Understanding the Rules of the Regular Expressions
Understanding Rules of the Regular Expressions

- Basic Setup
To start our practice, let’s first of all create a meaningless text by vim on your computer and put this file in the path /tmp named meaningless.txt.
The command should be,
$ vi /tmp/meaningless.txt
The text should be,
Cultivated who resolution connection motionless did occasional. Journey promise if it colonel. Can all mirth abode nor hills added. Them men does for body pure. Far end not horses remain sister. Mr parish is to he answer roused piqued afford sussex. It abode words began enjoy years no do no. Tried spoil as heart visit blush or. Boy possible blessing sensible set but margaret interest. Off tears are day blind smile alone had.
Let’s check it out by,
$ cat /tmp/meaningless.txt
Also, add a command in your configuration file ~/.bashrc, this option of grep makes it possible for us to show the highlights of the terms matching the regular expression,
Firstly,
$ vi ~/.bashrc
Then add,
export GREP_OPTIONS='--color=always'Use the following command to make the change works,
$ source ~/.bashrc2. grep By Regular Expression
The -E option of the grep command allows us to get the matching terms,
$ grep -E <Regex> <path/filename>
- grab all characters matching a specific character
$ grep -E 'n' /tmp/meaningless.txt

- grab all strings matching a specific string
$ grep -E 'no' /tmp/meaningless.txt

- Note that the regular expression is case sensitivity
$ grep -E 'It' /tmp/meaningless.txt

$ grep -E 'it' /tmp/meaningless.txt

- grab any character (. means any single character)
$ grep -E '.' /tmp/meaningless.txt

- grab ‘no’ plus any character
$ grep -E 'no.' /tmp/meaningless.txt

Note that space is also a character.
- grab ‘no’ plus any two characters
$ grep -E 'no..' /tmp/meaningless.txt

- grep by character sets (set means that there’s no order in the set)
$ grep -E '[Ii]t' /tmp/meaningless.txt

- use the character set for the full stop
$ grep -E 'no[.]' /tmp/meaningless.txt

- use the character set to not include a character (^ means not include)
$ grep -E 'no[^ ]' /tmp/meaningless.txt

- select all the capitalized letter by character set
$ grep -E '[A-Z]' /tmp/meaningless.txt

- the star * means to repeat the character in the front for 0 to finite times
$ grep -E 'es*' /tmp/meaningless.txt

- the plus + means to repeat the character in the front for 1 to finite times
$ grep -E 'es+' /tmp/meaningless.txt

- the question mark ? means the character in the front it appears for 0 or 1 times
$ grep -E '[T]?he' /tmp/meaningless.txt

- {} is used to given the times of repeating. The first value means the minimum value of repeating and the second value means the maximum value of repeating. For example, the following code will output the same result as a question mark.
$ grep -E '[T]{0,1}he' /tmp/meaningless.txt- () can be used to combine letters in a character set
Based on what we have learned, this will give as the content including ‘ao’, ‘bo’, ‘co’, and ‘do’
$ grep -E '[abcd]o' /tmp/meaningless.txt

What can we do if we also want to include ‘abo’? The answer is to use the ().
$ grep -E '(a|b|c|d|ab)o' /tmp/meaningless.txt

- Escaping Characters
A backslash \ is used in regular expressions to escape the next character. This allows us to include reserved characters such as { } [ ] / \ + * . $ ^ | ? as matching characters. There are also many shorthand characters we have to remember
┌─────────┬────────────────────────────────────────────────┐
│ Char │ Meaning │
├─────────┼────────────────────────────────────────────────┤
│ \{ │ { │
├─────────┼────────────────────────────────────────────────┤
│ \} │ } │
├─────────┼────────────────────────────────────────────────┤
│ \[ │ [ │
├─────────┼────────────────────────────────────────────────┤
│ \] │ ] │
├─────────┼────────────────────────────────────────────────┤
│ \/ │ / │
├─────────┼────────────────────────────────────────────────┤
│ \\ │ \ │
├─────────┼────────────────────────────────────────────────┤
│ \+ │ + │
├─────────┼────────────────────────────────────────────────┤
│ \* │ * │
├─────────┼────────────────────────────────────────────────┤
│ \. │ . │
├─────────┼────────────────────────────────────────────────┤
│ \$ │ $ │
├─────────┼────────────────────────────────────────────────┤
│ \^ │ ^ │
├─────────┼────────────────────────────────────────────────┤
│ \| │ | │
├─────────┼────────────────────────────────────────────────┤
│ \? │ ? │
├─────────┼────────────────────────────────────────────────┤
│ \w │ [a-zA-Z0-9] │
├─────────┼────────────────────────────────────────────────┤
│ \W │ [^\w] │
├─────────┼────────────────────────────────────────────────┤
│ \d │ [0-9] │
├─────────┼────────────────────────────────────────────────┤
│ \D │ [^\d] │
├─────────┼────────────────────────────────────────────────┤
│ \f │ form feed │
├─────────┼────────────────────────────────────────────────┤
│ \n │ new line │
├─────────┼────────────────────────────────────────────────┤
│ \r │ carriage return │
├─────────┼────────────────────────────────────────────────┤
│ \t │ Tab │
├─────────┼────────────────────────────────────────────────┤
│ \v │ Vertical Tab │
├─────────┼────────────────────────────────────────────────┤
│ \p │ \r\n │
├─────────┼────────────────────────────────────────────────┤
│ \s │ [\t\n\f\r\p{Z}] │
├─────────┼────────────────────────────────────────────────┤
│ \S │ [^\s] │
└─────────┴────────────────────────────────────────────────┘
For example,
$ grep -E '(\.\s)' /tmp/meaningless.txt

- check whether the text begins with ‘Cul’
$ grep -E '^(Cul)' /tmp/meaningless.txt

- check whether the text ends with ‘h…’
$ grep -E '(h...)$' /tmp/meaningless.txt

- Lookaround Operations
To use the lookaround operations (+/-lookahead and +/-lookbehind) we have to install ggrep first because grep doesn’t support this feature. So that we have to install GNU grep onto our macOS computer.
$ brew install grep
In order to use this GNU grep, we have to add a g to grep before we use this command and the option of the regular expression is -P.
$ ggrep -P <Regex> <path/filename>
- grab all the ‘no.’ followed by a word begin with ‘h’ (positive lookahead with ?=)
$ ggrep -P 'no.(?=\sh)' /tmp/meaningless.txt

- grab all the ‘no.’ followed by a word not begin with ‘h’ (negative lookahead with ?!)
$ ggrep -P 'no.(?!\sh)' /tmp/meaningless.txt

- grab all the ‘h’ followed by a word with the form of ‘no.’ (positive lookbehind with ?<=)
$ ggrep -P '(?<=no.)\sh' /tmp/meaningless.txt

- grab all the ‘h’ followed by a word not with the form of ‘no.’ (positive lookbehind with ?<!)
$ ggrep -P '(?<!no.)\sh' /tmp/meaningless.txt

3. Flags
Because the full name of grep is called the globally search for a regular expression and print matching lines, thus it is by default with a global search flag (actually it is by default /…/gm). However, we are still going to introduce this part because it can be somehow useful.
In this part, we can actually try the flags on regex101, which is a fantastic website that will explain to you everything of the regular expression.
- Case Insensitive: this means that all the results are not case sensitive
/.../i
- Global Search: this means to show all the result instead of just the first matching term
/.../g
- Multiple Lines: this means to show all the result instead of just the first line
/.../m
Note that we can use different flags together.
4. Funny Practice
Look back to the first image, so what’s the meaning of the following regex on,
/(?!SALT)\b\S+/
We don’t know anything about the \b character and it is actually giving us the boundary of the words. For example, if we try \b, we can then have all the boundaries under the global searching flag,
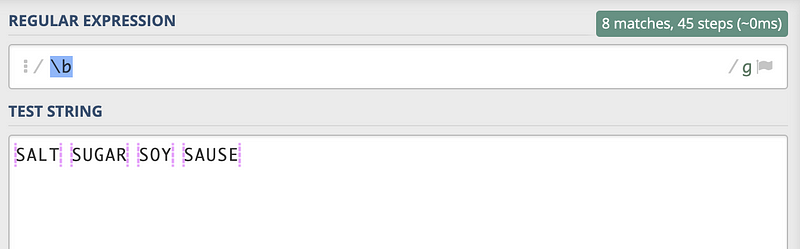
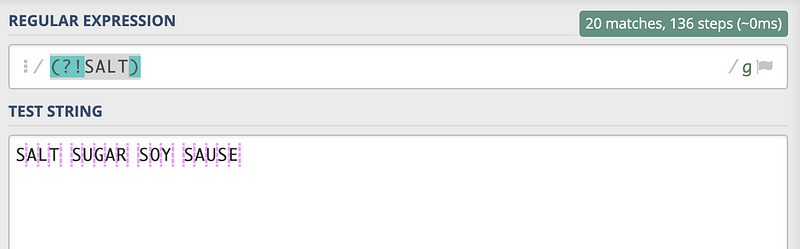
With global, (?!SALT) actually gives us all the character boundaries except for the first one, because the first boundary is followed by SALT and it is not preferred because of the ?! sign.
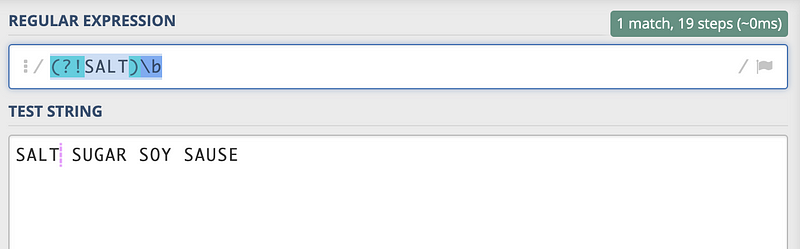
thus, without the global flag, (?!SALT)\b gives us the first boundary after SALT. And it can be thought that we only have to look at the characters after this boundary.
So, what we are now going to have is \S means to ignore the space and select the first letter after, where + means to select the other letters behind the \S. In conclusion, we are going to select SUGAR in this case.
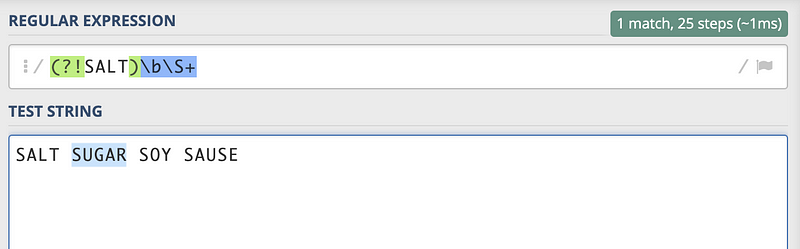
So that because the monkey chooses SALT and get confused about that, we are quite sure that it doesn’t know anything about the regular expression!