Operating System 28 | Final Review for Outlines
Operating System 28 | Final Review for Outlines

- OS Scheduling
(1) Metrics for OS Scheduling
- throughput: task per second
- the average time it took for tasks to complete
- the average time that tasks spent waiting before they were scheduled
- the overall CPU utilization
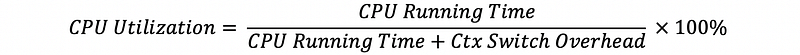
(2) Run-to-Completion Scheduling
As soon as a task is assigned to a CPU, it will run until it finishes or until it completes.
- First-Come, First-Serve (FCFS)
- Shortest-Job First (SJF)
- Complex First
(3) Preemptive Scheduling
Tasks don’t hog (means exclusively occupy) the CPU until they’re completed. We will use the following policy,
- Priority Scheduling: first execute the highest priority
But there can be some problems,
- Starvation: stuck low priority task. The solution is priority aging
- Priority Inverse
(4) Round-Robin Scheduling (RRS)
Round-robin scheduling means that we will looply access all the tasks until they’re completed. There can be two types of RRS,
- Time Slicing
- Without Time Slicing
(5) Run Queue
Active processes are placed in an array called a run queue. We can have different types of run queues,
- Single runqueue: same run queue for I/O (slow) and CPU (fast) -bound tasks
- Multi-runqueue: different run queues for I/O and CPU-bound tasks in the same layer. I/O-bound tasks will have short time slices and CPU-bound tasks have long time slices. This method needs classifications by history-based heuristics.
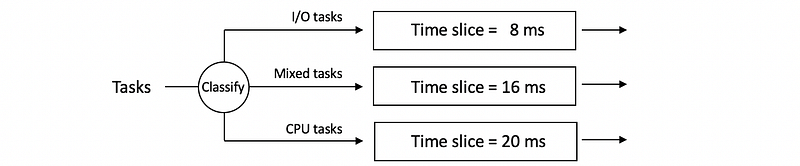
- Multi-Level Feedback Queue (MLFQ): different run queues for I/O and CPU-bound tasks in different layers. We don’t have to do any classification.

(6) Linux Schedulers
- Kernel 2.5: O(1) scheduler, not suitable for interactive tasks
- Kernel 2.6.23 and later: CFS scheduler
(7) I/O-bound Tasks Vs. CPU-Bound Tasks
- I/O-bound Tasks (Memory-bound Tasks): high CPI, low IPC
- CPU-bound Tasks (Compute-bound Tasks): low CPI, high IPC
(8) Conclusion of Fedorova’s Paper
Mixed IPC workloads on each core results in a better performance.
Example 1-1. Run-to-Completion Scheduling and RR Scheduling
Suppose we have three tasks T1, T2, and T3 arrive in the order T1 -> T2 -> T3, which have the following execution time,
T1 = 1 s
T2 = 10 s
T3 = 1 s
For each of the three algorithms (i.e. FCFS, SJF, complex first) with run-to-completion scheduling or RR scheduling with ts = 1s. Calculate,
- throughput
- average completion time
- average waiting time
Solution:
For run-to-completion scheduling with FCFS,
throughput = 3/12 = 0.25 task/s
ACT = (1+11+12)/3 = 8 s
AWT = (0+10+11)/3 = 4 s
For run-to-completion scheduling with SJF,
throughput = 3/12 = 0.25 task/s
ACT = (1+2+12)/3 = 5 s
AWT = (0+1+11)/3 = 1 s
For run-to-completion scheduling with complex first,
throughput = 3/12 = 0.25 task/s
ACT = (10+11+12)/3 = 11 s
AWT = (0+10+11)/3 = 7 s
For RR scheduling (ts = 1s) with FCFS,
throughput = 3/12 = 0.25 task/s
ACT = (1+12+3)/3 = 5.33 s
AWT = (0+1+2)/3 = 1 s
For RR scheduling (ts = 1s) with FCFS,
throughput = 3/12 = 0.25 task/s
ACT = (1+2+12)/3 = 5 s
AWT = (0+1+2)/3 = 1 s
For RR scheduling (ts = 1s) with complex first,
throughput = 3/12 = 0.25 task/s
ACT = (12+2+3)/3 = 5.67 s
AWT = (0+1+2)/3 = 1 s
2. Memory Management
(1) Memory Management Methods
There are two ways to manage memory,
- Page-based: virtual memory is divided into fix-sized pages
- Segment-based: virtual memory is divided into flexible segments
(2) Page Tables
OS generates a page table for every process that it runs, which is used for virtual to physical translation. Page table entry contains flags like,
- Present (P): same as the valid bit
- Dirty (D): if need to write back
- Access (A): show read or write
- Protection (R/W/X): show the permission
(3) Memory Management Unit
MMU is the hardware for supporting memory management. It is responsible for,
- Virtual to physical address translation
- Generate page faults: like the non-existing page (need to read from disk) and protection error
(4) Page Table Size
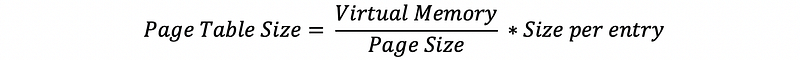
(5) Improving Page Tables
The following ways can be used to improve the page tables. These include,
- Multi-level Page Tables (MLPT): reduce page table cost
- Translation Look-aside Buffer (TLB): faster search to the table
- Inverted Page Tables (IPT): another approach, need to do a linear search
- Hashing Inverted Page Tables (hashing IPT): improving the linear search with hash tables
(6) Descriptor Table
With segments, the address space is divided into components of arbitrary granularity of arbitrary size. The descriptor table is used to translate the virtual address to the linear address.
(7) Segmentation Translation Procedure
Segmentation must be used with paging.

(8) Memory Allocator
The memory allocator is used to allocate memory and it can be implemented at either the user level or the kernel level.
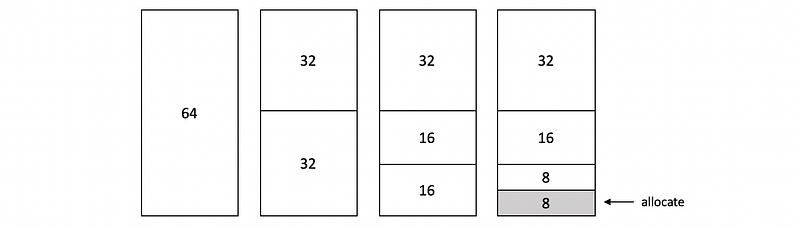
- Buddy memory allocator: The buddy allocator will continue subdividing consecutive memory region until it finds the smallest chunk that’s with a size of a power of 2ⁿ that can satisfy the request. This is fast but has internal fragmentation.
- Slub memory allocator: The slub allocator builds custom object caches on top of slabs, and the slabs themselves represent contiguously allocated physical memory. This avoids internal and external fragmentation.
(9) Copy On Write (COW)
Forked processes continue using the virtual address space of their parent process until we need to perform a write operation.
(10) Demand Paging
Demand paging means that we we store some information on the disk and when we need them, we can load them back from the secondary storage.
(11) Page Replacement
When we memory usage is above the threshold or CPU usage is below the threshold, the pages should be swapped out. We can have some common replacement policies like,
- LRU
- Swap dirty bit = 0 because we don’t have to write back
(12) Failure and Recovery Management
There methods that we can handle the failures and recover from a failure,
- Checkpointing
- Rewind Replay: means to restart from an early point
- Migration: means to restart
3. Inter-Process Communication
(1) Types of Inter-Process Communication (IPC)
- Message-based (message pass) IPC: pipes, message queues, sockets
- Memory-based (shared memory) IPC: shared memory, memory-mapped files
(2) Pipes
Pipes are characterized by only two processes can communicate at a time via the data stream.

(3) Message Queue
Message queue send and receive well-formatted messages between processes.
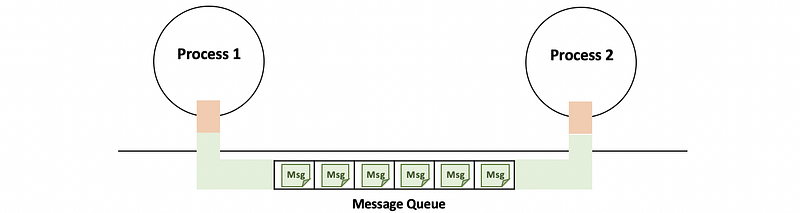
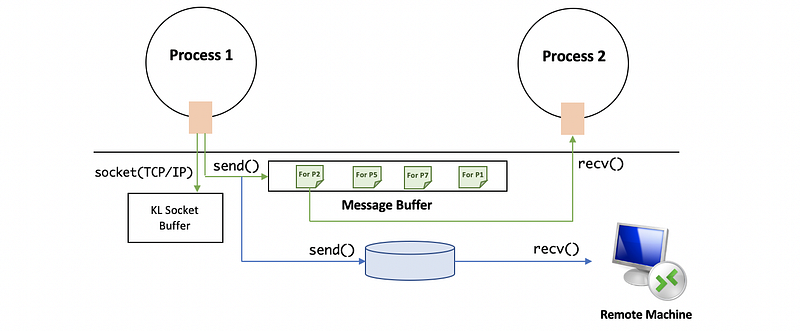
(4) Sockets
Socket is a way to communicate through different protocols by sending or receiving messages.
(5) Sys V Shared Memory IPC
- generate unique key:
ftok(pathname, proj_id) - create segments:
shmget(shmid, size, flag) - attach process:
shmaddr = shmat(shmid, addr, flags) - detach process:
shmdt(shmaddr) - destroy segments:
shmctl(shmid, cmd, buf)
(6) POSIX Shared Memory IPC
- create files:
shm_open() - attach process:
mmap() - detach process:
unmmap() - detech all processes:
shm_close() - destroy allocated resources:
shm_unlink()
4. Synchronization
(1) Spinlocks
Spinlock will be busy and spinning when locking, so it is different from the mutex.
(2) Semaphores
Semaphore is an integer number that will be block when the value equals 0. There are two operations on the semaphore,
- wait: means to reduce 1
- post: means to add 1
(3) Sys V Semaphore
- create semaphore:
sem_t sem; - initialize semaphore:
sem_init(&sem, pshared, count); - semaphore wait:
sem_wait(&sem); - semaphore post:
sem_post(&sem);
(4) Semaphore-Mutex Implementation
Mutex is a specific kind of semaphore. It is equivalent to,
sem_t mutex;
sem_init(&mutex, 0, 1);
(5) Read/Write Lock (RWlock)
The read/write lock is a specific spinlock only for exclusive writes. This is simpler than using the condition variables.
(6) Linux RWlock
- create rwlock:
rwlock_t rwlock; - read lock:
read_lock(&rwlock); - read unlock:
read_unlock(&rwlock); - write lock:
write_lock(&rwlock); - write unlock:
write_unlock(&rwlock);
(7) Monitors
Monitor is a synchronization explicitly specify,
- shared resources
- entry procedures (read or write)
- mutex locks
- condition variables
(8) Other Synchronizations
- serializer: make it easier to define priority, hide explicit use of condition variable
- path expressions: programmer specify regex captures the correct synchronization behavior
- barriers: a barrier will block threads until it figures all of them reach a certain condition
- rendezvous points
- optimistic wait-free synchronization (RCU)
(9) Atomic Instructions
Atomic instructions are exclusively executed instructions. There are three types of them,
test_and_set: if fits the condition, then set the valueread_and_increment: get the value, and then increase itcompare_and_swap: compare the values, and then swap them
(10) Shared Memory Processors (SMP)
The SMP is a system that all the processors will share 1 or more main memory.
(11) Cache Memory Interactions
- Write allocate: means data writes in cache and memory
- Non-write allocate: means data writes only in memory
- Write through: directly write to the memory after write
- Write back: delay write to the memory until being kicked out
(12) Cache Coherence Policies
- Non-Cache-Coherent (NCC): cache coherence supported by software
- Write Invalidate: simply invalidate copies of data after write by hardware
- Write Update: update copies of data after write by hardware
(13) Spinlock Performance
- Latency: low latency
- Delay: low delay time
- Contention: reduce traffic, but this conflict with the other two goals because we have to execute less atomic instructions
(14) Spinlock Implementation
Method #1. Test-then-test Implementation
spinlock_lock(lock):
while(test_and_set(lock) == busy);
- low latency and low delay
- high contention (bad)
Method #2. Test-test-set Implementation
spinlock_lock(lock):
while (1) {
if (lock == free)
while(test_and_set(lock) == busy);
else
while(lock == busy); // wait for lock becomes free
}
- okay latency and delay
- low contention for write update
- high contention for write invalidate (bad)
Method #3. Delay Spinlock
spinlock_lock(lock):
while (1) {
if (lock == free)
while(test_and_set(lock) == busy);
else {
while(lock == busy); // wait for lock becomes free
delay();
}
}
We can use the following two
- static delay: delay static value like CPUid
- dynamic delay: higher contention, large range, randomly choose
The performance will be,
- okay latency
- static delay: unnecessary delay when low contention (bad)
- dynamic delay: high contention and high delay when
test_and_setfails (bad)
Method #4. Queuing Spinlock (Anderson’s lock)
init:
flags[0] = has_lock;
flags[1 ... N-1] = must_wait;
queuelast = 0; // global
lock:
myplace = read_and_increment(queuelast);
// spin
while (flags[myplace%N] == must_wait);
// now in critical section
// finally reset the entry in the queue for next thread
flags[myplace%N] = must_wait;
unlock:
flags[myplace%N + 1] = has_lock;
- high latency (bad): because inefficient
read_and_incrementinstructions - good delay: no wait before next signal
- good contention:
read_and_incrementis only executed once
(15) Spinlock Implementations Performance
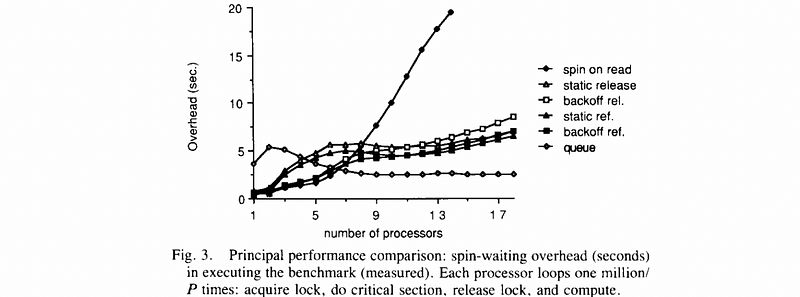
Basic settings are,
- 1~20 processes
- one process per core (1~20 cores)
- overheads is compared with the ideal state (less means better)
- write invalidate
For more cores (higher load),
- queuing lock is the best because good contention
- test-test-set lock (i.e. spin on read) is the worst because of O(N²) high contention
- static delay lock (i.e. static release/ref.) better than dynamic delay lock (i.e. backoff release/ref.) because there are less low contentions
For less cores (lower load),
- test-test-set lock is the best because low latency
- queuing lock is the worst because of high latency
- dynamic delay lock is better than static delay lock because of lower delay
5. I/O Devices
(1) I/O Devices Components
- control registers: includes status registers , command registers , data transfer registers
- micro-controller
- on-device memory
- other logic
(2) Device to CPU Connnections
- Peripheral Component Interconnect Bus (PCI bus)
- Peripheral Component Interconnect Express Bus (PCIe bus)
- Peripheral Component Interconnect Extend Bus (PCI-X bus)
(3) Interconnects
Interconnects are other connects relay on the PCI (main bus).
- SCSI bus: for SCSI disks
- Expansion/Perpherial Bus: keyboards, parallel port, serial port, etc.
- Bridge Controller: connect different interconnects
(4) Device Drivers
Device drivers are device-specific software components responsible for,
- device access
- device management
- device control
(5) Types of Devices
- Block Devices: blocked data like disks supports directly access
- Character Devices: get/put character data like keyboard
- Network Devices: stream data with flexible blocks
(6) Device Files
OS maintain abstractions of devices as device files in the file system. Common device file names are,
tty: special devices representing terminal stationssda/hda: disks like hard drives, SSDs, CD-ROMs, etc.lp: for printersmem: access to the physical memory- etc.
(7) Pseudo Device
Linux also supports what is called pseudo or virtual devices like,
- blackhole:
/dev/null - random string:
/dev/random
(8) CPU-to-Device Interactions
- Memory Mapped I/O: CPU write to device file and PCI send to file
- I/O Port Model: special instructions for accessing a particular device
- Programmed I/O: CPU directly write command and data to device registers
- Direct Memory Access: CPU directly write command to device registers but data is written from the memory based on the DMA controller. We don’t have to send commands many times
(9) Device-to-CPU Interactions
- Interrupt: generate an interrupt to CPU
- Poll: send the device register values to CPU
(10) Device Access Procedure
- perform a system call
- run the in-kernel stack
- invoke the appropriate driver
- performs the configuration of the request to the device
- perform the request
- send back results
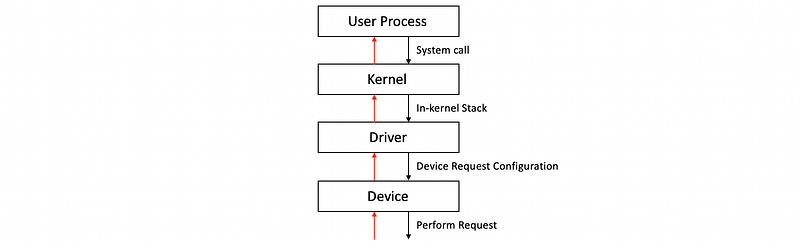
(11) OS Bypass
It’s not necessary to access a device in the kernel mode. Instead, we can used some library supported device accesses, and this is called the OS bypass.

(12) Synchronous Access and Asynchronous Access
- Synchronous Access: Block the process when accessing a device
- Asynchronous Access: Not block the process when accessing a device
(13) Block Device Access Procedure
- User Process: Files
- Kernel: File system
- Driver: Generic block layer that is different types of disks
- Device: Different types of disks
(14) Virtual File System (VFS)
We use virtual file systems because Linux wants to support different file systems.
(15) VFS interface
All the different file system details will be hidden by a virtual file system interface.
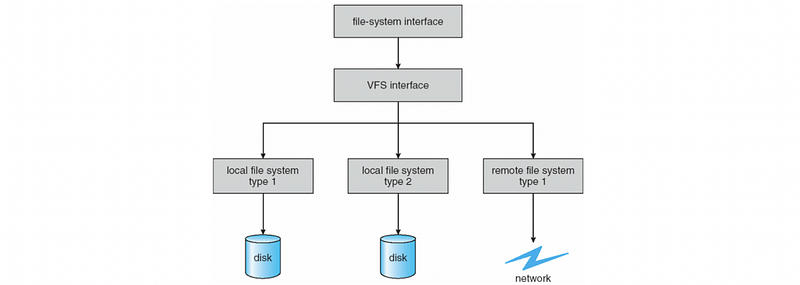
(16) Files
Files are the basic data elements on which VFS operates and the OS describes files as file descripters.
(17) Inode
Inodes are the true file alias that the Linux OS uses because the machine can not understand file names. Each inode can be mapped to a specific file.
(18) Directory
A directory in Linux is a file with its contents including file path — inode pairs called dentry (directory entry).
(19) Inode Data Structure
The inode contains some important information like,
- list of all data blocks
- permission
- size of the file
- whether lock or not
- etc.
(20) Dentry Cache
This is used to speedup the dentry search.
(21) EXT2 File System
- Boot Block: code to boot the computer
- Block Groups: the storage is divided into block groups
- Superblock: info about the overall block group (# of inodes, # of disk blocks, the start of the free blocks)
- Group Descriptor: overall block group state (bitmaps, # of free nodes, total #of directories)
- Bitmaps: used to quickly find a free block or a free inode
- Inodes: each is a 128-byte long data structure that describes exactly 1 file (the owner of the file, accounting information, etc.)

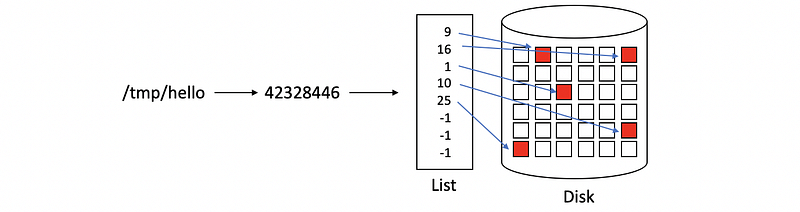
(22) Inode for Data
Because the inode of a file contains a list of all data blocks of a file, we can read from these blocks to get the file data. However, the file size is limited by the inode list length.
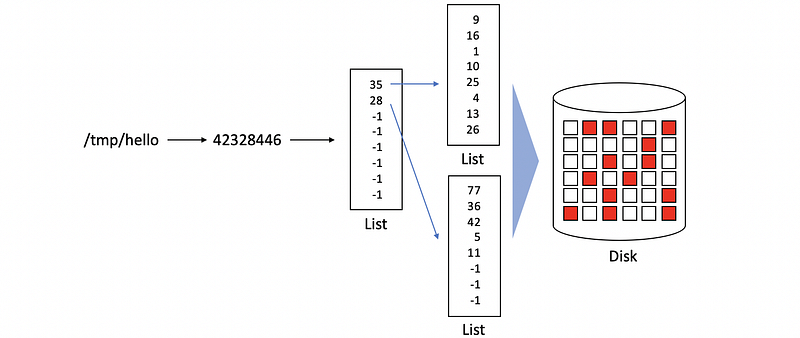
(23) Inode with Indirect Pointers
Indirect pointers can be used for inodes to store a file with a much larger size.
(24) Disk Access Optimization
FS use several techniques to reduce the disk access and disk overheads,
- caching: reduce access
- prefetching: reduce access
- journaling: reduce random access
- I/O scheduling: reduce disk head movements
6. Virtualization
(1) Virtual Machine
Each operating system together with its applications as well as the virtual resources that it pings at us is called a virtual machine.
(2) Virtual Machine Monitor (VMM)
The virtual machine is taken to be an efficient, isolated, duplicate of the real machine, which is supported by a virtual machine monitor (VMM). The VMM is actually the layer that enables VMs to exist. It has the following characters,
- essentially identical to the original machine
- minor decrease in program speed
- complete control of the system resources
(3) Virtualization Reasons
- Consolidation
- Migration
- Security
- Debugging
- Legacy OS
- etc.
(4) Bare-Metal Virtualization (BMV) Model
If all VMs rely only on the VMM, then it is called a bare-metal virtualization model.
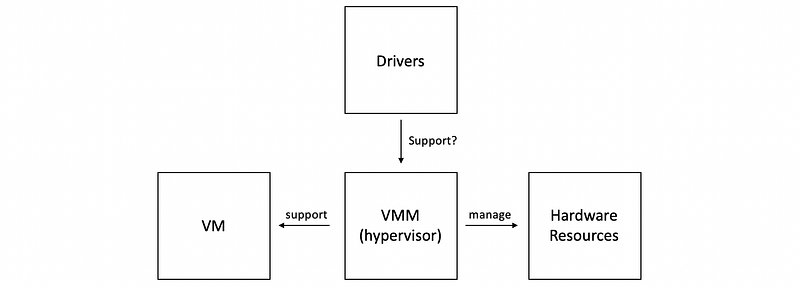
(5) Bare-Metal Virtualization (BMV) with Service VM
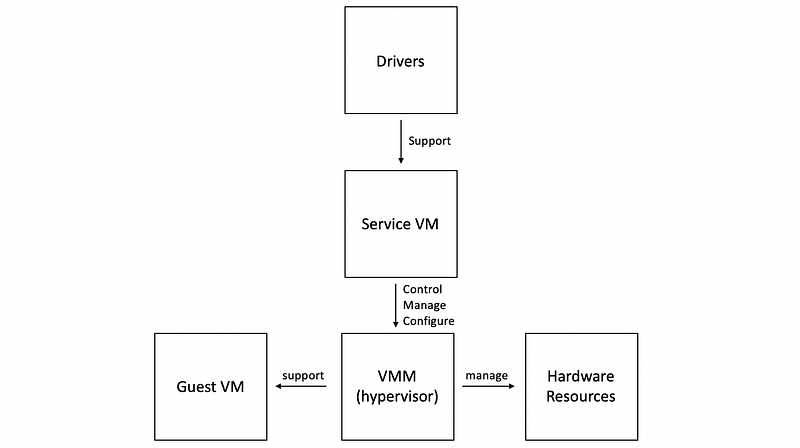
If we have a privilege standard service OS control, manage, and configuring the VMM and other VMs, then it is called a BMV with Service VM. For example, Xen (service VM is dom0), and VMware ESX (service VM are remote APIs).
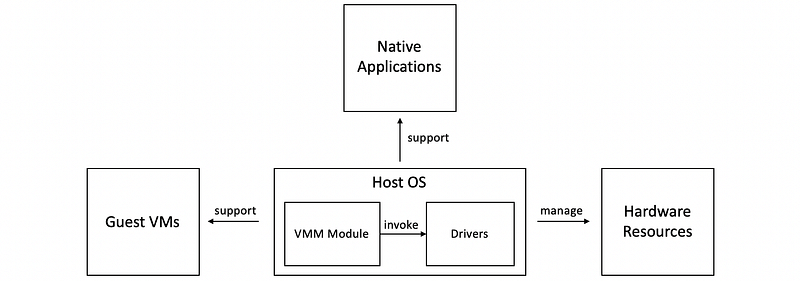
(6) Hosted Virtualization Model
If at the lowest level of the hosted model, there is a full-fledged host OS that manages all of the hardware resources, then this is called a hosted virtualization model. For example, KVM (hardware virtualized by QEMU).
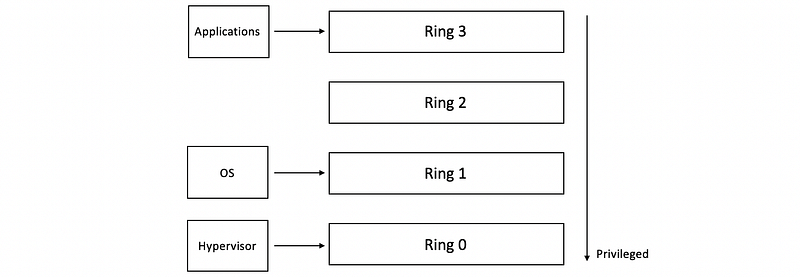
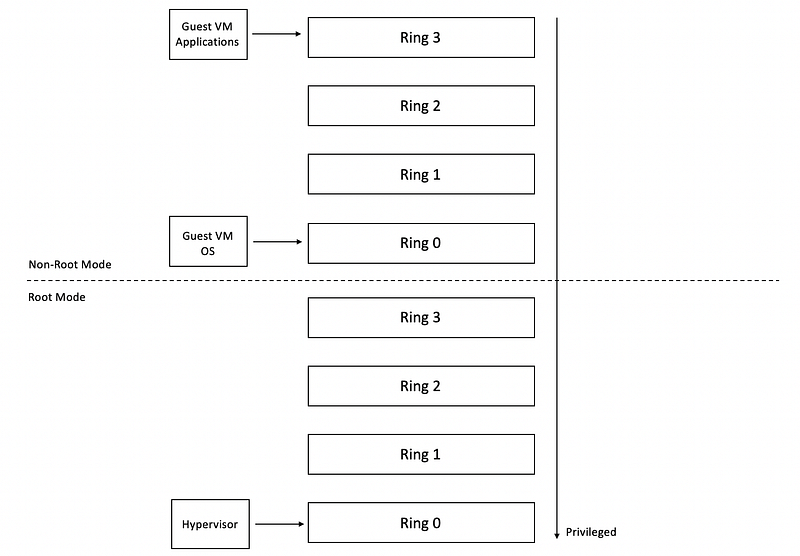
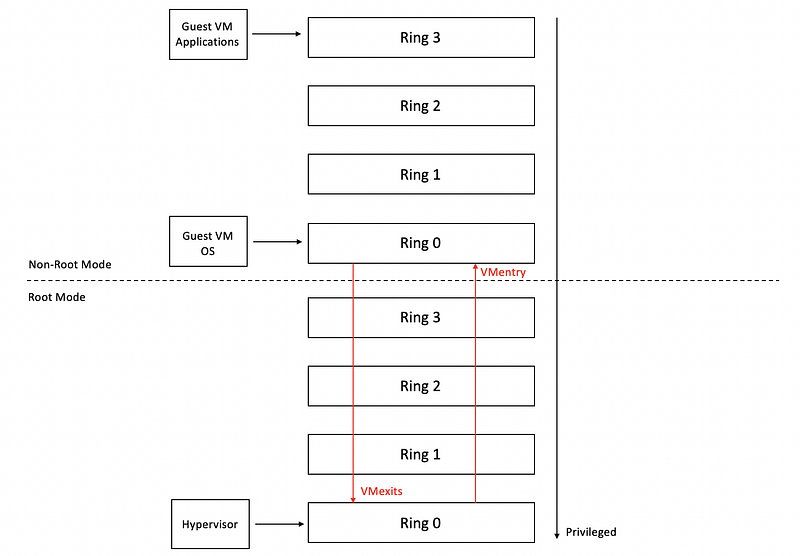
(7) Protection Levels for Virtualization
We have two ways for virtualization protection. We can,
- If all in the non-root mode,
- If all in the root mode,
(8) VMexits and VMentry
Attempts by the guest OS to perform privileged operations are called VMexits. When the hypervisor completes its operation, it passes control back to the virtual machine by performing a VMentry.
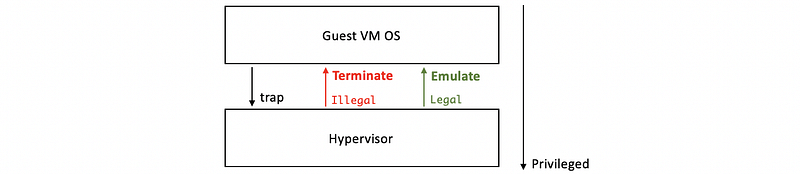
(9) CPU Virtualization
- Trap-and-Emulate Technique: trap to the supervisor, see illegal or legal before emulation. It has a problem because instructions at that time has no trap.
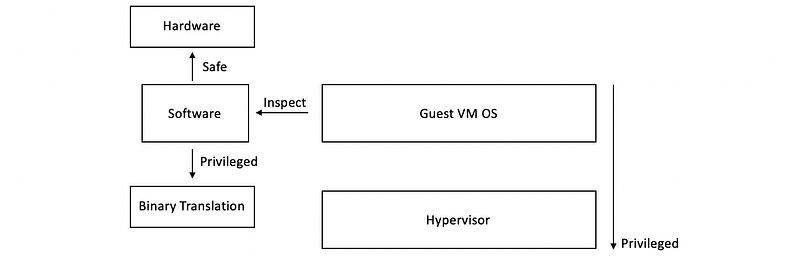
- Binary Translation Technique: use software to detect the instructions that should be trapped
- Full Virtualization: VM doesn’t know it’s virtual.
- Paravirtualization: VM knows it’s virtual so that they can all hypercalls to access the hypervisor. This is popularized by Xen.
(10) Memory Virtualization
- Direct Translation: Direct translation from VA (VMapplication) to PA(VMOS) to MA (hypervisor). Expensive.
- Shadow Page Table: Create shadow page table mapping VA to MA.
- Paravirtualization: No need for the ordinary page table, just a shadow page table is okay and it can use hypercalls to update the shadow page table.
(11) Device Virtualization
- Passthrough Model: get to the device register directly. Exclusive and hard to share
- Hypervisor-Direct Model: get to device register by VMM. Easy to share but complex and slow
- Split Device Driver Model: get to device register by service VM (not through VMM). Reduce overheads and have better management
7. RPC, DFS, DSM, and Cloud Computing
(1) Remote Procedure Calls (RPC)
RPC is an IPC mechanism for cross-machine interactions. It has the complexity of sockets by providing high-level procedure call interfaces.
(2) Client Stub
It seems like an ordinary function in the client but what it does is integrating information in a buffer and send it to the server.
(3) Server Stub
It seems like a function in the server but what it does is unpacking messages from the server, conduct the operation and send the result back.
(4) RPC 9 Steps
- Register: server construct with basic information
- Bind: client finds the server by a database called registry
- Call: client pass information to the client stub
- Marshal: client stub integrate information into the buffer
- Send: the client sends the message buffer to the server
- Receive: server receives the message
- Unmarshal: the server stub unpacks the message into information
- Actual call: get arguments from the information and conduct an actual procedure call
- Result: server stub sends the result back in a message
(5) Interface Definition Language (IDL)
IDLs serve as a protocol of how the agreement of client and server will be expressed. This is useful because the client and server may be written by different developers in different languages.
- Language-agnostic IDL: XDR
- Language-specific IDL: Java RMI
(6) IDL Content
IDL is an agreement between the server and client, which should contain information like,
- procedure names
- argument types
- result types
- version number
(7) RPC Pointers
Passing merely the pointers in a client is useless for the server, so a proper RPC will also pass the data structure related to that pointer called serializing.
(8) RPC Failures
Because RPC is unlikely to provide a detailed error, we will use the error notifications without claiming the details.
(9) Distributed File System
DFS is remote file systems supported by VFS over the network.
(10) 2 Types of DFS Models
- Server Model: DFS is on the server, centralized and difficult to scale
- Peer Model: DFS is on the other machines, easy to scale by adding machines
(11) Types of Remote File Services (RFS)
- Upload-Download Model (UDM): means download, operate, upload. Quick operations but server loses control
- True Remote File Access Model (TRFAM): means RPC, operate, download when necessary. Slow and easily overloaded
- Remote File Service/Access Model (RFAM): a combination of UDM and TRFAM. If the client has data in local memory, operate, broadcast, upload when kicked out. If the client doesn’t have data in local memory, RPC, operate, download when necessary.
(12) Types of Servers
- Stateless server: server doesn’t contain state information from the client. Need self-described messages from the client
- Stated server: server contains state information from the client. Need Checkpointing
(13) DFS Cache Coherence
We have to maintain state information of caches on the client and server by file-sharing policies called semantics.
- Session Semantics: write back when close, get the latest by open
- Periodic Updates: write back periodically, get the latest by open
- Immutable Files: simply only-read policy
- Transaction: API supported policies
(14) DFS Replication
There are two ways for DFS replication because we need some fault tolerance,
- Replication: extra servers for a copy of all the files
- Partitioning: each server stores only a part of all the files
(15) DFS Examples
- NFSv3: stateless
- NFSv4: stated
- Sprit DFS: periodic updates
(16) DSM
DSM is a service that manages the memory across multiple nodes.
- Hardware Supported DSM: supported NIC
- Software Supported DSM
(17) Memory Sharing Granularity
- Variables: bad
- Pages or Objects: better, but will have false sharing problems.
(18) Memory Access Algorithms
- Single reader, single writer (SRSW): simplest but not commonly used
- Multiple readers, single writer (MRSW) or Multiple readers, multiple writers (MRMW): should maintain write order and consistency
(19) DSM Performance Metrics
The main metric for measuring DSM performance is the latency.
(20) DSM Optimization
- Migration: if access then move
- Replication: if access then copy
(21) DSM Consistency
- push invalidations when write
- pull periodically on demand
(22) Memory Consistency Models
- Strict Consistency: all accesses strictly in the give sequence
- Sequential Consistency: different processes see accesses in the same order
- Causal Consistency: one process sees accesses in order
- Weak Consistency: no consistency guarantee, need synchronization
(23) Types of Internet Services
- presentations: static
- business logic: dynamic
- database tier: data storage and management
(24) Cloud Computing Functions
- shared resources
- APIs for different services
- billing and accounting
(25) Cloud Deployment Models
- public model
- private model
- hybrid model
- community model
(26) Cloud Service Models
- Infrasture as a service (aka. IaaS) Model: Amazon EC2
- Platform as a service (aka. PaaS) Model: google APPs
- Software as a service (aka. SaaS) Model: Gmail
(27) Cloud Requirements
- fungible resources
- elasticity and flexibility
- scalability
- failure tolerance and exception handling
- isolation for multi-tenancy
- security
(30) Cloud Technique Implementations
- Virtualization
- Resource provisioning
- Big Data
- Software
- Monitoring