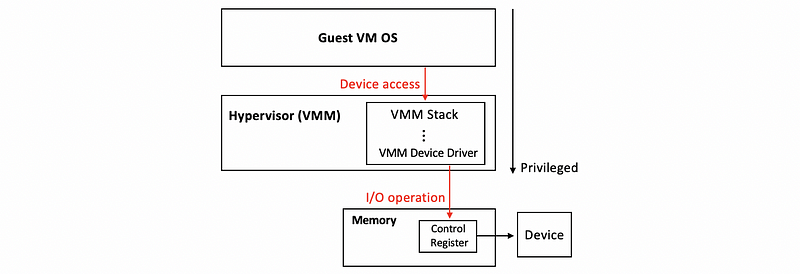
The benefits of this model are,
- VM is decoupled from the physical device, and any translation and any emulation will be performed by the hypervisor
- Sharing the devices for different VMs is easier
- VM migration would be easy
- Guest VM doesn’t need to have the specific type of device driver
The downsides of the model are,
- Add latency on the device accesses
- There are device driver complexities in the hypervisor and they are not always provided by the designers or the manufactures
(4) Split Device Driver Model
The last mode is called split because all of the device accesses are controlled in a way that involves both a component that resides in the guest VM and also a component that resides in the hypervisor layer. Specifically, device accesses are controlled using a device driver that sits in the guest VM called the front-end device driver. And the actual driver for the physical device in the service VM (or the lost OS for type-2 virtualization) is called the back-end driver.
Although this back-end driver does not necessarily have to be modified, the front-end driver has to be modified, because it needs to take the device operations that are made by the applications in the guest and then put them together like a special message that will directly be passed to this backend component that’s in the service VM. So this approach essentially applies only to paravirtualized guests that will be able to explicitly install these special front-end device drivers.
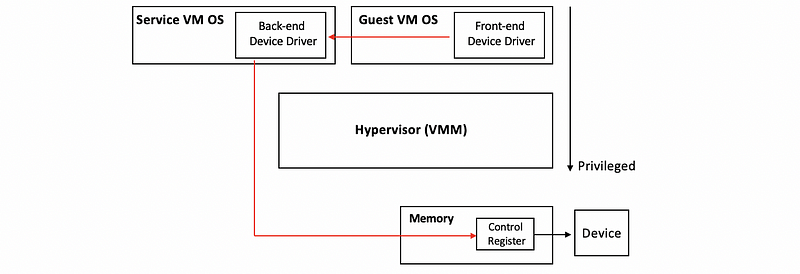
The benefits of this model are,
- Eliminate emulation overheads
- Allow better management of the shared devices