Operating System 29 | Final Review for Special Topics and Quizzes
Operating System 29 | Final Review for Special Topics and Quizzes

- OS Scheduling
(1) Linux O(1) Scheduler
0 being the highest (ts = 100 ms) and 139 (ts = 10 ms) is the lowest. The default level is 120. The pointer of the two arrays should be swapped.
- O(1) Vs. CFS: CFS is better for interactive operations.
(2) Fedorova’s Paper
Conclusion: workloads of mixed CPI result in better performance
Problem: real workload CPIs have little difference
Example 1-1. Round-Robin Scheduler
On a single CPU system, consider the following workload and conditions:
- 10 I/O-bound tasks and 1 CPU-bound task
- I/O-bound tasks issue an I/O operation once every 1 ms of CPU computing
- I/O operations always take 10 ms to complete
- Context switching overhead is 0.1 ms
- I/O device(s) have an infinite capacity to handle concurrent I/O requests
- All tasks are long-running
Now, answer the following questions (for each question, round to the nearest percent):
a. What is the CPU utilization (%) for a round-robin scheduler where the timeslice is 1 ms?
b. What is the CPU utilization (%) for a round-robin scheduler where the timeslice is 10 ms?
c. What is the CPU utilization (%) for a round-robin scheduler where the timeslice is 20 ms?
d.What is the I/O utilization (%) for a round-robin scheduler where the timeslice is 1 ms?
e.What is the I/O utilization (%) for a round-robin scheduler where the timeslice is 20 ms?
Solution:
Workload Summary:
For 10 I/O-bound tasks,
- being issued every 1 ms
- completing in 10 ms
- infinite capacity
For 1 CPU-bound task,
- fully occupy the CPU
For context switching,
- 1 ms each
a.
With RR scheduler with 1 ms time slice and all the tasks are long-run (means they will looply execute and never stops),
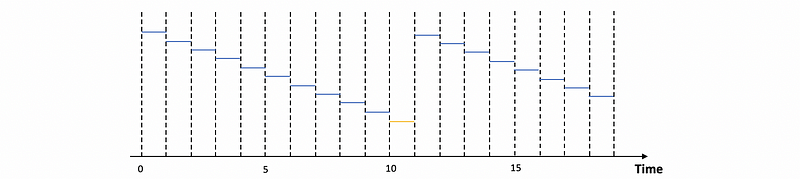
The CPU utilization should be,
task CPU Time = 1 ms
Context Switch = 0.1 ms
CPU utilization = task CPU Time / (Context Switch + task CPU Time) = 91%
b.
With RR scheduler with 10 ms time slice and all the tasks are long-run, only the CPU-bound task can fully utilize the full-time slice of 10 ms,
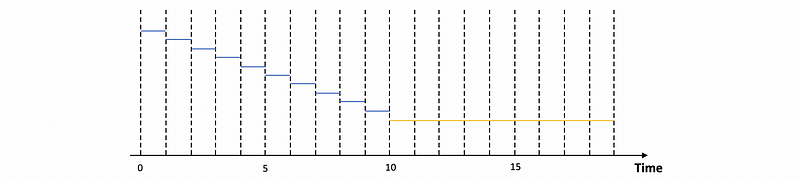
so the CPU utilization should be,
I/O CPU Time = 1 ms
Comp CPU Time = 10 ms
Context Switch = 0.1 ms
CPU utilization = (10 * 1 ms + 1 * 10 ms) / (10 * 1 ms + 1 * 10 ms + 0.1 ms * 11) = 20/21.1 = 95%
c.
With RR scheduler with 20 ms time slice and all the tasks are long-run, only the CPU-bound task can fully utilize the full-time slice of 20 ms. The CPU utilization should be,
I/O CPU Time = 1 ms
Comp CPU Time = 20 ms
Context Switch = 0.1 ms
CPU utilization = (10 * 1 ms + 1 * 20 ms) / (10 * 1 ms + 1 * 20 ms + 0.1 ms * 11) = 30/31.1 = 96%
d.
For I/O utilization,
- the first I/O request is issued at 1 ms time
- the last I/O request is issued at,
10 * 1ms + 9 * 0.1 = 10.9 ms
- the last I/O request is finished at,
10.9 ms + 10 ms = 20.9 ms
- Total time from I/O processing should be,
20.9 ms - 1 ms = 19.9 ms
- the CPU bound task will complete at,
10 * 1 ms + 1 * 1 ms + 11 * 0.1 = 12.1 ms
- Because all the I/O bound tasks will not finish when the CPU bound task, so we will have an I/O utilization of,
100%
e.
For I/O utilization,
- the first I/O request is issued at 1 ms time
- the last I/O request is issued at,
10 * 1ms + 9 * 0.1 = 10.9 ms
- the last I/O request is finished at,
10.9 ms + 10 ms = 20.9 ms
- Total time from I/O processing should be,
20.9 ms - 1 ms = 19.9 ms
- the CPU bound task will complete at,
10 * 1 ms + 1 * 20 ms + 11 * 0.1 = 31.1 ms
- Because all the I/O bound tasks finish before CPU bound task completes, so we will have an I/O utilization of,
I/O utilization = 19.9 / 31.1 = 64%
Example 1-2. Linux O(1) Scheduler
For the next four questions, consider a Linux system with the following assumptions:
- uses the O(1) scheduling algorithm for time-sharing threads
- must assign a time quantum for thread T1 with priority 110
- must assign a time quantum for thread T2 with priority 135
Provide answers to the following:
a. Which thread has a “higher” priority (will be serviced first)?
b. Which thread is assigned a longer time quantum?
c. Assume T2 has used its time quantum without blocking. What will happen to the value that represents its priority level when T2 gets scheduled again (lower/decrease, higher/increase, same) ___________.
d. Assume now that T2 blocks for I/O before its time quantum expired. What will happen to the value that represents its priority level when T2 gets scheduled again (lower/decrease, higher/increase, same) ___________.
Solution:
Lower level value has higher priority and longer time slice (quantum), so
a. thread T1
b. thread T1
c. higher/increase. Because without blocking means that we have a longer time quantum, so in the next schedule, the time quantum of it will be reduced by increasing the level value
d. lower/decrease. expire means that we have a shorter time quantum, so in the next schedule, the time quantum of it will be increased by reducing the level value
Example 1–3. Hardware Counter
Consider a quad-core machine with a single memory module connected to the CPUs via a shared “bus”. On this machine, a CPU instruction takes 1 cycle, and a memory instruction takes 4 cycles.
The machine has two hardware counters:
- counter that measures IPC
- counter that measures CPI
Answer the following:
a. What does IPC stand for in this context? ____________
b. What does CPI stand for in this context? ____________
c. What is the highest IPC on this machine? ____________
d. What is the highest CPI on this machine? ____________
e. Suppose we have the following long-running workloads of 8 memory instructions and 8 CPU instructions. Which one will perform better? Select all that’s apply. ____________
- A.
Core 1: 4 memory instructions
Core 2: 4 memory instructions
Core 3: 4 CPU instructions
Core 4: 4 CPU instructions
- B.
Core 1: 4 memory instructions
Core 2: 4 CPU instructions
Core 3: 4 memory instructions
Core 4: 4 CPU instructions
- C.
Core 1: 1 memory instructions and 3 CPU instructions
Core 2: 3 memory instructions and 1 CPU instructions
Core 3: 4 memory instructions
Core 4: 4 CPU instructions
- D.
Core 1: 1 memory instructions and 3 CPU instructions
Core 2: 3 memory instructions and 1 CPU instructions
Core 3: 2 memory instructions and 2 CPU instructions
Core 4: 4 CPU instructions
- E.
Core 1: 2 memory instructions and 2 CPU instructions
Core 2: 2 memory instructions and 2 CPU instructions
Core 3: 2 memory instructions and 2 CPU instructions
Core 4: 2 memory instructions and 2 CPU instructions
- F.
Core 1: 1 memory instructions and 3 CPU instructions
Core 2: 3 memory instructions and 1 CPU instructions
Core 3: 2 memory instructions and 2 CPU instructions
Core 4: 2 memory instructions and 2 CPU instructions
Solution:
a. Instruction per cycle
b. Cycles per instruction
c. 4. In the extreme case, if we only have CPU instructions on each core, we will have an IPC of 4.
d. 16. In the extreme case, of we have only memory instructions on each core, these instructions will contend on the shared bus and the shared memory controller. So in the worst case, they can take up to 4*4 = 16 cycles for one instruction to complete.
e. EF. If we have a mixed CPI on each core, we can have better performance.
Example 1-4. Multilevel Feed Back Queue
Consider a system that has a CPU-bound process, which requires a burst time of 40 seconds. The multilevel feedback queue scheduling algorithm is used and the queue time quantum 2 seconds and in each level it is incremented by 5 seconds. Then how many times the process will be interrupted and on which queue the process will terminate the execution?
Solution:
The process is interrupted 4 times and completes on queue 5.
- At Queue 1 it is executed for 2 seconds and then interrupted and shifted to queue 2.
- At Queue 2 it is executed for 7 seconds and then interrupted and shifted to queue 3.
- At Queue 3 it is executed for 12 seconds and then interrupted and shifted to queue 4.
- At Queue 4 it is executed for 17 seconds and then interrupted and shifted to queue 5.
- At Queue 5 it executes for 2 seconds and then it completes.
Example 1-5. CPU Scheduling
Consider a scenario with the following 3-task workload:
- T1 is I/O-bound but needs 3ms of CPU time
- T2 and T3 are CPU-bound and need 4ms and 5ms of CPU time, respectively.
- T1 issues an I/O request after 1ms of CPU time.
- I/O requests take 2 ms to complete.
- The scheduling algorithm runs in 0.2ms
- A context switch costs 0.3ms
- Tasks arrive in the order 1, 2, 3.
Suppose we have a round-robin scheduler with 2ms timeslices. Answer:
a. What are the basic steps involved in scheduling a thread on the CPU?
b. What are the basic data structures involved in scheduling a thread on the CPU?
c. Calculate the throughput of this workload.
d. Calculate the average completion time of this workload.
e. Calculate the average waiting time of this workload.
f. Calculate the CPU utilization of this workload.
g. Calculate the I/O utilization of this workload before it finishes.
h. What if the I/O requests take 5 ms to complete? Will the result change? Explain your answer.
Solution:
a.
- idling: when the CPU becomes idle, we can start scheduling
- preemption: kernel sends a signal to interrupt the current task
- prioritization: kernel prioritizes a new task based on the priority
- timeslice expiration: once the timeslice expires, the scheduler needs to determine who is allotted the next timeslice.
b. The CPU scheduling relies on,
- Scheduling policies: for example, FCFS, SJF, complex first, etc.
- Runqueue: store the tasks and enable specific decision-making
c.

total CPU time = 3 + 4 + 5 = 12 s
# of ctx switches = 5
# of schedulings = 6
total time = total CPU time + # of ctx switches * 0.3 + # of schedulings * 0.2
= 12 + 5 * 0.3 + 6 * 0.2
= 12 + 1.5 + 1.2
= 14.7 s
Therefore, the throughput is,
throughput = 3/14.7 = 0.204 tasks/sec
d.
T1 starts at 0s
T2 starts at 0 + 1 + 0.2 + 0.3 = 1.5 s
T3 starts at 1.5 + 2 + 0.2 + 0.3 = 4 s
T1 finishes at 4 + 2 + 0.2 + 0.3 + 2 = 8.5 s
T2 finishes at 8.5 + 0.2 + 0.3 + 2 = 11 s
T3 finishes at the end = 14.7 s
Therefore, the avg. comp time = (8.5 + 11 + 14.7) / 3
= 11.4 s
e.
Similarly, the avg. waiting time = (0 + 1.5 + 4) / 3
= 5.5 / 3 = 1.83 s
f.
CPU utilization = total CPU time / total time
= 12/14.7
= 81.6%
g.
I/O utilization = I/O time / total time
= 2/14.7
= 13.6%
h.
No. The result will not change because the second schedule of T1 is at the time 6.5 s, and T1 starts I/O at 1 s. The time interval is 5.5 s and it is larger than the I/O time of 5 s.
2. Synchronization
Example 2-1. Spinning and Blocking
In a multiprocessor system, a thread is trying to acquire a locked mutex.
a. What is the main difference between spinning and blocking.
b. Should the thread spin or block until the mutex is released?
c. Why might it be better to spin in some instances?
d. What if this were a uniprocessor system?
Solution:
a. When spinning, the current thread will continue occupy the lock, while for blocking, the current thread will be context switched to some other threads.
b. When the current thread requires resources that is occupied by another core, we should spin. When we currect thread requires resources that is occupied by the current core, we should block.
c. Because the owner of the lock may release it in a time smaller than the cost of context switching twice.
d. We can not use spinlocks for a uniprocessor system or the only CPU will be occupied with no exits.
Example 2-2. Spinlock Implementations Performance
For the following question, consider a multi-processor with write-invalidated cache coherence.
Determine whether the use of a dynamic (exponential backoff) delay has the same, better, or worse performance than a test-and-test-and-set (“spin on read”) lock. Then, explain why by making a performance comparison using each of the following metrics:
- Latency
- Delay
- Contention
Solution:
a. Better when we have less cores and lower loads. This is because the test-and-test-and-set lock is simple and the latency and delay is better. We don’t have to worry about contention when we have lower loads. However, because the delay time for dynamic delay lock is frequently unnecessary, the performance will be worse.
b. Worse when we have more cores and higher loads. This is because the test-and-test-and-set lock O(N²) high contention and dynamic delay lock is better.
c. Same when we have medium cores and medium loads. It is possible that at a specific load, those different approaches will result in the same performance.
3. Memory, Storage, and I/O Devices
Example 3-1. Page Table Size
Consider a 32-bit (x86) platform running Linux that uses a single-level page table. What are the maximum number of page table entries when the following page sizes are used?
a. regular (4 kB) pages?
b. large (2 MB) pages?
Solution:
a.
Page size = 4 kB => log2(4*1024) = 12 bit page offsets
32 bit platform => 32 - 12 = 20 bits of tag
Therefore, we can have 2^20 tags
So the maximum number of page table entries is 2^20.
b. Similarly,
Page size = 2 MB => log2(2*1024*1024) = 21 bit page offsets
32 bit platform => 32 - 21 = 11 bits of tag
Therefore, we can have 2^11 tags
So the maximum number of page table entries is 2^11.
Example 3-2. PIO and DMA
Answer the following questions about PIO:
a. Considering I/O devices, what does PIO stand for?
b. List the steps performed by the OS or process running on the CPU when sending a network packet using PIO.
c. Considering I/O devices, what does DMA stand for?
d. Explain why DMA can improve the performance of PIO?
Solution:
a. Programmed I/O: CPU directly write command and data to device registers
b. The steps are,
- write ‘command’ to the device to send a packet of appropriate size
- copy the header and data in a contiguous memory location
- copy data to NIC/device data transfer registers
- read status register to confirm that copied data was successfully transmitted
- repeat the last two steps as many times as needed to transmit the full packet, until the end-of-packet is reached.
c. Direct Memory Access: CPU directly write command to device registers but data is written from the memory based on the DMA controller.
d. DMA will be used to transfer data. So we perform 1 store instruction and 1 DMA configuration instead of many times CPU accesses based on the size of the transferred data.
Example 3–3. Inode
Assume an inode has the following structure:
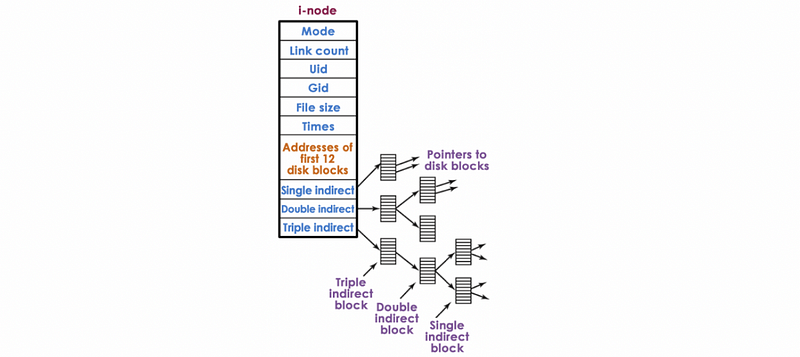
Also, assume that each block pointer element is 4 bytes.
If a block on the disk is 4 kB, then what is the maximum file size that can be supported by this inode structure?
Solution:
Block size = 4 kB
Pointers in a block = 4 kB / 4 B = 1024 pointers
// For the single indirect pointer layers,
Size1 = Pointers in a block * Block size = 4 * 1024 kB
// For the double indirect pointer layers,
Size2 = (Pointers in a block)^2 * Block size = 4 * (1024)^2 kB
// For the triple indirect pointer layers,
Size3 = (Pointers in a block)^3 * Block size = 4 * (1024)^3 kB
// In total, approximately
Size = Size1 + Size2 + Size3 = 4 * (1024)^3 kB
= 4 * (1024)^2 MB
= 4 * 1024 GB
= 4 TB
4. RPC and DFS
(1) Consistency Models
- Strict: All writes are in strict order
- Sequential: All writes are in the same order
- Causal: Some writes are in the order implied by some reads
- Weak: No specific order or writes
Example 4-1. XDR Complier
An RPC routine get_coordinates() returns the N-dimensional coordinates of a data point, where each coordinate is an integer. Write the elements of the C data structure that corresponds to the 3D coordinates of a data point.
Solution:
Because N is not specified, we have to use the variable-length array data type in the XDR file, and it should be defined by,
int coordinate<M>;
where M is the maximum value of N (means N ≤ M).
When this is compiled in C, this will translate into a data structure that has two fields, an integer len that corresponds to the actual size of this array and a pointer val that is the address of where the data in this array is actually stored.
struct coordinate {
int len;
int *val;
};Example 4-2. DFS Semantics
Consider the following timeline where ‘f’ is distributed shared file and P1 and P2 are processes:

Assume the original content of file f was 'a'. For each of the following DFS semantics, what will be read by P2 when t = 4s?
- UNIX semantics
- NFS semantics
- Sprite semantics
Solution:
Unix works by updating immediately to the server. the second something happens in P1 or P2, everyone knows about it. So for UNIX semantics, we will read 'ab'.
For NFS (session semantics + periodic update), it works is that it updates the server once the writer for P1 is closed and when we open a file, we will directly read from the memory. So we will read 'a'.
For Sprite semantics, we will open the file in the process that is currently writing. Therefore, it will read 'ab'.
Example 4-3. Causal Consistency
Consider the following sequence of operations by processors P1, P2, and P3 which occurred in a distributed shared memory system:

Answer the following questions:
a. Name all processors (P1, P2, or P3) that observe causally consistent reads.
b. Is this execution causally consistent?
Solution:
a. P1 and P2. W_m1(3)@P1 and W_m1(2)@ P2 are causally related (via R_m1(2) @P1), so these two writes cannot be seen in reverse order, as currently seen by P3. P3 doesn’t observe causally consistent reads.
b. No. P3 doesn’t follow causal consistency. We can not read 2 from m1 after we read 3 from it because of the causal consistency between P1 and p2.
Example 4-4. Distributed Applications
You are designing the new image datastore for an application that stores users’ images (like Picasa). The new design must consider the following scale:
- The current application has 30 million users
- Each user has on average 2,000 photos
- Each photo is on average 500 kB
- Requests are evenly distributed across all images
Answer the following:
a. Would you use replication or partitioning as a mechanism to ensure high responsiveness of the image store?
b. If you have 10 server machines at your disposal, and one of them crashes, what’s the percentage of requests that the image store will not be able to respond to, if any?
Solution:
a. Partitioning. The current data set is ~30 PB, so cannot store it on one machine
b. 10% since requests are evenly distributed on 10 server machines.
Example 4-5. Weak Consistency
Let’s suppose we have the following sequence of operations by processors P1, P2, and P3,

Then answer the following questions,
a. Consider the following sequence of operations. Is this execution weakly consistent? (Yes/No) ______________
b. If you ignore the sync operations, is this execution causal consistency? (Yes/No) ______________
Solution:
a. Yes. This is weakly consistent.
b. No. There will not be any causal consistency because only one process has the operation order.
Example 4-6. Consistency Models
Choose the correct consistency model that defines the following conditions:
I. All Writes are propagated to other processes, and all Writes done elsewhere are brought locally, at a sync instruction.
II. Accesses to sync variables are sequentially consistent
III. Access to sync variable is not permitted unless all Writes elsewhere have completed
IV. No data access is allowed until all previous synchronization variable accesses have been performed
- A. Weak consistency
- B. Causal consistency
- C. Sequential consistency
- D. Strict consistency
Solution: A. Weak consistency
Example 4-7. DFS Caching
Caching is an important optimization technique. Describe the three potential locations for caching in a distributed file system. Briefly discuss the advantages and disadvantages of each location.
Solution:
- Client memory/client buffer cache: for the regular file system, fast but small
- Client storage device (HDD/SSD): slow but large
- Buffer cache in memory on server: the hit rate depends on how many clients are accessing the server and how many of them are interleaved
Example 4-8. Stated Server Vs. Stateless Server
Answer the following questions:
a. What are the advantages of a stateless distributed file server?
b. What are the advantages of a stated distributed file server?
c. What are the disadvantages of a stateless distributed file server?
d. What are the disadvantages of a stated distributed file server?
Solution:
a.
• Stateless server is more robust than stateful file server, hence they provide fault tolerance.
• Lost connections can't leave a file in an invalid state.
• Rebooting the server does not lose state information.
• Rebooting the client does not confuse a stateless server.
b.
• It is simple.
• Fewer disk accesses are needed at server side.
• Server knows if the file was opened for sequential access, and hence can read ahead the next blocks.
• It reduces the network traffic as client need not send state information with every call to server.
c.
• As the server doesn't maintain any state information about file processing activity, it cannot detect and discard duplicate requests from client.
• To ensure consistency of files, the requests made by clients must be idempotent.
• The stateless file server incurs performance penalty due to:
• The file server opens the file at every file operation.
• When client performs write operation, the changes are needed to be reflected in disk copy of the file.
• Stateless file server cannot employ file caching or disk caching.
d.
• When the client crashes, the file processing activity should be abandoned, and the file state should have to be restored to its previous consistent state, so that the client can restart its file processing activity.
• The resources allocated to aborted file processing should have to be released.
• When the server crashes, the state information stored in file server metadata is lost, hence the file processing activity should be terminated. Thus client knows about server crashes.
Example 4–9. RPC Details
Answer the following questions:
a. If the caller machine (client) in an RPC crashes while waiting for a reply, we say that the computation which was initiated on the callee machine is an “orphan”. Properly terminating orphan computations is called the orphan elimination problem. What sort of issues makes orphan elimination difficult in RPC systems?
b. Under what circumstances might an RPC-based program be less efficient than a carefully optimized message-based program?
Solution:
a. When we have an orphan, the RPC runtime will not be able to provide some better understandings of what’s going on. And they will provide a new type of error notification that tries to capture what goes wrong with an RPC request without claiming to provide the exact detail. Thus, we have to manually look into the log files or binary files to find out what goes wrong. This process of locating error details will be costly and this will also make orphan elimination difficult.
b. Message-based program allows sending all data in a single payload and able to finish in one call. So there is no need to wait. In this situation, it is better.
5. Virtualization
Example 5-1. Virtualization Examples
Fill in the following blanks with which virtualization model they are by bare-metal virtualization (B, aka. Type I hypervisor) or hosted virtualization (H, aka. Type II hypervisor).
- Microsoft Hyper-V ____________
- Citrix Xen ______________
- VMware ESX ____________
- Kernel-based VM (KVM) _____________
- Oracle VM for x86 ____________
- VMware Fusion ____________
- Oracle Virtual Box ______________
Solution:
- B
- B
- B
- H
- H
- H
- H
Example 5–2. VMware’s x86 VMM
Which of the following statements about VMware’s x86 virtual machine monitor are true or false? Explain.
- The x86 architecture originally contained instructions that were non-virtualizable using trap-and-emulate virtualization.
- Shadow page tables store the mappings from guest physical to host physical memory addresses.
- VMware’s VMM prevents the guest from accessing the memory used for the VMM’s internal state by unmapping the corresponding entries in the guest’s page table.
- VMware’s binary translation-based VMM translates guest kernel-mode instructions but not guest user-mode instructions.
- A monitor using hardware-assisted virtualization (Intel’s VT-x or AMD-V) is always faster than one using binary translation.
Solution:
- True. For example, the
popfinstruction in x86 was originally non-virtualizable using trap-and-emulate. - False. Shadow page tables store the mappings from guest virtual memory to host physical memory addresses.
- False. Permission bits in page tables do not allow for execute-only mappings, which are needed for the Translation Cache. The VMM’s own data must be accessible to translated code but not the original guest instructions, even though both run at the same privilege level. Thus, memory segmentation is used to prevent the guest from accessing the VMM’s internal state.
- True. Why we use binary translation-based VMM is because we want to trap to the kernel, and only the kernel instructions need to conduct operations like that.
- False. Binary translation can also have some optimizations that will result in better performance.
6. IPC
Example 6-1. Shared-Memory IPC
Answer the following questions,
a. What’s the difference between a shared memory id (shmid) and a shared memory key?
b. How does the kernel actually implement shared memory segments?
Solution:
a.
If provided that certain limits of the segments are met, then it assigns to it a shmid. This key is used to uniquely identify the segment within the OS, and any other process can refer to this particular segment using this shared memory id.
key refers to the value which is given in reference to IPC resources like shared memory, message queues, and semaphores.
b.
The kernel supports segments of the shared memory that don’t need to be contiguous physical pages. These segments are system-wide and there is a limit for the total number of these segments. In today’s Linux system, this is not an issue because we can use up to 4,000 segments. However, in the past, we can only use 6 segments. When a process requests that a shared memory segment is created, the OS allocates the required amount of physical memory.
Final Example. Potpourri
a. True or False
- Test-and-set instruction used for synchronization needs to be performed in the kernel mode.
- Marshaling is the process by which Byzantine Generals are forced into making good decisions.
- A Remote Procedure Call (RPC) can be used to call a procedure in another process on the same machine.
- With the NFS distributed file system, it is possible for one client to write a value into a file that is not seen by another client when reading that file.
a.
F // user mode
F // the process of packaging data items
T
T