Relational Database 10 | Database Transaction
Relational Database 10 | Database Transaction

- Database Transaction
(1) The Definition of Database Transaction
A transaction is a sequence of operations performed (using one or more SQL statements) on a database as a single logical unit of work. One operation can be treated as a transaction (single-operation transaction) and several operations can also be a transaction (transaction block).
(2) Recall: Autocommit mode
The auto-commit mode is the default mode for PostgreSQL and each statement is executed in its own transaction and a commit is implicitly performed at the end of the statement. If the execution was successful then there will be a commit automatically, otherwise, a rollback is done.
For example, if we run,
UPDATE datatable SET value = 2 WHERE id = 1;
This is equivalent to,
BEGIN;
UPDATE datatable SET value = 2 WHERE id = 1;
COMMIT;
We are going to explain more about this block in the following section.
(3) BEGIN, COMMIT, and ROLLBACK
BEGIN initiates a transaction block, that is, all statements after a BEGIN command will be executed in a single transaction until an explicit COMMIT or ROLLBACK is given.
COMMIT means to save the change of the database after executing the transaction, while ROLLBACK means to abandon the transaction after the BEGIN statement and ignore the changes on the database. Note that if an error occurs when running a transaction, then a COMMIT will then become a ROLLBACK (because the error should not be committed).
2. ACID Property of the Transaction
(1) Atomicity
a. The Definition of Atomicity
Atomicity means either all the operations (insert, update, delete) inside a transaction take place or none. Or we can say, all the statements (insert, update, delete) inside a transaction are either completed or rolled back.
b. Example of the Atomicity
Suppose we have the following operations,
DROP VIEW IF EXISTS test1, test2;
BEGIN;
CREATE VIEW test1 AS (SELECT 1);
CREATE VIEW test2 AS (SELECT 1);
ROLLBACK;
SELECT * FROM test1, test2;
Then, for the transaction block of this code, the final results are rollbacked. This means that non of the operations inside this transaction would take place. Then we get an error because no view is created.
Things will be different if we change the ROLLBACK to COMMIT. See what happens for the following transactions.
DROP VIEW IF EXISTS test1, test2;
BEGIN;
CREATE VIEW test1 AS (SELECT 1);
CREATE VIEW test2 AS (SELECT 1);
COMMIT;
SELECT * FROM test1, test2;
We will have an output because these two views are successfully created.
(2) Consistency
a. The Definition of Consistency
Consistency means, whatever happens in the middle of the transaction, this acid property will never leave your database in a half-completed state.
- If the transaction completed successfully, then it will apply all the changes to the database.
- If there is an error in a transaction, then all the changes that already made will be rolled back automatically. It means the database will restore to its state that it had before the transaction started.
- If there is a system failure in the middle of the transaction, then also, all the changes made already will automatically rollback.
b. Example of the Consistency
If we change the place of the final operation to the middle of the transactions, then,
DROP VIEW IF EXISTS test1, test2;
BEGIN;
CREATE VIEW test1 AS (SELECT 1);
SELECT * FROM test1, test2;
CREATE VIEW test2 AS (SELECT 1);
COMMIT;
Of course, there will be an error if we execute the code. Because the test2 VIEW is called because we define it.
ERROR: relation "test2" does not exist
LINE 5: SELECT * FROM test1, test2;
Because the transaction is now suspended, we can not move on to execute other codes after this, or there will be an error of aborted transaction,
ERROR: current transaction is aborted, commands ignored until end of transaction block
Before we continue, we have to do either COMMIT or ROLLBACK for this transaction because they all mean ROLLBACK in this part. Let’s try a COMMIT now, then we can find out the code actually executes a ROLLBACK command.
ROLLBACK
(3) Isolation
a. The Definition of Isolation
Every transaction is individual, and one transaction can’t access the result of other transactions until the transaction completed.
b. Interleaved Transaction
When the transactions are interleaved, it means the second transaction is started before the first one could end. And execution can switch between the transactions back and forth. It can also switch between multiple transactions.
Interleaving transactions allows multiple users of the database to access it at the same time. When there are multiple transactions, actions (reading, writing, aborting, or committing) in transactions could be interleaved to improve the performance.
e. The Definition of the Transaction Schedule
The transaction schedule describes a list of actions from a set of transactions as seen by the DBMS. There are two kinds of transaction schedules.
The first one is the serial schedule, which means if the actions of different transactions are not interleaved are executed from start to finish. The second one is the serializable schedule which describes that the actions of different transactions are interleaved. The following diagrams of the transaction schedule show a comparison between those two kinds of schedules.
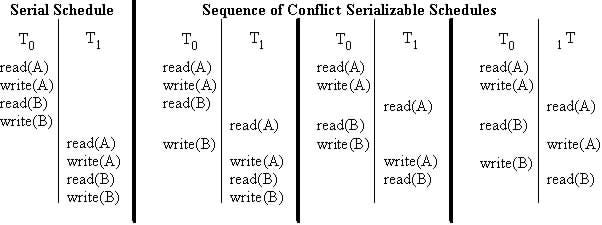
d. Example of the Isolation
Let’s first of all, create a new table by,
DROP TABLE IF EXISTS population CASCADE;
CREATE TABLE population
(
state_id integer,
year integer,
population integer
);
INSERT INTO population VALUES
(1, 2010, 37000000),
(2, 2010, 25000000),
(3, 2010, 18000000),
(4, 2010, 19000000),
(5, 2010, 12000000),
(1, 2019, 39000000),
(2, 2019, 38000000),
(3, 2019, 21000000),
(4, 2019, 19000000),
(5, 2019, 12000000);
Then open two separate query tools for the same database. We can then start two transactions in these two query tools respectively. The first number means the sequence of running the operations, the second number in the parentheses means the output of this operation.
Then, in the first query tool,
BEGIN; — 1
SELECT COUNT(*) FROM population WHERE year = 2010; — 3 (5)
SELECT COUNT(*) FROM population WHERE year = 2010; — 6 (5)
SELECT COUNT(*) FROM population WHERE year = 2010; — 8 (4)
UPDATE population SET year = 2010 WHERE population = 37000000; — 9
SELECT COUNT(*) FROM population WHERE year = 2010; — 10 (5)
COMMIT; — 11
In the second query tool,
BEGIN; -- 2
UPDATE population SET year = 2016 WHERE population = 37000000; -- 4
SELECT COUNT(*) FROM population WHERE year = 2010; -- 5 (4)
COMMIT; -- 7
We can find out that the first transaction won’t access the result of the UPDATE (#6) until the transaction in the second query tool is committed (#8).
e. The Definition of Concurrency
Although there is never more than one current SQL transaction between your DBMS and your application program at any point in time, the operational problem is that many DBMSs run in multi-tasking or multi-user scenarios (especially possible if we are using AWS RDS), and this will result in collisions of the operations.
f. Concurrency Transactions vs. Interleaved Transactions
The interleaved transactions is executed by one user or a signal task so that one transaction can’t access the result of other transactions until the transaction completed. However, for concurrency transactions, one transaction can access the result of other transactions before the transaction completed.
g. The Definition of Collisions
The running together of two transactions, which may access the same database rows during overlapping time periods. Such simultaneous accesses, called collisions, may result in errors or inconsistencies if not handled properly. The more overlapping that is possible, the greater the concurrency.
There are basically four types of categories, which they call — in order by seriousness — Lost Update, Dirty Read, Non-Repeatable Read, and Phantom Read.
h. Lost Update (Most serious)
Let’s see the following schedule,
-----------------------------------
Txn #1 Txn #2
-----------------------------------
Change ...
... Change
Read ...
Commit ...
... Commit
Transaction #1 (Txn #1) updates the database and then transaction #2 (Txn #2) also updates the database right after it. So the updates for Txn #2 supersedes the updates of Txn #1. If Txn #1 then read from the database, it will not get the result of the change in Txn #1.
i. Dirty Read (Highly serious)
Let’s see the following schedule,
-----------------------------------
Txn #1 Txn #2
-----------------------------------
Change ...
... Read
Rollback ...
... Commit
Transaction #1 (Txn #1) updates the database and then transaction #2 (Txn #2) reads from it. It will get the data after the changes of transaction #1. However, transaction #1 then rollback the changes and that means the changes never really work on the database. Sadly, Txn #2 read the dirty data that may be wrong in someplace.The old name for the Dirty Read phenomenon is “uncommitted dependency”.
j. Non-Repeatable Read (Not so serious)
Let’s see the following schedule,
-----------------------------------
Txn #1 Txn #2
-----------------------------------
Read ...
... Change
Read ...
... Commit
Commit ...
The non-repeatable read is the inconsistent results of two reads. It is not so serious because we can detect it from two different results in the sequence. Txn #1 reads from the database and then Txn #2 updates the data right after it. Then Txn #1 conduct a second read and find there’s something different in the result compared with the last read. This is not so serious, but it does certainly break the requirements of an ACID transaction.
k. Phantom Read (Rare and Tolerable)
Let’s see the following schedule,
----------------------------------------
Txn #1 Txn #2
----------------------------------------
Search ...
... Insert/Delete
Search ...
... Commit
Commit ...
This is also called the “now-you-don’t-see-it-now-you-do” phenomenon. This happens only if there are two searches in one transaction and these searches depend on the updated terms in another transaction. It is kind of rare and the results can always be tolerable. This will be fine because it’s like “Oh I can’t find this. I have to refresh it. Aha, now it’s here.”.
l. The Definition of the Lock
The most common and best-known way to eliminate some or all of the transaction concurrency phenomena is locking. A lock is an object that ensures the net effect is identical to executing all transactions in a serial order to minimize collisions. We can lock either a table or a bunch of rows in a table. A lock is much like a reservation in a restaurant. If you find that your desired seat has already been taken by someone who came before you, you must either wait or go elsewhere.
There are two kinds of locks, the shared lock, and the exclusive lock. A shared lock exists because there is nothing wrong with letting two transactions read the same row; concurrency can only cause trouble if one transaction or the other is updating. The shared lock does not prevent the other transactions from reading the same row. However, when there’s a change (update/insert/ etc.) happens, the shared lock is upgraded to an exclusive lock, which blocks both reads and writes by other transactions. The exclusive lock will degrade the performance of the code because it has to wait and this adds to the time complexity.
A typical shared locking process is,
--------------------------------------------------------
Txn #1 Txn #2
--------------------------------------------------------
shared lock row #1 ...
... read row #1
read row #1 ...
... Attempt to Update row #1
- Wait because locked
Commit ...
... Update row #1
... Commit
m. Locking Problem
There are several problems with the lock for SQL,
- Performance Degradation
To resolve the collisions between the transactions, the lock uses blocking (holds locks and force the other transactions to wait) and aborting (stops and restart the transaction). This can be a problem if there are many transactions that happens at the same time. The time cost of executing a transaction can be unpredictable.
There are three solutions to this. Firstly, only lock the smallest side objects. Secondly, reducing the time that transactions hold locks. Thirdly, reducing the hotspots (objects that are frequently accessed or modified).
- DeadLock Problem
The deadlock (or deadly embrace) problem happens if there are two transactions waiting for each other. Because all of them are waiting, then there’s no way either of them can be executed. The deadlock problem goes like this,
-------------------------------------------------------------
Txn #1 Txn #2
-------------------------------------------------------------
shared lock row #1 ...
... shared lock row #2
... Attempt to Update row #1
- Wait because locked
Attempt to Update row #2 ...
- Wait because locked
Wait Wait
- Shared Lock Profusion
Let’s think about this, most commonly, what we will update for a table are usually a relatively small number of rows. However, the easiest way to set a shared lock is to set a lock for the whole table. Because most of the database guys are lazy and they don’t want to do lock to every specific row. Then this will result in a profusion of the shared locks. (i.e. people always choose SERIALIZABLE because they are lazy, we will explain this in the following section)
n. Lock for PostgreSQL
To set a lock for the PostgreSQL, we have to declare the isolation level in the BEGIN statement. The isolation level can be chosen from SERIALIZABLE, REPEATABLE READ, READ COMMITTED, READ UNCOMMITTED.
BEGIN TRANSACTION ISOLATION LEVEL <isolevel>;
- SERIALIZABLE: the safest lock, which will lock everything related to the transaction. This can cause the lock profusion problem and the performance can be bad.
- REPEATABLE READ: the shared lock. The data related to the transaction can only be read or write after the transaction is committed (or the lock is terminated). REPEATABLE READ is a level in addition to the guarantees of the READ COMMITTED level (not vice versa), it also guarantees that any data read cannot change, if the transaction reads the same data again, it will find the previously read data in place, unchanged, and available to read.
- READ COMMITTED: (default) the shared lock. The data related to the transaction can only be read or write after the transaction is committed (or the lock is terminated). It simply restricts the reader from seeing any intermediate, uncommitted, ‘dirty’ read. However, data is free to change after it was read.
- READ UNCOMMITTED: No lock.

Note that in PostgreSQL, the READ UNCOMMITTED is treated as the READ COMMITTED and phantom reads are not possible in the PostgreSQL implementation of Repeatable Read, so the actual isolation level might be stricter than what you select.
Also note that PostgreSQL doesn’t support the dirty read so that no lock will also, not cause a dirty read problem.
(4) Durability
a. The Definition of Durability
Once the transaction completed, then the changes it has made to the database will be permanent. Even if there is a system failure or any abnormal changes.
b. Write-Ahead Logging Files for Durability
Write-Ahead Logging (WAL) is a standard method for ensuring data integrity. And they are the way that PostgreSQL reaches the property of durability. To find the WAL files, we can run the following code,
$ cd /usr/local/var/postgres/pg_wal/
$ cat `ls | head -1` | head -1