Operating System 25 | Introduction to Distributed File System, Introduction to Network File System…
Operating System 25 | Introduction to Distributed File System, Introduction to Network File System, and Introduction to Sprite DFS

- Introduction to Distributed File System (DFS)
(1) Review: File Systems
In our previous discussion about file systems, we have said that the modern OS (e.g. Linux) hides the fact that there may be multiple types of internal file system organizations. And this is done by exporting a higher-level virtual file system (VFS) interface.
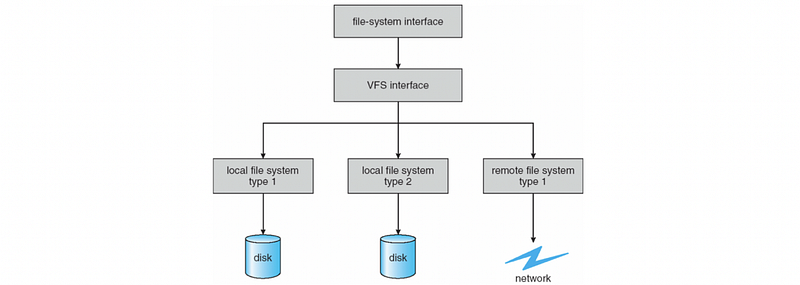
(2) Remote File Systems
Underneath this VFS interface, the OS can also hide the fact there isn’t even local physical storage on a particular machine where the files are stored, but that instead everything is maintained on a remote machine or on a remote file system that is being accessed over the network.
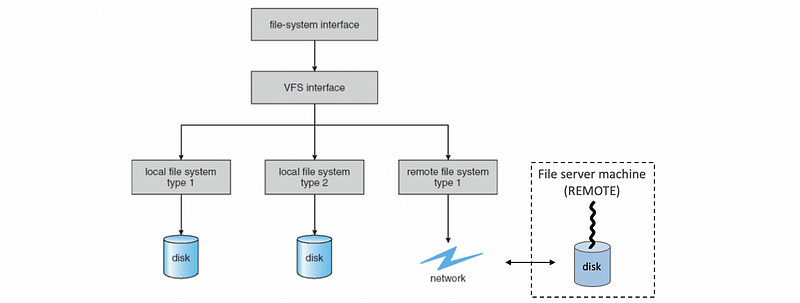
These kinds of environments where there are multiple machines that are involved in the delivery of the file system service together form a distributed file system (aka. DFS).
(3) Two Types of DFS Models
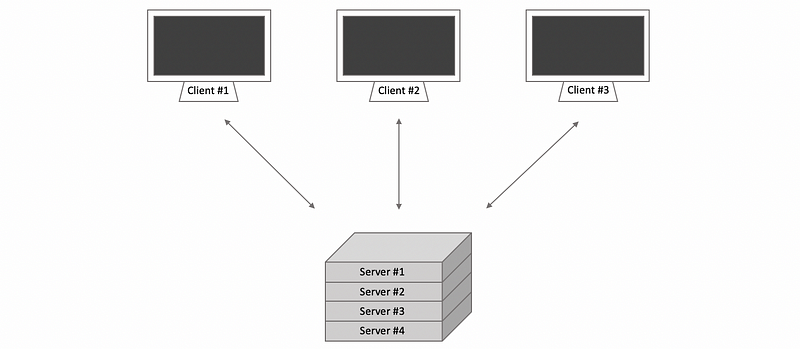
More generally, a distributed file system is a file system that can be organized in two ways.
The first model is when the clients and the file server are on different machines. Nowadays, the file server is not just single machine but instead, it’s distributed on multiple machines. This may mean that all the files are replicated, and available, on every single machine, and even if there are some failures on one of the servers, because there are always a replicate file on some other machines. Also, the file requests from the clients can be split among the servers and this helps with the availability.
However, in the replicated model, we still need every single server to store all files so if we need to scale the file system to be able to store more files, we’ll have to buy machines with larger disks. Unfortunately, at a certain point, we are likely to reach a limite.
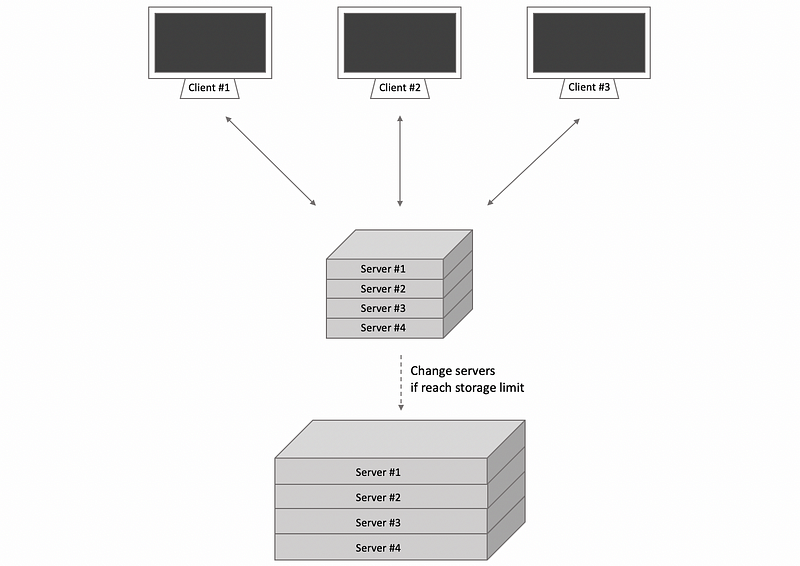
The second model is that the file server can be distributed among multiple machines is by splitting the files, dividing them, or partitioning them. So that different physical machines store different files, and these machines are called peers. This makes the system more scalable than the replicated model because if you need to store more files, you simply add additional machines.
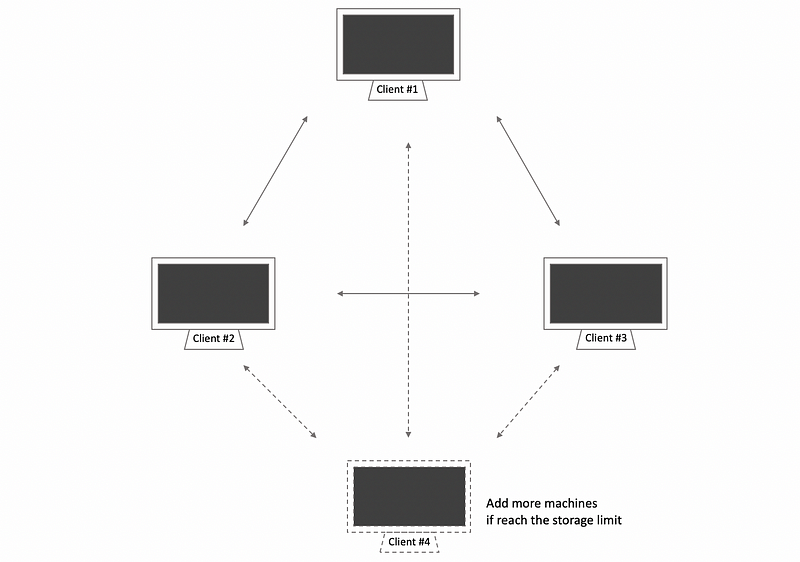
(4) Upload-Download Model (UDM)
Let’s first look at the different extreme services that a remote file service can be provided and we will assume that there is one client and one server.
One extreme model that we have is called the upload-download model, which means that when the client wants to access the file, it downloads the entire file, performs locally the operations, and then, when done, it uploads the file back to the server.
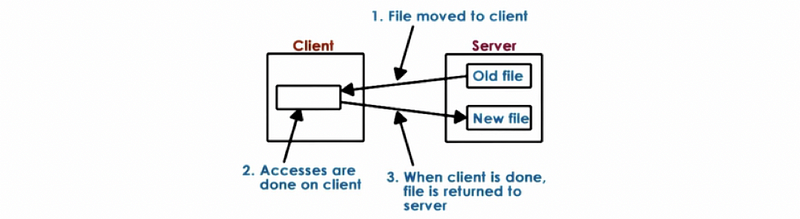
The benefit of this model is that once the client has the film, it can perform all the file operations in a very quick way. However, the downsides are as follows,
- client needs to download the entire file
- it takes away file access control from the server, and the server has no idea what the client will do to the file
(5) True Remote File Access Model (TRFAM)
The other extreme is called the true remote file access model. In this model, the file remains on the server, and every single operation, every read and every write, has to go to the server.
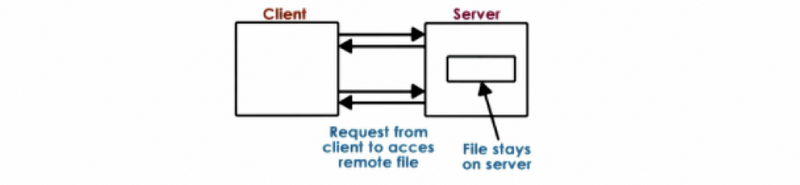
The benefit of this extreme is that the server has full control and knowledge of how the clients are accessing and modifying the shared state and the shared files. This makes it easier to ensure that the state of the file system is consistent and that there are no situations where multiple clients are overwriting the same portions of the single file at the same time. However, the downsides of this model are as follows,
- every single file operation has to incur the cost of remote network latency
- the server will get overloaded more quickly and it is not able to support many clients
(6) Remote File Service Model
The two models UDM and TRFAM are two extremes, but in reality, what makes sense is to have something in between as a compromise. This critical model is called a remote file access model (or remote file service model) which has the following features,
- Allow clients to benefit from using their local memories: this will lead to lower latency for these local files and some of the workloads on the server can be simply removed and the server becomes more scalable.
- Force clients to interact with the server: the clients need to notify the server of any modifications to the file that they have made and the server needs to broadcast all the clients if any of the files that they have locally cached has been modified by someone else. Therefore, the server now has some insights into that clients are doing and the server can have control into which accesses can be permitted. So it is easier to maintain file consistency.
However, there is also a problem with this model because it makes the file server more complex. It means that the server would have to perform additional tasks and maintain additional states so as to make sure that it can provide consistency guarantees. What’s more, the clients would have to understand somewhat different file sharing semantics compared to what they are used to in a typical local file system.
(7) Stateless Server
The stateless server is one that doesn’t maintain any information regarding which clients access which files how many different clients are serviced. Every request has to be self-described and it needs to have all of the parameters regarding the files being accessed the absolute offset within that file along with any data that needs to be written. This model is suitable for the UDM and other extreme models but it cannot be used for the more practical models.
The downsides of this model are,
- we can not achieve consistency in the DFS
- the request has to contain more bits of data because it is self-described
The benefits of this model are,
- no state that’s maintained on the file server, so there will be no consumed resources needed by the server to maintain the file state data
- the server just need to simply restart to recovery from a failure
(7) Stated Server
A stateful server is one that maintains information about the clients in its system, for example, the file names we are accessing, which is the access type (i.e. read or write), etc.
Because of this stated server,
- it becomes possible for the file server to allow data to be cached on the clients and at the same time to guarantee consistency
- it can support more features like locking and incremental operations
However, there can be some problems,
- on failure, all the states on the server should be able to be recovered for consistency. Therefore, we will need more mechanisms like checkpoints
- the runtime of the server will be worse because we have to do overheads on maintaining the state and consistency protocols
(8) File Caching
The first distributed file system mechanism we will look at is caching. Caching is a general optimization technique in distributed systems where the clients are permitted to locally maintain a portion of the state (e.g. file blocks). And also, the clients are permitted to perform some operations (e.g. open, read, write, etc.) on that cached state locally.
With a single file server and many clients, the file and file blocks can be stored in a DFS at,
- the client’s memory
- on the client’s storage device (HDD or SSD)
- in buffer cache in the memory of the server
(9) Caching Coherence Mechanisms
Keeping the cached portions of the file consistent with the on-server representation of that file requires to have some coherence mechanisms, and these mechanisms are like write-update and write-invalidate for the cache coherence on SMPs (shared memory processors). Recall these mechanisms for an SMP system get triggered whenever a particular variable or a particular memory location gets written to. For a DFS system, it would make more sense if we trigger these mechanisms on demand when the client needs to access a file or periodically whenever the client is open.
And also, when we need to update or invalidate the file state, we have to make sure whether this file is client-driven (means that the client needs to find the file and update its context) or server-driven (means the server needs to notify the client with a cached file that something has changed about their cached state).
(10) File Inconsistency Problem for DFS
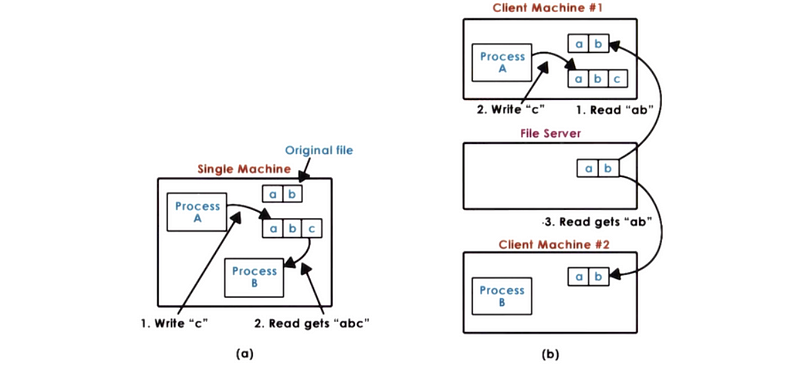
To explain the file-sharing semantics in DFS, let’s see a file inconsistency problem in the DFS system.
In the following figure (a), we have a single node in a Unix environment. When process A write c to a buffer that keeps the file with data ab , the file will immediately become abc and another process that would like to read from this file can only achieve a result of abc . This means that every write of a process will become visible for other processes immediately in Unix.
However, for the DFS system, this is not the case. In the following figure (b), we have two clients. The first client writes to the file but the file is not written to the server, so even after the other client #2 read from the file after process A wrote to this file, we will not get a file content of abc and this will create a file inconsistency problem for us.
(11) Session Semantics Policy
To deal with the inconsistency problems among clients, we have to introduce some file-sharing policies. The first one is called session semantics.
Whenever a file is closed by close(), the client writes back to the server all of the changes that it has applied to that file in its cache. Whenever a client needs to open a file by open() , it doesn’t use the cache contents. Instead, it goes and checks with the file server for whether or not there is a more recent version of that file. If there is a more recent version on the server, we will then update the local file. We call the session semantics with the period between the file open and the file close being referred to as one session. Although the session semantics can be easy to use, it can be inefficiency sometimes.
(12) Periodic Updates Policy
Because the session semantics is inefficient, it makes more sense to introduce some time intervals when these updates happen. This semantics is called periodic updates. With time intervals, the client updates writes will be periodically written back to the server by some sort of lease on how long they have to wait in order to use the cached data.
In the same way, the server notifications the invalidations are also periodically sent out to the clients. This can establish some time bounds during which the system can potentially be inconsistent, and it will be easier if there are some conflicts.
Since the client doesn’t really have any idea about what are the start and the end times of these synchronization periods, the file system can also provide some explicit operations like the flush() API (flushing the updates to the disk or the local storage) and the sync() API (synchronizing the state to the remote server).
(13) Immutable Files Policy
There are some other file-sharing policies. For instance, files may be simply immutable you never really modify a file you simply delete it or you create a new file with a new name. This is useful when we are sharing photos via Instagram or Facebook when we don’t edit them after the modified photos are uploaded. These types of distributed storage have this kind of semantics called immutable files.
(14) Transaction Policy
The file system needs to import some APIs so that the clients can specify some questions like,
- what is the collection of files that need to be treated like a certain single transaction
- what is the collection of operations that need to be treated like a certain single transaction
And then the file system can make some guarantees that all those changes are atomically committed visible into the file system.
(15) Designing DFS Requirements
When we want to design an efficient DFS system, we can have many options. In order to choose among these different options, we should know the basic requirements of our design. Commonly, we have to answer the following questions,
- What is the sharing frequency?
- What is the writing frequency?
- Is it important for maintaining the consistency view?
Once we understand these workload properties, the design of the file system must be done by optimizing for the common case.
(16) Regular Files Vs. Directories
In the system, there can be two types of files. The first one is regular files and the other one is directories. These two files have very different access patterns in terms of,
- what is the locality
- what is the lifetime of the files
- the size distribution
- how frequently are they accessed
- etc.
So for these reasons, it is quite common to treat these two types of files differently. For instance, we can adopt one type of semantics for the regular files and another type of semantics for the directories. For example, if we use periodic updates as a mechanism for both then we may choose to use less frequent write-backs for the regular files versus for the directories. This is because directories are more frequently shared than individual files in them.
(17) Replication Server File System
We have said that the clients and the server can be distributed to different machines, but the file server itself can also be distributed. This can be achieved via replication or partitioning.
With replication, the file system can be replicated onto multiple machines such that every single machine holds an exact replica of all of the files in the system. The benefit of this is that it can have its workload balanced among all the replicated servers (availability) and we can have fault tolerance.
The downsides are as follows,
- the writes become more complex because we have to care about consistency among all the replicated server machines
- replicated servers must be reconciled by mechanisms like voting and etc.
(18) Partitioning Server File System
The other technique to DFS states is by using partitioning. Every single machine has only a portion of the state and only a subset of all the files in the system. This splitting of the files may be done based on file names. For example, files with names starting with A~M may be located in one server and the others may stay in another server. Or we may choose a policy where different directories are stored on different machines where we would somehow partition the hierarchical namespace of the directory tree structure.
The benefit of this model is that we can easily achieve availability compared to a single server design and each server will now hold fewer files, and therefore, the file requests for each server will be generally reduced. What’s more, it provides for greater scalability when we consider the size of the file system the overall size of all the files stored in that file system.
However, there are some downsides,
- on failure, we can easily lose some portion of the data because the data is not duplicated among the server machines
- there can be some hot spots, which means that some files on a machine are more frequently accessed and the other files on another machine are less frequently accessed. So it is much harder to balance the workload among the servers compared with the replication model
2. Introduction to Network File System (NFS)
(1) NFS History
NFS has been around since the 80s and has gone through several revisions. The popular NFS versions that are in use today and that come standard with Linux distributions are NFSv3 (stateless) and NFSv4 (stateful), so the NFSv4 supports features like client caching and file logging initially, while NFSv3 has to import some other packages.
With caching, NFS initially behaves with session semantics. And then on opening a check is performed and if necessary the cached parts of the file are actually updated so the new versions of those files are brought in. However, as an additional optimization, NFS also supports periodic updates. In fact, NFS is supporting neither session semantics nor periodic updates semantics. NFSv4 further incorporates a delegation mechanism where the server delegates to the client all rights to manage a file for a period of time and this will avoid any of the update checks that we described here.
The NFS also supports lease-based locking. NFSv4 also supports more sophisticated mechanisms than just a basic lock like a reader-writer lock called share reservation along with other mechanisms.
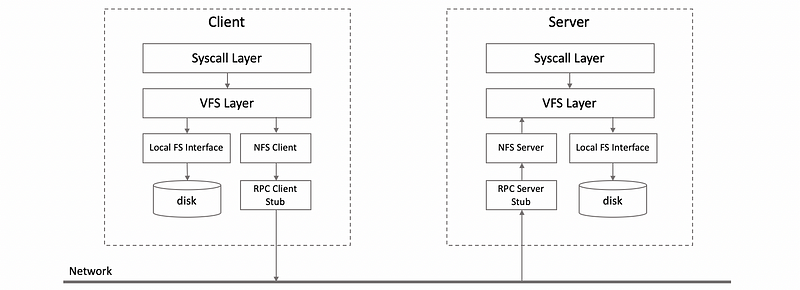
(2) NFS Design
The NFS client interacts via RPC with the NFS server that resides on a remote machine. This is the machine that actually stores the files. The NFS server accepts the request, forms them into a proper file system operation that’s then issued to the local virtual file system and from there it gets passed to the local file system on top of the local storage. On the client’s write operations the data that needs to be written to the file will be carried as part of the RPC request from the client to the server machine.
3. Introduction to Sprite DFS
(1) Sprite DFS Paper
Let’s now look at another distributed file system example, the Sprite Distributed File System, which is described in the research paper Caching in the Sprite Network File System by Nelson. Sprite is mainly for research and it is simply not built for products, even though some people were using it at UC Berkeley at that time.
(2) Sprite DFS Workloads
In Nelson’s paper, the author described how are the files accessed in the DFS used by their department. This is what they found,
- 33% of all file accesses are writes: caching can be important for improvements (because 2/3 accesses can be improved) so write through will simply not be a good idea
- 75% of the files are open less than 0.5 sec, and 90% of files are open less than 10 sec: this means that with session semantics, the overheads can be too high
- 20%-30% of new data deleted within 30 sec and 50% of the new data deleted within 5 minutes: this means that a lot of the data is deleted in a very short period of time after it is created.
- file-sharing is rare: this means that multiple clients working on the same file can rarely happen
So because of these observations they made the following decision, the write-back on close (or session semantics) will not be a necessary operation because we rarely have file-sharing situations and most of the data will get deleted in a short period of time anyway. However, all of these features will not be friendly to the DFS with many clients accessing the same file, but there is indeed some file-sharing process that the DFS must support. So we have to make sure that the Sprite DFS can also support file sharing.
(3) Sprite DFS Design
Based on this workload, the authors made the following design decisions in Sprite.
- support caching with the write-back policy every 30 seconds if the block is not modified in the last 30 seconds. So it is possible that some other clients open the file on the server and get dirty blocks. This is for optimizing the 33% write accesses.
- every open has to go to the server and the directories can not be cached on the client.
- when there are concurrent writes to the same file, then the Sprite will completely disable the caching for that file