Operating System 26 | Distributed Shared Memory, Designing DSM, and Consistency Models
Operating System 26 | Distributed Shared Memory, Designing DSM, and Consistency Models

- Introduction to Distributed Shared Memory (DSM)
(1) Recall: the DFS States, Nodes, and Services
In the previous lesson, we talked about DFS, and we said that the DFS was an example of the distributed file service where the states (aka. files) were stored on some nodes (aka. file servers), and these nodes were accessed by many distribute nodes’ clients. All the file access operations open, read, and write on these files where then the service was provided by these servers, and the clients will then request from them.
Our primary focus of the DFS was the caching mechanisms. These are useful so that server data is cached on the clients, which will improve the performance and scalability supported by the servers.
What we didn’t talk about is that when all the nodes in the system are both servers used to store files as well as clients used to send requests to other nodes in the system. In such a scenario, every single one of the nodes would be performing all of the services. The distributed shared memory (aka. DSM) we are going to talk about in this section is this kind of application without a clear distinction between client nodes and server nodes.
For instance, nowadays, most of the big data applications we heard about today distribute the states across all nodes. The processors on these nodes run certain applications such as the analytics codes, data mining codes, searching for patterns, or etc., and they access the state that’s distributed across all the other nodes in the system.
(3) The Definition of Peers
The key about these DSM applications is that every node in the system owns some proportion of the state. This means that there is some state that’s locally stored in a particular node or that’s generated by computation that’s running on that node. So the overall application state is the union of all of these pieces that are present on every one node, and all the nodes in the system are called peers. All of the peers require,
- to access to the state anywhere in the system
- to provide access to their local storage state
(4) The Definition of Distributed Shared Memory (DSM)
DSM is a service that manages the memory across multiple nodes so that applications that are running on top will have an illusion that they’re running on a shared memory machine like an SMP processor. Each node in the system will have the following features,
- it owns some states (i.e. some portion of the physical memory)
- it provides the operations in that state the reads and writes
- it provides services like consistency protocols
The main advantage of DSM machines is that we can benefit from scaling beyond the limitations of how much memory we can include in a single machine. If we look at how the cost of the computer system is affected by the amount of memory (e.g. when we have a high workload). We will see that beyond a certain limit of memory, the cost of scaling starts increasing rapidly. Instead, with DSM, we can simply add additional nodes and achieve shared memory at a much lower cost.
However, the speed of accessing the memory will be much slower but these additional accessing latency can be hidden by some optimizations. DSM is becoming more relevant today is that commodity-interconnect technologies offer really low latency among nodes in the system. What’s more, they offer remote direct memory access (aka. RDMA) based interfaces that provide a really low latency when accessing the remote memories.
(5) Hardware Supported DSM
One type of the DSM is supported by the hardware, and this type is called the hardware supported DSM. The key component of the hardware supported distributed shared memories is that they rely on some high-end interconnects. In this model, the OS will manage the larger physical memory and it is allowed to establish V2P memory mappings that correspond to memory locations that are in other nodes.
The network interface card (NIC) is the hardware that corresponds to this advanced high-end interconnect technology. The local NIC knows how to translate that memory operation into an actual message that gets sent to the correct remote NICs and the NICs in these nodes will participate in all aspects that are necessary to deal with memory accesses and management of memory consistency. We will also support certain atomic operations just like the atomics that we saw in shared memory systems.
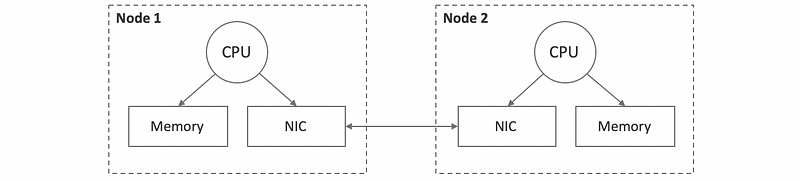
However, nowadays, it is very convenient to rely on the hardware to do everything by NIC, it is typically very expensive and only high-end machines can support this hardware implementation.
(5) Software Supported DSM
Instead, DSM systems can also be realized in software. The software has to,
- detect which memory accesses are local or remote
- create and send those messages to the appropriate node when it is necessary
- accept messages from other nodes
- perform the specific memory operations
- be involved in all of the aspects of memory sharing and consistency support
This can be done at the level of the OS, or it can be done with the support of a programming language and the runtime product programming language.
2. Designing DSM
(1) The Definition of Granularity
In computer science, granularity is defined as the ratio of computation time to communication time. The computation time is the time required to perform the computation of a task and communication time is the time required to exchange data between processors. When we want to design an efficient computer system, we tend to support more time for computation and less time for communication. Therefore, we will have a better performance if the granularity of the system is higher.
(2) Granularity of Sharing
Now, we are going to have a very different definition of granularity, which is defined as the smallest scale (or unit) we need to have for memory sharing among different peers. We have to keep in mind this definition we are going to use in the following discussions is quite different when we talk about the granularity ratio.
To design a DSM system, the first thing we have to think about is the granularity of sharing. In SMP systems, the granularity of sharing is a cache line. However, we can not modify this model if the cache line has been shared with other peers because if all the writes will be sent by the network, it will become too expensive and the overheads will become too high. Therefore, we have some other options. The granularity of sharing of DSM may be,
- Variables: This is not a good idea because the variables can be a few bytes long (e.g. integers) and those settings will still result in very high overheads.
- Pages or Objects: Instead, we can use something larger like an entire page of content or a larger object that begins to make more sense. At the operating system level, it makes sense to integrate some page-based DSM solutions because the OS can understand and track all the necessary messages on page modifications. With some help from the compiler or programming language or runtimes, applications objects can lay out on different pages and the runtime will understand which objects are local and which are remote.
(3) False Sharing Problem
One important problem of page or object granularity is false sharing. This means that the data on the same page or object will be shared even if it is not modified and unnecessary. So this will trigger unnecessary coherence operations or any of the other overheads that are associated with maintaining consistency among these two copies, which will not benefit anyone.
In order to avoid these kinds of situations, the programmer must be careful about how data is allocated and laid out on pages or how it’s grouped in higher-level objects.
The other alternative solution is to rely on some smart compiler that will be able to understand what is really a shared state. And then allocate it within a page or within an object versus what is something that will trigger these false sharing situations.
(4) Access Algorithms
Another important design point in DSM systems is to understand what are the types of access algorithms. The access algorithms are the kinds of applications that will be running on top of the DSM layer, which includes
- Single reader, single writer (SRSW): the simplest one, and it aims to provide additional memory. In this case, there really aren’t any consistency or sharing related challenges
- Multiple readers, single writer (MRSW)
- Multiple readers, multiple writers (MRMW)
In the last two cases (i.e. MRSW and MRMW), it’s not just about how to read or write to the correct physical memory location in the distributed system, but it’s also about how to,
- make sure that the reads return the correctly written the most recently written value of a particular memory location
- make sure all of the writes that are performed are correctly ordered
This is also necessary to present the consistent view of the distributed state of the DSM to all of the nodes in the system. MRSW is a special simpler case of the MRMW problem.
(5) DSM Performance Metrics
If we think about the core service that’s provided by DSM systems is accessing different memory locations, then it’s obvious that the performance metric that’s relevant for DSM systems is the latency with which processes running on any one of these nodes can perform such remote memory accesses. It is clear that accessing local memory is faster than remote memory, but we can also have some options to improve the number of cases where local memory’s accessed versus remote.
(6) Migration: Good for SRSW
One way to maximize the number of local accesses and achieve low latency is to use a technique called migration. Whenever a process on another node needs to access a remote state, we literally move that state over to that node. This makes sense for SRSW because only one node at a time is able to access the state. However, this requires moving and copying the data over to the remote node, and that incurs some overheads. If we have to copy all the state data once and once again, we will not benefit from a higher latency even for an SRSW model.
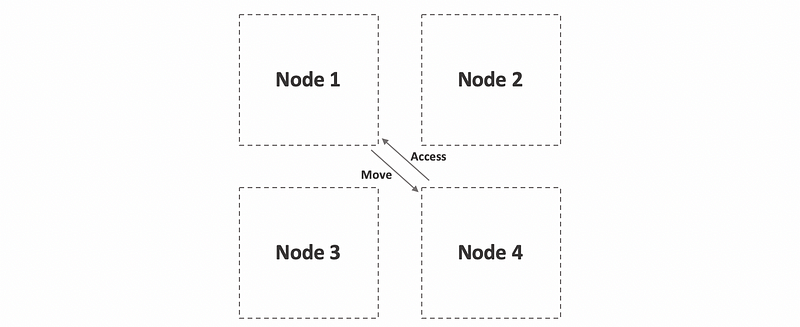
(7) Replication: Good for MRMW and MRSW
For the more general case like MRMW, we have to do replications and the state is copied on multiple nodes potentially on all nodes is a more general mechanism.
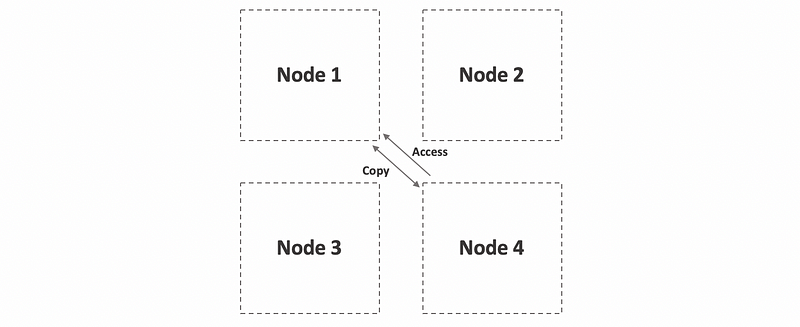
However, now it requires consistency management because the same state can be accessed concurrently on multiple nodes, this will add some sort of overheads which will be simply bad for the overall latency. One way to control the overhead is to limit the number of replicates that can exist in this system since consistency management has overhead that’s proportional with the number of copies that need to be maintained consistently.
(8) Consistency Management
In an SMP system, we also have to maintain consistency among different caches with write-invalidate and write-update. However, these coherence operations are triggered on each write, which will add more overheads in the case of a DSM system. For these reasons, we will look at coherence operations that are more similar to what we have discussed in the DFS.
One option is to have push-invalidations when the data item is written to. This is similar to the server-based approach, but the DSM system state management should be done by all peers instead of just the servers. The features of this option are
- proactive
- eager
- pessimistic
The other option is to use a pull modification periodically on-demand whenever some process needs to access that state locally. The features of this option are
- on-demand or reactive
- lazy
- optimistic
(9) Consistency Architecture
In summary, here are some of the key architectural features of page-based DSM systems.
- each node contributes to part of its main memory pages to DSM
- local caches are maintained to improve the performance by minimizing the latency
- all nodes are responsible for some part of the distributed memory
- the home node is responsible for managing accesses and tracking pages’ ownerships
- some explicate replications can be considered to assist the load balancing, performance, and reliability
(10) Indexing Distributed State
One important aspect of distributed shared memory systems is how do we determine where a particular page is. In order to do this, the DSM component has to maintain some metadata. The page address can be divided into a node identifier plus the page frame number and the node identifier also implies the home node.
Considering the address format, the address will directly identify the manager node’s ID (i.e. home node ID), and a global map can be used by all the nodes on how to find its manager. The manager node will have all the per-page metadata that’s necessary for performing,
- specific accesses to that page
- the consistency of the page
What’s nice about this approach is that there is no need to consider making any kind of changes to the object identifier and the object can remain identified in the exact same way as it was before we chose to make a change into the manager nodes.
(11) DSM Implementing Problem
Based on the previous discussions, the DSM must intercept the access to any of the DSM states,
- to send remote messages for requesting accesses
- to trigger coherence messages
However, when we are accessing a local non-shared state, these operations should be unnecessary and should be avoided. So what we would like to achieve is an implementation where it is possible to dynamically engage whether the distributed shared memory layer will be triggered and will be intercepting any accesses to memory in order to determine what to do about them, or disengage the distributed shared memory layer if we are performing access to pages which are really not shared and are just local pages accessed on a particular node.
(12) DSM Implementing Solution
To support this implementation, the DSM benefits from the supports from hardware MMU. If the state is not found locally or we haven’t got the permission of a state, the current operation will be trapped in the OS and then the OS will detect the cause of that trap and it will then pass that page information to the DSM layer so that the DSM layer can send the messages. Because the DSM has to maintain the coherence of the states, the MMU flags like the dirty bit can be useful for tracking the coherence information.
3. Consistency Models
(1) The Importance of the Consistency Model
In fact, the exact details of how a DSM system should be designed, or how the coherence mechanisms will be triggered depends on the consistency model. Let’s first understand what are the consistency models.
(2) The Definition of the Consistency Models
Consistency models exist in the context of the implementations of applications or services that manage the distributed states, which is a guarantee that the state changes will behave in a certain way as long as the upper software layers follow a certain set of rules and the memory behaves correctly if and only if software follows specific rules. This means that it will guarantees,
- how our memory accesses are going to be ordered
- propagation and visibility of updates
(3) Strict Consistency
Strict consistency is a nice theoretical model but it is not possible to guarantee in both the DSM system and the SMP system unless we use some complex locks and synchronizations that will definitely add to the overheads. The strict consistency means that every single update has to be immediately visible and everywhere visible and the ordering of these updates needs to be preserved.
If we first write x to m1 and then y is written to m2, we should make sure that the reads in P3 should only happen after the writes in P1 and P2 finish. So the reads from memory m1 can only have x, and the read from m2 can only have y.

(4) Sequential Consistency
Given that strict consistency is next to impossible to achieve, the next best option with a reasonable cost is sequential consistency. According to sequential consistency, the memory updates from different processors may be arbitrarily interleaved. However, if we let one process see one ordering of these updates, we have to make sure that all other processes see the exact same ordering of those updates. For example, the following situations are possible,
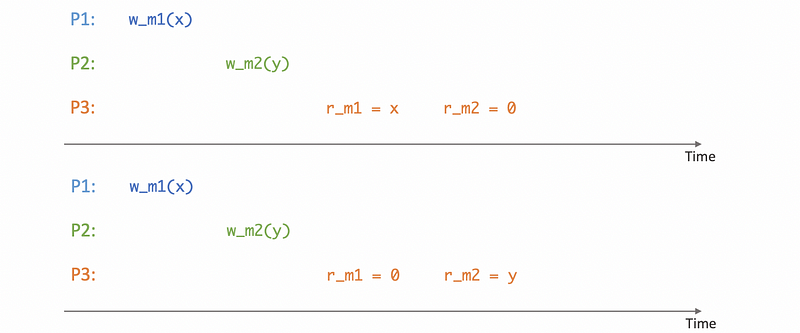
But the following case is not possible,
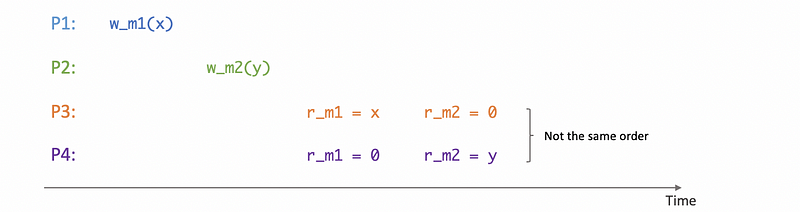
This is because processes P3 and P4 see the same memory in different updating orders.
(5) Causal Consistency
Causal consistency models guarantee that they will detect the possible causal relationship or dependencies between updates. And if updates are causally related then the memory will guarantee that those rights those update operations will be correctly ordered. For example, in the following example, P4 can not be possible because P2 will first read m1 as x and then set the value y to m2. If we read y from m2, then m1 must be set to x already. This is an example that different read-and-write operations have some causal relationships.
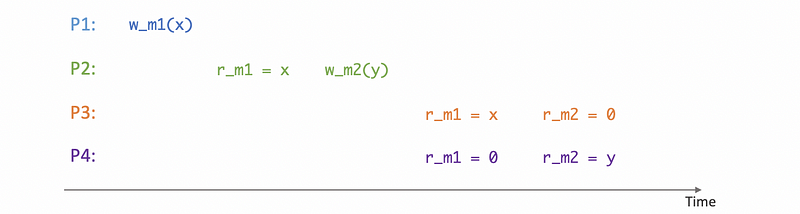
However, the following case is okay for a causal consistency because there’s actually no causal relationships between operations and for writes that are not causally related or they’re referred to in causal consistency as concurrent writes there are no guarantees.
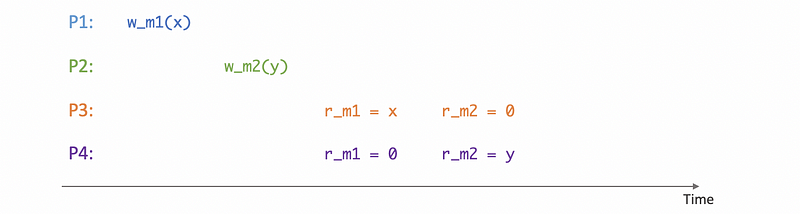
(6) Weak Consistency
In the weak consistency models, it’s possible to have something beyond just read and write operations when memory’s accessed. However, the dependencies of the operations should be maintained and we have to introduce a mechanism called synchronization points. This sync point acts like a boundary and all the operations after this point should have to make sure that all the variables in the system for the entire shared memory should be visible. It makes sure that all of the updates that have happened prior to sync the synchronization point will become visible on other processors. And also synchronization point makes sure that all of the updates that have happened on other processors will become visible subsequently at this particular processor in the future.
The idea benefits from limiting the required data movement to the required messages and coherence separations that will be exchanged among the nodes in the system. But the downside of this is that the distributed shared memory layer will have to maintain some additional state to keep track of exactly what are all the different operations that it needs to support and how it needs to behave when it sees a particular type of request.