Operating System 23 | Introduction to Remote Procedure Calls, Interface Definition Language, RPC…
Operating System 23 | Introduction to Remote Procedure Calls, Interface Definition Language, RPC Design, RPC Examples, and XDR

- Introduction to Remote Procedure Calls (RPC)
(1) The Definition of Remote Procedure Calls (RPC)
In this section, we are going to talk about remote procedure calls (aka. RPC), which is an IPC mechanism that specifies that the processes interact via a procedure call interface. RPC is intended to simplify the development of cross-address space and or cross-machine interactions.
(2) Remote Procedure Calls: Two Examples
To understand RPCs, let’s look at two example applications.
The first example is an application where a client requests a file from a server and uses a simple GETFILE protocol similar to HTTP. In this case, we will,
- create and init sockets for client-server communication
- allocate any buffers that are going to be sent via those sockets
- populate the information with anything that includes the protocol (i.e. GETFILE, file size, etc.)
- explicitly copy the file data in and out of these buffers
A second example is an application where a client-server application in which the client interacts with a server to upload some images, and that it requests them from the server for these images to be modified to create a grayscale version (or some other algorithms) of an image. See an example from here. In this case, we will,
- create and init sockets for client-server communication
- allocate any buffers that are going to be sent via those sockets
- populate the information with anything that includes the protocol (i.e. algorithm, parameters, etc.)
- explicitly copy the image data in and out of these buffers
We can discover that although these two examples focus on different purposes, they have similar synchronous semantics. So in the 80s as networks were becoming faster and more and more distributed applications were being developed, it became obvious that these kinds of steps are really very common in related interprocess communications and need to be re-implemented for the majority of these kinds of applications.
So it was obvious that we need some system solution that will simplify this process, which will capture all the common steps that are related to remote interprocess communications. This gave rise to RPCs.
(3) Benefits of RPC
RPCs offer a higher-level interface that captures all aspects of data movement and communications, and there are some benefits of using it,
- RPC offers a higher-level interface: easy for programmers
- RPC provides many error handlings: don’t need to reimplement the error handlers
- RPC hides the complexities of cross machines interactions: programmers don’t have to worry about machine differences
(4) RPC Features
If we want to implement the RPC, there are some system software features. These features include,
- RPC can manage client-server interactions
- RPC provides procedure call interfaces: simplify the system calls
- RPC can do type checking: optimize run time and handle errors, and it can also provide useful type information
- RPC can provide cross-machine communication: we can differ from big-endian and little-endian
- RPC would like to perform higher-level protocol: except for TCP and UDP, it should also support access control, authentication, or fault tolerance
(5) RPC Organization: Client Stub
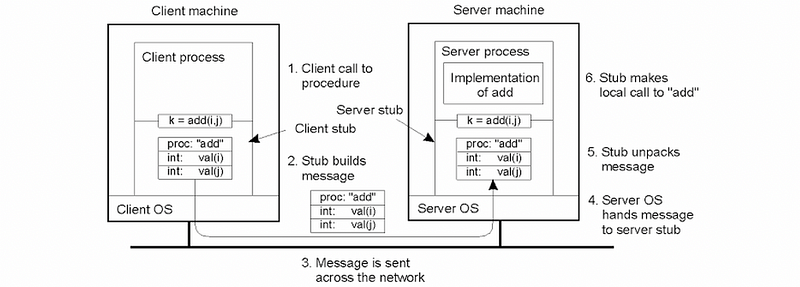
Now let’s see an example about the RPC organization. Consider a client and server system. The client wants to perform some arithmetic operation, let’s say addition, subtraction, multiplication but doesn’t know how to. The server is the calculator process and it knows how to perform all of these operations.
Whenever the client needs to perform some arithmetic operation, it needs to send the message over to the server that specifies what is the operation it wants to perform as well as the arguments. The server is the one that has the implementation of that operation so it will take those arguments, perform the operation, and then return the results.
To simplify all of the communications-related aspects of the programming like creating sockets, allocating and managing the buffers for the arguments, and for the results, and all the other details, this communication pattern will use RPC.
In this example, when the RPC add is called, the execution of the program will also jump to another location in the address space but it won’t be where the real implementation of add is. Instead, it will be in a client stub implementation from the rest of the client’s process it will look just like the real add, but internally what the stub does is something entirely different.
The responsibility of the client stub is to create a buffer and populate that buffer with all of the appropriate information, in this case, it’s the descriptor of the function that the client wants the server to perform, the add, as well as its arguments, the integers i and j. The stub code itself is automatically generated via some tools that are part of the RPC package, so the programmer doesn’t have to write this code.
(6) RPC Steps
To generalize from the example that we saw in the previous video, we will now summarize the steps that have to take place in an RPC interaction between a client and a server.
- Step #-1 (register): the server registers procedure, argument types, location, etc. The server will need to announce to the rest of the world the procedure that it knows how to perform, the argument types that are required for that procedure, its location, the IP address, the port number, etc.
- Step #0 (bind): the client finds and binds to the server
- Step #1 (call): the client makes an RPC call, which passes the information to the stub and the rest of the client code blocks
- Step #2 (marshal): the client stub will create a data buffer and it will populate it with the values of the arguments that are passed to the procedure call. This process is called marshalling the arguments.
- Step #3 (send): the client sends the message to the server
- Step #4 (receive): the server receives the message and then passes the message to the server stub. Necessary checks are performed to determine what is the correct server stub that this message needs to be passed to, and it’s possible to include certain access control checks at this particular step.
- Step #5 (unmarshal): the server stub will unmarshall the data. Unmarshall is clearly the reverse of marshalling, so this will take the byte stream that’s coming from the received buffers, it will extract the arguments, and it will create whatever data structures are needed to hold the values of those arguments.
- Step #6 (actual call): the actual procedure call can be made once the arguments are allocated and set to the appropriate values.
- Step #7 (result): the server will compute the result of the operation or potentially it will conclude that there is some kind of error message that needs to be returned. The result will be passed to the server stub and it will follow a similar reverse-path in order to be returned back to the client.
2. Interface Definition Language (IDL)
(1) The Definition of Interface Definition Language (IDL)
The RPC client and server don’t have to be developed together as part of the same application. They may be completely independent processes written by different developers, written even in completely different programming languages.
But for this to work, there must be some kind of agreement, and the RPC systems rely on interface definition languages (aka. IDLs). IDLs serve as a protocol of how this agreement will be expressed.
(2) The Information of IDL
An IDL is used to describe the interface that particular server exports and this will at least include,
- the name of the procedure
- the types of the different arguments
- the types of the results
- version number: it is useful when there are a number of servers that perform the same operation and the version number helps a client identify which server is the most current implementation of this procedure so that we don’t have to upgrade all the clients and all the servers at the same time. So, this is basically useful for so-called incremental upgrades.
(3) Types of IDL
The RPC system can use an interface definition for the interface specification that’s completely agnostic to the pre-existing programming languages (e.g. XDR in SunRPC), or we can have a language-specific IDL (e.g. Java in Java RMI), which means the IDL for this RPC looks just like Java.
Now let me reiterate one more time that whatever the choice for the IDL language, this is used only for the interface that the server will export. The IDL is NOT actually used for the actual implementation of the service.
3. RPC Design
(1) Marshalling
To understand marshalling, let’s look at the add example again. The variables i and j are somewhere in the memory of the client process address space. The client makes the call to the RPC procedure (RPC add) and passes i and j as arguments to it. At the lowest level of the RPC runtime, this will somehow need to result in a message that’s stored in some buffer that needs to be sent via socket API to some remote server. The marshalling code will take these variables i and j and then it will copy them into this buffer. It will serialize the arguments of the procedure into a contiguous memory location in this manner.

This means that the marshalling process needs to encode the data into some agreed-upon format so that it can be correctly interpreted on the receiving side.
(2) Unmarshalling
In contrast, in the unmarshalling, we take the buffer that’s provided by the network protocol and then based on the procedure descriptor and the data types that we know are required for that procedure descriptor. As a result of the unmarshalling process, these i and j will be allocated somewhere in the server address space.
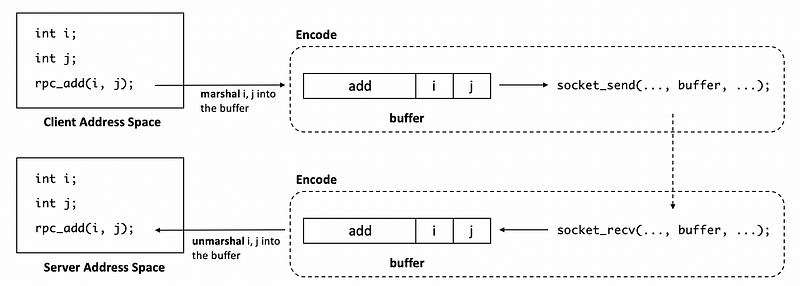
Note that the marshalling and unmarshalling routines aren’t something that the developer will explicitly have to write, but the RPC systems typically include a special compiler that takes an IDL specification for generating the marshalling and the unmarshalling routines.
(3) Binding
Binding is the mechanism that’s used by the client to determine,
- which is the server that it needs to connect to (by service name, version number, etc.)
- how to connect to that particular server (by IP address, network protocols, etc.)
To support binding, the system software needs to support some form of database of all of the available services, and this is often called a registry.
(4) The Definition of Registry
The registry is a database of available services that are supported by the system software. It can be treated as the yellow pages that you will need to look up the service name, and then find the best match based on,
- the protocol
- the version number
- the proximity
- etc.
That match will then provide you with the contact details for that particular service instance as,
- the address
- the port number
- the needed protocol
The registry can be deployed either online (e.g. by something like RPCregistry.com) or machine-specific (means that every machine knows only about those services that run on that particular machine).
(5) Naming Protocol
Regardless of how the registry is implemented, it will require some sort of naming protocol (aka. naming conventions). For instance, the simplest approach could require that a client has to specify the exact name and version of the service that it requires like add. Or a more sophisticated naming scheme could consider the fact that words like,
summationsumaddition
are likely equivalent to the use of the word add and so any service that uses any one of these function names or service names is a fair candidate to be considered when trying to find the best match.
Allowing this type of reasoning will require support for things like ontology or other cognitive learning methods, but we will not discuss this in this course.
(6) An RPC Problem: Pointers
A tricky issue when it comes to RPC’s is the use of pointers as arguments to procedures. In regular procedures, it makes perfect sense to have procedures like this foo that takes two arguments, an integer and a second argument is a pointer to an integer or an integer array. For example,
foo(int x, int *y);
However, in RPC, passing a pointer to the remote server makes no sense since this pointer points to some location in the caller’s address space. The server cannot possibly get to the contents that are stored at this particular address.
(7) RPC Pointers Problem: Solutions
In order to solve this problem, the RPC systems can make one of two decisions,
- No pointers: the simplest idea is that we will not allow any pointers to be used as arguments of any procedure that’s an RPC procedure so that we don’t have to worry about this problem
- Data copied: the other idea is that the marshalling code that gets generated with the fact that an argument is a pointer, and that instead of just taking that argument, the actual data pointed by this buffer will also be copied into the buffer. What that means is that it will copy the reference into the data buffer, into one serial representation.
(8) RPC Failures
In the RPC process, there can be many kinds of failures. These failures include,
- overloaded server
- lost client request
- client packet lost
- server packet lost
- server machine crashed
- server process crashed
- network elements (e.g. network link) down
- switch or router down
- etc.
Even if the RPC runtime incorporates some mechanisms that timeout whenever a client RPC call hangs, and then retries them automatically, there really are no guarantees that the problem will be resolved or that the RPC runtime will be able to provide some better understanding of what’s going on. What’s more, even if for some cases, it is possible to really understand what is the cause of the error, but in principle that is too complex, it would take a lot of overhead, and ultimately it’s still unlikely that it will provide a definitive answer.
For this reason, RPC systems typically try to introduce a new type of error notification or a new type of signal or exception that tries to capture what goes wrong with an RPC request without claiming to provide the exact detail. This serves as a catch-all for all types of errors, all types of failures that can potentially happen during an RPC call and it also can potentially indicate a partial failure.
(9) RPC Design Summary
In the last few videos, we described some issues with the RPC mechanisms, and now let’s review them.
- binding: how to find the server
- IDL: how to talk to the server
- marshalling: how to package the data
- pointers dealers: disallowed pointers or serialized data
- partial/entire failures: special error notifications
4. RPC Examples
(1) Sun RPC History
Sun RPC is an RPC package originally developed by Sun in the 80s for their network file system or NFS for UNIX systems. But it became popular and now it’s widely available on other platforms.
(2) Sun RPC Design
Sun RPC makes the following design choices,
- Binding: a registry daemon per machine because the server machine is known upfront
- IDL: relying on the agnostic language XDR for interface specification and for encoding
- Pointers: allowed and serialized
- Failures: internally retry mechanism when timeout, and return as much information as possible when meets an error (meaning error information)
(3) Sun RPC Organization Overview
Sun RPC client and Sun RPC server are allowed to interact via procedure call interface, and this is specified in the language XDR in the .x file. Sun RPC includes a compiler called rpcgen that will compile the interface specified in the .x file to a language-specific stub. It will generate separate stubs for the client and the server.

The server process when launched will register itself with the registry daemon that’s available on the local machine. The per-machine registry will keep track of information that includes the name of the service, the version, any of the protocols that are supported with the service, and also the port number that needs to be contacted when the client-side RPC sends a request to the server. A client must explicitly contact the registry on the target machine in order to obtain information about the server process.
When the binding happens, the client creates an RPC handle and this handle is used whenever the client makes any RPC calls and in this way, the runtime is able to track all of the per-client RPC-related states.
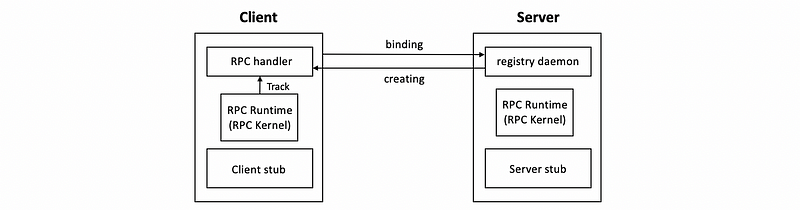
(4) Sun RPC and TI RPC
Because Oracle purchased Sun in 2010, Sun RPC is now maintained by Oracle. You can find an ONC+ developer’s guide of the Sun RPC, and you may find references to TI RPC as opposed to Sun RPC in this link.
TI RPC stands for Transport Independent RPC and that means that the protocol that will be used for the client and server communication doesn’t have to specify at compile time. It can be specified dynamically at runtime. Other than that, the documentation and the examples closely follow the original SunRPC specification as well as the XDR interface definition language.
(5) An XDR Example
We’ll now take a look at the various components of Sun RPC using an example. The client again will be contacting a server that can perform calculations except for this time the client will pass a single argument x for which it will want the server to compute the square value x².
Here is the .x file for this example with which the server specifies its interface. In this case, the server supports one procedure SQUARE_PROG that has one argument of the type square_in and returns a result of the type square_out. The data types square_in and square_out are both defined in the .x file. If we take a look at them, it turns out that both of them have a single element and that’s an int and in XDR an int is an integer just like the integers in C, a 32-bit integer. Also, note that this notation _in, _out is not any part of the required syntax for specifying the input and the output data types in XDR.
In our case, the SQUARE_PROG service supports exactly one procedure and that’s SQUARE_PROC procedure. There is an ID number that is associated with it. This is 1 in this case. This number is not used by the programmer. The name SQUARE_PROC instead will use this value 1 as a reference.
There is also a version ID and a service ID. The former one is defined so that we don’t have to coordinate and upgrade all of the servers and all of the clients at the exact same time. The latter one is defined so that the RPC runtime can refer to for differentiating among the different services.
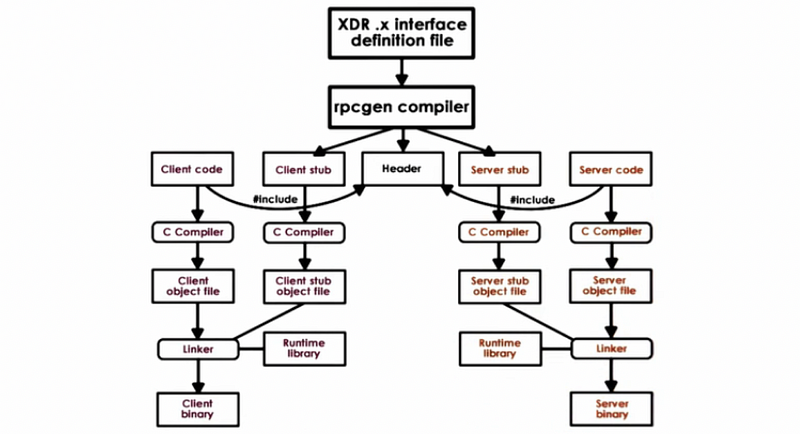
(6) Compiling XDR File
Let’s show you actually compile a .x file. Assume that we’re using the square.x file we have discussed, and we would like to compile this file to automatically generate a bunch of code that’s used for the client and the service. For example, we will use the -c option to generate C code with rpcgen by,
$ rpcgen -c square.x
The outcome of this operation will be that a number of files will be generated.
square.h: language-specific definitions of data types and function prototypessquare_svc.c: server stub which also includes the skeleton of the actual server. This file will consist of two parts. The first one is themainfunction for the server that will include the code that does the registration and housekeeping. The other is thesquare_prog_1function that contains all the code related to the RPC service. This will include the automatically generate code for parsing the request, generate the arguments, conducting the argument marshaling operations, and other steps. In addition, in the stub file, the auto-generated code will include the prototype for the actual procedure that’s invoked in the server process namedsquare_proc_1_svc, and this should be implemented by the programmer.square_clnt.c: client stub. It will include a procedure that’s automatically generated calledsquare_proc_1. And this will represent a wrapper for the actual RPC call that the client makes to the server-side process where the implementation of the servicesquare_proc_1_svcis actually called. Once we have all of this, the developer then writes the client application and makes a call to this wrapper function that looks something like thisy = square_proc_1(&x…). This very much looks like a regular procedure call, there is no need to create sockets, create buffers, copy data into the buffers and this is what makes RPC appealing.square_xdr.c: some common code that’s related to the marshaling and unmarshalling routines for all data types arguments, and results that are used both at the client and on the server-side.
(7) Compiling Multithreading XDR
We should point out that rpcgen, when used only with the flag -c generates code that is not thread-safe. The output of the compilation results in a function that will need to be called with something like,
y = squareproc_1(&x, client_handle);
And the problem with this function is that internally the implementation of this operation as well at the runtime level, there are a number of statically allocated data structures including for the result and this leads to race conditions when multiple threads are trying to make RPC calls to this routine concurrently.
To generate thread-safe code, the code must be compiled with the -M option and M stands for multithreading safe,
$ rpcgen -c -M square.x
This will also create a wrapper function square_proc_1 like,
status = squareproc_1(&x, &y, client_handle);
However it has a different signature, and its implementation differs, for instance, it will dynamically allocate memory for the results of this operation so some of the issues that are coming up with the previous implementation will not come up in this case.
On Solaris platforms, there is another option -a. Using this option that actually generates multi-threaded server code. But on Linux, this option is not supported and any multithreaded server has to be created manually using the multithreaded safe routines as a starting point.
You can have a try at this by downloading the square.x file, and then run rpcgen on the Ubuntu VM provided with this class. If you have not set up the Ubuntu VM yet, follow the Ubuntu VM Setup Instructions.
(8) Sun RPC Registry
In SunRPC, the registry daemon is a process that runs on every single machine, and it’s called portmapper. To start this process on Linux, we have to have administrative permission or sudo access privileges, and then we can launch it with the following command /sbin/portmap.
$ sudo /usr/sbin/portmapThis is the process that has to be contacted by both the servers (when registering a service) and also by the clients (when finding a service). Given that the client already got to talk to this RPC daemon, it clearly knows what is the IP address of the machine that it will need to interact with. So the information that the client can extract from the portmapper includes,
- port number
- version
- protocol
- etc.
Once the RPC daemon is running, we can explicitly check what are the services that are registered with it using rpcinfo -p by the following command,
$ /usr/sbin/rpcinfo -pAnd the output may be,
program vers proto port service
100000 4 tcp 111 portmapper
100000 3 tcp 111 portmapper
100000 2 tcp 111 portmapper
100000 4 udp 111 portmapper
100000 3 udp 111 portmapper
100000 2 udp 111 portmapper
From the result, we can find out information about,
- program ID
- service name
- version
- contact information (protocol, socket port number)
The portmapper service is registered with TCP and UDP on the same port number 111. This means that there are two different sockets that the server is listening to. One is the TCP socket and another one is the UDP socket and they both happen to use the exact same port number 111. This means that with this service, the portmapper will be able to talk to both TCP clients as well as UDP clients.
(9) Sun RPC Binding
Now, let’s talk about the Sun RPC binding process. The binding process is initiated by the client using the following operations,
CLIENT* clnt_handle = clnt_create(rpc_host_name, SQUARE_PROG, SQUARE_VERS, "tcp");
To use this function, we have to specify the name of the RPC service rpc_host_name as well as the protocol we want to use when communicating with the server, and we will specify the name of the RPC service by SQUARE_PROG as well as the version number SQUARE_VERS. These two arguments of the client create operations are auto-generated in the rpcgen process from the .x file and will be included in the header file as hash-defined values.
The return from this operation is a variable clnt_handle that’s of data type CLIENT. This is the client handle that the client will include in every single RPC operation that it requests, and this handle will be used to track certain information such as,
- status of the current RPC operation
- error messages
- authentication-related information
(10) XDR Data Types
Because all the input and output arguments must be described in the XDR file, we have to know the XDR data types. Some of the default XDR data types are those that are commonly available in programming C languages (e.g. character, byte, int, and float) but XDR supports many other data types. You can find all of them from this document, but we will explain some of the common ones here. For example,
const: a#definevaluehyper: a 64-bit integerguadruple: a 128-bit floatopaque: uninterpreted binary data (e.g. the image data can be represented by an array ofopaquetype data)
(11) XDR Array
Let’s talk more specifically about arrays because in XDR we can specify two types of arrays.
The first is a fixed-length array that’s described as follows. And here, the exact number of elements in the array is specified. The RPC runtime will allocate the corresponding amount of memory whenever arguments of this data type are sent or received and it will also know exactly how many bytes from the incoming packet stream it should read out in order to populate a variable that’s of this type of array.
int data[80];
There are also variable-length arrays where the length is specified in angular brackets, and this doesn’t denote the actual length, rather the maximum expected length. When compiled, this will translate into a data structure that has two fields, an integer len that corresponds to the actual size of this array and a pointer val that is the address of where the data in this array is actually stored.
int data<80>;
A variable-length string is defined as follows and it is really just a C pointer to characters. In memory, this string will be stored just like a normal null-terminated string, so it will be an array of characters with the null character at the end.
string line<80>;
(12) XDR Routines
XDR provides the RPC runtime with some helpful routines.
For instance, after we compile an XDR file, the compiler will generate a number of routines that are used for marshalling or unmarshalling the various data types that can be found in square_xdr.c file.
In addition, the compiler will generate some cleanup operations like xdr_free that are used to deallocate or to free up memory regions that are used for the data structures or the arguments in the RPC operations. These routines will typically be called within a procedure, that the name of the procedure typically ends with _freeresult (e.g. square_prog_1_freeresult). The RPC runtime will automatically call this procedure after it’s done computing a result.
(13) XDR Buffer
One remaining question is what ends up in the buffers that are being passed for transmission among the client and the server, and here, we will talk about its answer. The buffer will include,
- RPC header: containing server procedure ID, version number, request ID, etc. Similar types of information will be sent from the server back to the client again as part of the RPC header.
- Actual data: containing the actual data, the actual arguments, or results. As opposed to just directly copying from memory into the packets we have to first encode all of the different data types for the arguments and the results into a byte stream to serialize them in a way that depends on the actual data type.
- Transport header: containing the networking header including the protocol, the destination address, and etc.
(14) XDR Encoding Rules
Here are some encoding rules of the XDR,
- all data types are encoded in multiples of 4 bytes: even if we have 1-byte data, there need to be three more paddings
- big-endian is used for the transmission standard: in some cases, this will be pure overheads, but we eliminate any kinds of ambiguity
- 2’s complement is used for integers
- IEEE format is used for the floating points
- etc.
(15) XDR Encoding: An Example
Suppose we have a definition of the data type in an XDR file as follows,
string data<10>;
data = "Hello";
If we have C processes, then this variable will take 6 bytes, 5 bytes for each char, and 1 last byte for the last NULL terminating character \0. However, in the transmission buffer, the variable will be encoded and it will take actually 12 bytes for,
- 4 bytes for the length integer (i.e.
len = 5) - 5 bytes for the characters
- no NULL terminating character
- 3 bytes for padding because of the XDR encoding rules