Relational Database 4 | JOIN Operation, Conditional Expressions, Nested Queries, and Aggregate…
Relational Database 4 | JOIN Operation, Conditional Expressions, Nested Queries, and Aggregate Operators

- JOIN Operation
(0) Basic Setup
Suppose we have two following tables,
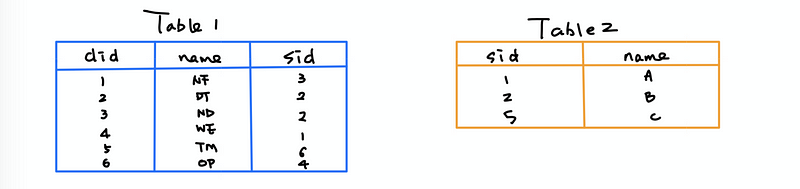
(1) CROSS JOIN
Returns a cartesian product between two sets of data.
SELECT *
FROM <table1>
CROSS JOIN <table2>;
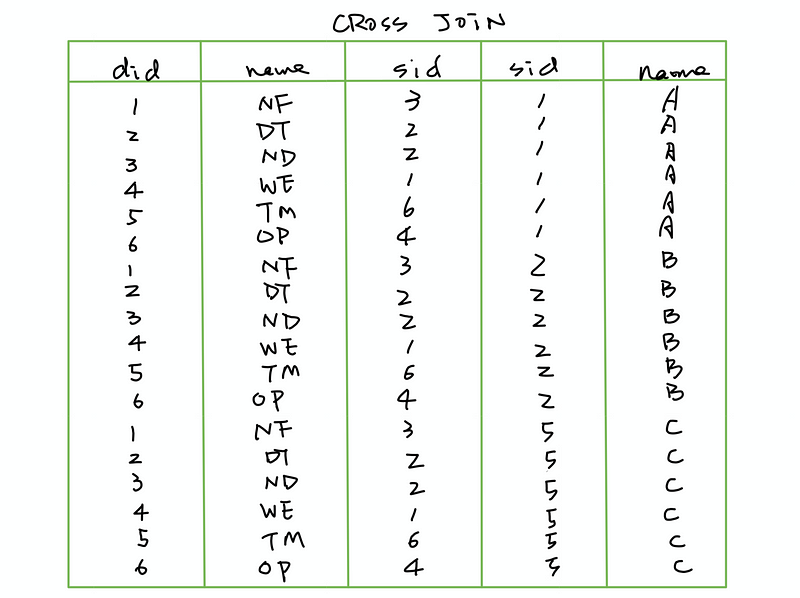
(2) INNER JOIN
Returns rows appearing in both tables.
SELECT *
FROM <table1>
INNER JOIN <table2>
ON <table1>.<colname1>=<table2>.<colname2>;
With table1.sid = table2.sid,
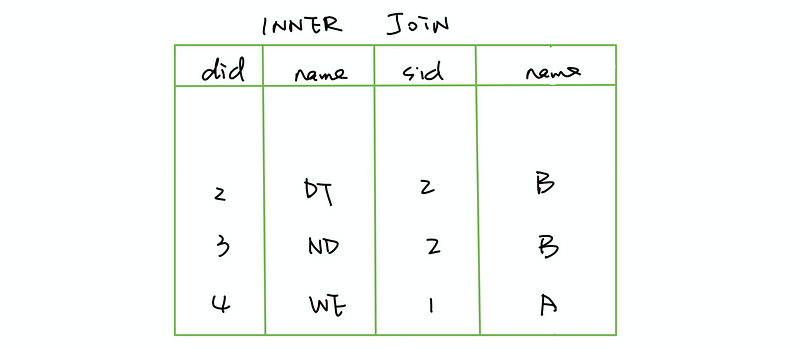
(3) LEFT JOIN
Return all rows from the left table, and the matched rows from the right table.
SELECT *
FROM <table1>
LEFT JOIN <table2>
ON <table1>.<colname1>=<table2>.<colname2>;
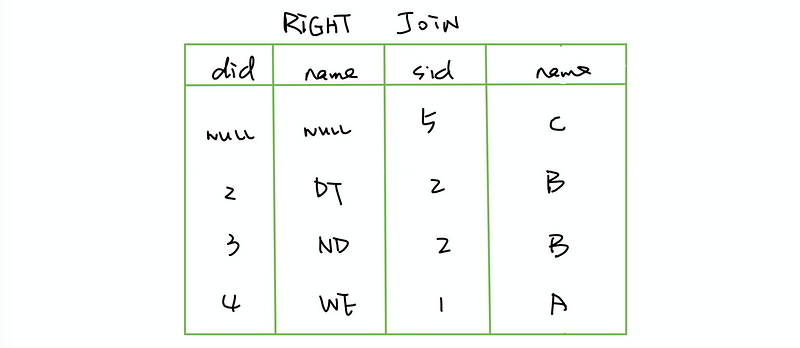
(4) RIGHT JOIN
Return all rows from the right table, and the matched rows from the left table.
SELECT *
FROM <table1>
RIGHT JOIN <table2>
ON <table1>.<colname1>=<table2>.<colname2>;
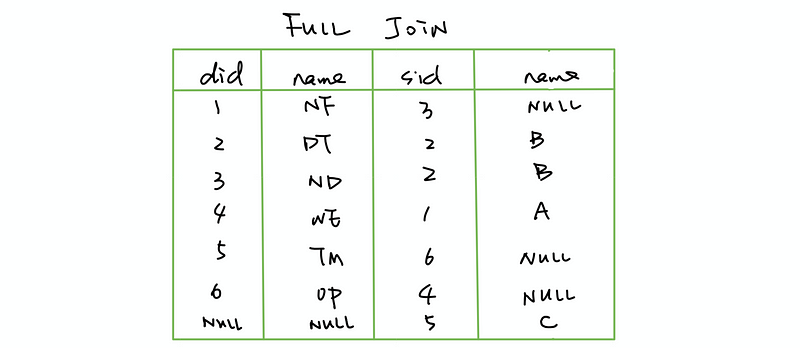
(5) FULL JOIN
Return all rows appearing in any of the tables.
SELECT *
FROM <table1>
FULL JOIN <table2>
ON <table1>.<colname1>=<table2>.<colname2>;
2. Conditional Expressions
(1) Basic Syntax
CASE WHEN <condition1> THEN <result1>
WHEN <condition2> THEN <result2>
...
ELSE <result>
END
(2) Useful Functions
- Return the first not NULL value, else return NULL
COALESCE(<colname1>, <colname2>, ...)
- Return the NULL if value1 = value2, else return 1
NULLIF(<colname1>, <colname2>)
- Return the largest value (Ignore NULL value)
GREATEST(<colname1>, <colname2>, ...)
- Return the smallest value (Ignore NULL value)
LEAST(<colname1>, <colname2>, ...)
3. Nested Queries
(1) Create a Subquery
The syntax of a subquery is,
SELECT *
FROM (SELECT *
FROM <table>
WHERE <balabala>
) AS <new_tablename>
WHERE <balabala>;
(2) Subquery Expressions
- EXISTS: check rows, if returns at least one row, then true
SELECT *
FROM <table>
WHERE EXISTS (SELECT *
FROM <table1>
WHERE <balabala>
);
- IN: check columns, if returns at least one row, then true
SELECT *
FROM <table>
WHERE <colname>
IN (SELECT <colname>
FROM <table1>
WHERE <balabala>
);
- ANY: check any conditions, if returns at least one row, then true
SELECT *
FROM <table>
WHERE <colname> <=
ANY (SELECT <colname>
FROM <table1>
WHERE <balabala>
);
- ALL: check all conditions, if the condition holds for all rows, then true
SELECT *
FROM <table>
WHERE <colname> <=
ALL (SELECT <colname>
FROM <table1>
WHERE <balabala>
);
- EXCEPT: reduce some items in another table
SELECT *
FROM <table>
EXCEPT
SELECT *
FROM <table1>
WHERE <balabala>;
4. Aggregate Operators
- GROUP BY: group by a certain column with a math operation (AVG / MIN / MAX / ABS / etc.)
GROUP BY <colname>
- HAVING: gives the condition of a group
For example, to make a group larger than 2 items,
HAVING COUNT(*) >= 2
Here’s an example of why HAVING is good syntax. For Leetcode #569, the question is:
There is a table courses with columns: student and class. Please list out all classes which have more than or equal to 5 students. For example, the table:
+---------+------------+
| student | class |
+---------+------------+
| A | Math |
| B | English |
| C | Math |
| D | Biology |
| E | Math |
| F | Computer |
| G | Math |
| H | Math |
| I | Math |
+---------+------------+
Should output:
+---------+
| class |
+---------+
| Math |
+---------+
Note:
The students should not be counted duplicate in each course.
If we are not using HAVING, we are going to write the following code,
SELECT class
FROM
(
SELECT class, COUNT(DISTINCT student) AS num
FROM courses
GROUP BY class
) AS studentsnumber
WHERE num >= 5;
If we use HAVING for our code, then,
SELECT class
FROM courses
GROUP BY class
HAVING COUNT(DISTINCT student) >= 5;