Relational Database Review 12 | Final Review
Relational Database Review 12 | Final Review

- GROUP BY & HAVING & Window Functions
(1) Question 1 [Link]
We would like to find the total weight of cats grouped by age. But only return those groups with a total weight larger than 12.
Wrong, because total_weight is not defined as the column from table cats.
SELECT age, SUM(weight) AS total_weight
FROM cats
GROUP BY age
HAVING total_weight > 12
ORDER BY age;
Right answer,
SELECT age, SUM(weight) AS total_weight
FROM cats
GROUP BY age
HAVING SUM(weight) > 12
ORDER BY age;
(2) Question 2. [Link]
The cats must be ordered by name and will enter an elevator one by one. We would like to know what the running total weight is.
Wrong, because the result is not an elevator one by one,
SELECT name, SUM(weight) AS running_total_weight
FROM cats
GROUP BY name
ORDER BY name;
Right answer,
SELECT name,
SUM(weight) OVER (ORDER BY name) AS running_total_weight
FROM cats;
(3) Question 3. [Link]
The cats must be ordered first by breed and second by name. They are about to enter an elevator one by one. When all the cats of the same breed have entered they leave.
We would like to know what the running total weight of the cats is.
Wrong. The result is elevated, but is not grouped by the breed,
SELECT name, breed,
SUM(weight) OVER (ORDER BY breed, name) AS running_total_weight
FROM cats;
Right answer,
SELECT name, breed,
SUM(weight) OVER (PARTITION BY breed ORDER BY breed, name) AS running_total_weight
FROM cats;
(4) Question 4. [Link]
The cats would like to see the average of the weight of them, the cat just after them and the cat just before them. The first and last cats are content to have an average weight consisting of 2 cats, not 3.
Wrong, the following SQL doesn't order by weight,
SELECT name, weight,
AVG(weight) OVER (ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
FROM cats;
Right answer,
SELECT name, weight,
AVG(weight) OVER (ORDER BY weight ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
FROM cats;
(5) Question 5. [Link]
The cats must be ordered by weight descending and will enter an elevator one by one. We would like to know what the running total weight is. If two cats have the same weight they must enter separately.
Wrong, this is because the first row and the second row have the same value and thus they are evaluated to the same thing,
SELECT name,
SUM(weight) OVER (ORDER BY weight DESC) AS running_total_weight
FROM cats;
Right answer,
SELECT name,
SUM(weight) OVER (ORDER BY weight DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS running_total_weight
FROM cats;
(6) Question 6. [Link]
Show each breed with the average age of the dogs of that breed. Do not show breeds where the average age is lower than 5.
SELECT breed, AVG(age)
FROM dog
GROUP BY breed
HAVING AVG(age) >= 5;
(7) Question 7. [Link]
For each employee, find their first name, last name, salary, and the sum of all salaries in the company. Note that the last column is an aggregated column, even though you’re not using a GROUP BY.
Wrong, we are not asking to accumulate in the last column, just show the aggregated number without GROUP BY,
SELECT first_name, last_name, salary,
SUM(salary) OVER (ORDER BY salary)
FROM employee;
Right answer,
SELECT first_name, last_name, salary,
SUM(salary) OVER ()
FROM employee;
(8) Question 8. [Link]
For each item in the purchase table, select its name (column item), price and the average price of all items.
SELECT item, price, AVG(price) OVER ()
FROM purchase;
(9) Question 9. [Link]
For each employee in table employee, select first and last name, years_worked, an average of years spent in the company by all employees, and the difference between the years_worked and the average as difference.
SELECT first_name, last_name, years_worked,
AVG(years_worked) OVER (),
years_worked - AVG(years_worked) OVER () AS difference
FROM employee
(10) Question 10. [link]
For each employee that earns more than 4000, show their first_name, last_name, salary and the number of all employees who earn more than 4000.
SELECT first_name, last_name, salary,
COUNT(*) OVER ()
FROM employee
WHERE salary > 4000;
(11) Question 11 (slightly modified). [link]
Show the first_name, last_name and salary of every person who works in departments with id 1, 2, or 3, along with the average salary calculated in each of those three departments.
SELECT first_name, last_name, salary, AVG(salary) OVER (PARTITION BY department.id)
FROM employee
LEFT JOIN department
ON employee.department_id = department.id
WHERE department.id = 1
OR department.id = 2
OR department.id = 3;
(12) Question 12. [link]
You cannot put window functions in WHERE. Why? The window functions are applied after the rows are selected. If the window functions were in a WHERE clause, you'd get a circular dependency: in order to compute the window function, you have to filter the rows with WHERE, which requires to compute the window function. For example, it can’t be,
SELECT first_name, last_name, salary,
AVG(salary) OVER()
FROM employee
WHERE salary > AVG(salary) OVER ();
2. JSON & User-defined Functions & Views & CTE
(1) Answer the following questions.
- Fill in the blank: Suppose we have the following data as the first row in the table nytimes, then what will be blank if we want to query the text typed oid?
Query:
SELECT data __________ FROM nytimes;
data:
{"_id":{"$oid":"5b4aa4ead3089013507db18b"},
"bestsellers_date":
{"$date":{"$numberLong":"1211587200000"}},
"published_date":
{"$date":{"$numberLong":"1212883200000"}},
"amazon_product_url":"http://www.amazon.com/Odd-Hours-Dean-Koontz/dp/0553807056?tag=NYTBS-20",
"author":"Dean R Koontz",
"description":"Odd Thomas, who can communicate with the dead, confronts evil forces in a California coastal town.",
"price":{"$numberInt":"27"},
"publisher":"Bantam",
"title":"ODD HOURS",
"rank":{"$numberInt":"1"},
"rank_last_week":{"$numberInt":"0"},
"weeks_on_list":{"$numberInt":"1"}}Ans:
-> '_id' ->> '$oid'
- Fill in the blank: Suppose we have the following data as the first row in the table nytimes, then what will be blank if we want to query the JSON typed oid?
Query:
SELECT data __________ FROM nytimes;
data:
{"_id":{"$oid":"5b4aa4ead3089013507db18b"},
"bestsellers_date":
{"$date":{"$numberLong":"1211587200000"}},
"published_date":
{"$date":{"$numberLong":"1212883200000"}},
"amazon_product_url":"http://www.amazon.com/Odd-Hours-Dean-Koontz/dp/0553807056?tag=NYTBS-20",
"author":"Dean R Koontz",
"description":"Odd Thomas, who can communicate with the dead, confronts evil forces in a California coastal town.",
"price":{"$numberInt":"27"},
"publisher":"Bantam",
"title":"ODD HOURS",
"rank":{"$numberInt":"1"},
"rank_last_week":{"$numberInt":"0"},
"weeks_on_list":{"$numberInt":"1"}}Ans:
-> '_id' -> '$oid'
- Fill in the blank: If we want to check the data type of the data column in the relation nytimes, what function can we write in the blank?
Query:
SELECT __________(data) FROM nytimes;
Ans:
pg_typeof
- Fill in the blank: Suppose we want to change the text typed column to the JSON type, what function can we use to fill in the blank?
Query:
WITH tmp AS (SELECT 'something' AS txt)
SELECT _________(txt) AS js FROM tmp;
Ans:
TO_JSON
- Fill in the blank: Suppose we want to change a table of values to a JSON table, then what function can we use to fill in the blank?
Query:
SELECT ________(tablename) FROM tablename;
Ans:
TO_JSON
(2) T/F Questions
- You can query a view.
Ans: True
- The view is a table stored in the disk.
Ans: False
- The view is a table stored in the memory.
Ans: False
- The view is a table stored in the schema.
Ans: False
- The view is an operation stored in the schema (disk).
Ans: True
- If you update data in a view, the corresponding rows in the base table that the view is referencing are also updated.
Ans: True. We can test the following query,
CREATE TABLE hi (
id INTEGER,
name TEXT
);
INSERT INTO hi VALUES (1, 'Adam');
INSERT INTO hi VALUES (2, 'Echo');
SELECT * FROM hi;
CREATE VIEW hi_view AS (
SELECT * FROM hi
);
SELECT * FROM hi_view;
UPDATE hi_view SET id = 3 WHERE name = 'Echo';
SELECT * FROM hi_view;
SELECT * FROM hi;
- If you update data in a base table, the corresponding rows in the view that is referencing this table are also updated.
Ans: True. We can test the following query (follows the last query),
CREATE OR REPLACE VIEW hi_view AS (
SELECT * FROM hi
);
SELECT * FROM hi_view;
UPDATE hi SET id = 4 WHERE name = 'Echo';
SELECT * FROM hi_view;
SELECT * FROM hi;
- A temporary table (created from a CTE) can be referenced in different queries.
Ans: False.
- The full name of the CTE is Consistency Table Expression.
Ans: False. It is called the common table expression.
- Json is commonly used for browser-server communication for REST APIs.
Ans: True.
- Postgres automatically validates the JSON format.
Ans: True.
(3) Coding Question
Use the following query to create a table named cats,
DROP TABLE IF EXISTS cats;
CREATE TABLE cats (
name TEXT,
age INTEGER,
breed TEXT,
owner_id INTEGER
);
INSERT INTO cats (name, age, breed, owner_id) VALUES ('Maru', 3 , 'Scottish Fold', 1);
INSERT INTO cats (name, age, breed, owner_id) VALUES ('Hana', 1 , 'Tabby', 1);
INSERT INTO cats (name, age, breed) VALUES ('Lily Bub', 5, 'American Shorthair');
INSERT INTO cats (name, age, breed) VALUES ('Moe', 10, 'Tabby');
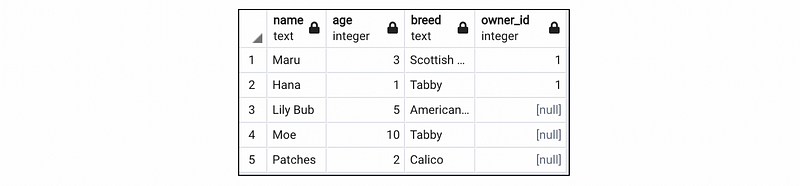
INSERT INTO cats (name, age, breed) VALUES ('Patches', 2, 'Calico');SELECT * FROM cats;
- Create a function owner when given a cat’s name, it will return the owner id for us. Test Hana and Moe for our result.
CREATE OR REPLACE FUNCTION owner (input_name TEXT)
RETURNS INTEGER AS
$$
SELECT owner_id
FROM cats
WHERE name = input_name
$$
LANGUAGE SQL;
SELECT owner('Hana'), owner('Moe');- Create a function that returns the table of information with a cat when there’s an owner of it. Test this function.
CREATE OR REPLACE FUNCTION with_owner ()
RETURNS TABLE (name TEXT, age INTEGER, breed TEXT, owner_id INTEGER) AS
$$
SELECT *
FROM cats
WHERE owner_id IS NOT NULL
$$
LANGUAGE SQL;
SELECT * FROM with_owner() AS tmp;
- Create a function that deletes the records of cats when there’s no owner of them. Test this function.
CREATE OR REPLACE FUNCTION delete_owner ()
RETURNS VOID AS
$$
DELETE FROM cats
WHERE owner_id IS NULL
$$
LANGUAGE SQL;
SELECT delete_owner();
SELECT * FROM cats;
3. Database Transactions
(1) Answer the following questions
- What are the ACID properties of the transaction?
Ans: Atomicity, Consistency, Isolation, Durability
- What are the 4 isolation levels?
Ans: Serializable, Repeatable Read, Read Committed, Read Uncommitted
- Which isolation level is the safest/most isolated?
Ans: serializable
- Which isolation schedule allows interleaved transactions?
Ans: serializable schedule
- How is durability preserved in a database?
Ans: WAL — Write-Ahead Logging. This means that the steps taken to make modifications to a database are logged first before they are actually committed. This way, if the DB crashes, we’ll still have the log with the instructions of what to do.
- What is the throughput?
Ans: Transactions per second.
- What’s the anomaly with the following transactions? (w = write, r = read, c = commit, ro = rollback, d = delete, s = search)
Schedule: w1(A)w2(A)r2(A)c2r1(A)c1
Ans: Lost update problem
- What’s the anomaly with the following transactions?
Schedule: r1(X)r2(X)w1(X)r2(X)c1
Ans: Unrepeatable/Nonrepeatable read problem
- What’s the anomaly with the following transactions?
Schedule: r1(X)s2(X)d1(X)s2(X)c1
Ans: Phantom read problem
- What’s the anomaly with the following transactions?
Schedule: r1(X)w1(X)r2(X)ro1r2(X)c1
Ans: Dirty read problem
- What’s the anomaly with the following transactions?
Schedule: r1(A)w1(A)r2(A)w2(A)r1(B)c2ro1
Ans: Dirty read problem
- Which isolation level will allow the following schedule?
Schedule: r1(A)w1(A)r2(A)w2(A)r1(B)c2ro1
Ans: Read Uncommitted
- Which isolation level will allow the following schedule?
Schedule: r1(A)r2(A)w2(A)r1(A)r2(B)w2(B)c1c2
Ans: Read Committed or Read Uncommitted, because the schedule above has the non-repeatable read problem.
- What will be the schedule if we set the REPEATABLE READ level?
Original Schedule: r1(A)r2(A)w2(A)r1(A)r2(B)w2(B)c1c2
Ans: r1(A)r1(A)c1w2(A)r2(A)r2(B)w2(B)c2, because REPEATABLE READ will make an object read-only after reading until the transaction is ended.
- What will be the problem with the following schedule under the REPEATABLE READ level?
Schedule: r1(A)r2(B)w1(B)w2(A)r1(A)r2(B)c1c2
Ans: Deadlock problem.
- What will be the schedule if we set the REPEATABLE READ level?
Original Schedule: r1(A)w1(A)r2(A)w2(A)r1(A)c1c2
Ans: r1(A)w1(A)r2(A)r1(A)c1w2(A)c2, this is because there’s a lost update problem and REPEATABLE READ will make an object read-only after reading until the transaction is ended.
- How can you avoid getting into the thrashing region?
Ans:
1) lock the smallest possible object (ex. lock rows instead of entire tables)
2) decrease the amount of time a transaction holds a lock
3) reduce hotspots (objects that frequently get locks placed on them)
(2) T/F Questions
- A transaction is said to be a unit of the program’s execution.
Ans: True
- Serializability is the property that a (possibly interleaved) execution of a group of transactions has the same effect on the database and produces the same output as some serial execution of those transactions.
Ans: True
- There can be conflicts in a serial schedule.
Ans: False. Because the serial schedule is not interleaved.
- There’s no dirty read problem in PostgreSQL.
Ans: True. PostgreSQL doesn’t support the dirty read.
- There’s no phantom read problem in PostgreSQL.
Ans: True. PostgreSQL doesn’t support the phantom read.
- In PostgreSQL, the READ UNCOMMITTED level is treated as the READ COMMITTED level
Ans: True.
- In PostgreSQL, the REPEATABLE READ level is treated as the SERIALIZABLE level
Ans: True.
- The time cost of executing a transaction can be predictable.
Ans: False. Because there can be a performance degradation problem.
- The throughput is non-linear to the number of transactions.
Ans: True.
- If you ROLLBACK at the end of a transaction, it goes back to the initial status before it started
Ans: True.
- If you meet an error in the middle of a transaction, then a COMMIT will become a ROLLBACK.
Ans: True.
- Level of READ COMMITTED guarantees repeatable reads.
Ans: False. Or why we will need a REPEATABLE READ level?
- Isolation means that either all commands or none of the commands are executed in one transaction.
Ans: False. This is atomicity.
- Isolation guarantees that once a transaction has committed, its effects remain in the database.
Ans: False. This is durability.
- When there’s a change (update/insert/ etc.) happens, the shared lock is upgraded to an exclusive lock.
Ans: True.
- A shared lock will not prevent reads from the other transactions.
Ans: True.
- A serializable schedule is always more efficient than a serial schedule based on the same transactions.
Ans: True.
- The more transactions you’re running, the higher the throughput.
Ans: False.
- The READ UNCOMMITTED level barely means no locks.
Ans: True
4. Schema Refinement
(1) 1NF
- The table has a primary key
- There are no repeating attributes or lists within a column
(2) 2NF
- It should be in the First Normal form.
- And, it should not have Partial Dependency.
(3) 3NF
- It is in the Second Normal form.
- And, it doesn’t have Transitive Dependency.
(4) T/F Questions
- A relation is in 1NF if it doesn’t contain any functional dependencies.
Ans: False. 1NF should have at least one functional dependency.
- A relation is in 1NF if it doesn’t contain any repeating groups.
Ans: True
- A table is in 2NF if the table is in 1NF and there are no functional dependencies.
Ans: False. A table is in 2NF if the table is in 1NF and there are no partial dependencies.
- In 2NF, there are no attributes that are not functionally dependent on the relation’s primary key.
Ans: True.
- When you normalize a relation by breaking it into two smaller relations, you must a primary key(s) for the new relation.
Ans: True. Because 1NF maintains a primary key for every relation.
- Decomposition can improve performance.
Ans: True.
- It will be costly to join all the subtables if you want to see the original table again.
Ans: True
- If every non-key attribute is only fully functionally dependent on the primary key, then the relation will be in 3NF.
Ans: True.
- If every non-key attribute is fully functionally dependent on the primary key, then the relation will be in 2NF.
Ans: True. Because there can also be transitively dependent.
- Suppose a relation R is in 3NF. Then an FD: X→A is not valid when X is not a proper subset of any key.
Ans: True.
- Redundancy in data may lead to its inconsistency.
Ans: True.
- Inconsistency in data may lead to Redundancy.
Ans: False.
- Normalization is the process of minimizing redundancy and is accomplished through the various normal forms
Ans: True
- The most common problems for data redundancy are redundant storage and update/insert/delete anomalies.
Ans: True.
(5) Coding Questions
Use the following transactions to create a table named author and then answer the following questions,
DROP TABLE IF EXISTS author;
CREATE TABLE author (
id INTEGER,
author VARCHAR(50),
birth_year INTEGER,
two_books VARCHAR[]);
INSERT INTO author VALUES
(1, 'Ernest Hemingway', 1899, '{The Old Man and the Sea, A Farewell to Arms}'),
(2, 'Mark Twain', 1835,'{Adventures of Huckleberry Finn, The Adventures of Tom Sawyer}'),
(3, 'Virginia Woolf',1882 ,'{Mrs Dalloway, A Room of One''s Own}'),
(4, 'Jane Austen', 1775, '{Pride and Prejudice, Sense and Sensibility}');
SELECT * FROM author;
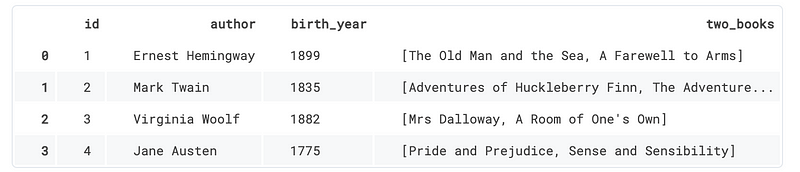
- How to change this relation to 1NF?
Step 1. There are no repeating attributes or lists within a column
DROP TABLE IF EXISTS author_1nf;
CREATE TABLE author_1nf
(
id INTEGER,
author VARCHAR(50),
birth_year INTEGER,
books VARCHAR
);
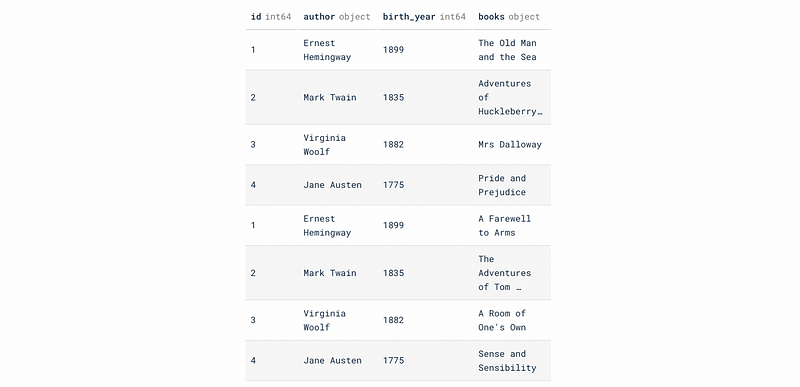
INSERT INTO author_1nf (
SELECT id, author, birth_year, two_books[1]
FROM author
);
INSERT INTO author_1nf (
SELECT id, author, birth_year, two_books[2]
FROM author
);
Step 2. Assign a primary key for the relation
FD: id, books → author; id, books → birth_year.
Thus, the PRIMARY KEY should be (id, books)
ALTER TABLE author_1nf ADD PRIMARY KEY (id, books);
- With the 1NF result, how to change this relation to 2NF?
Step 1. Remove any partial dependency.
PD: id → author, birth_year
Thus, we have to split the relation into two smaller relations, author_2nf, and books. First, let’s create them all,
DROP TABLE IF EXISTS author_2nf, books CASCADE;
CREATE TABLE author_2nf
(
id INTEGER,
author VARCHAR(50),
birth_year INTEGER
);
CREATE TABLE books
(
author_id INTEGER,
book VARCHAR
);
Then we insert data to them,
INSERT INTO author_2nf
(
SELECT DISTINCT id, author, birth_year
FROM author_1nf
);
INSERT INTO books
(
SELECT id, books
FROM author_1nf
);
Third, set the primary key because the relations should be in the 1NF forms.
ALTER TABLE author_2nf ADD PRIMARY KEY (id);
ALTER TABLE books ADD COLUMN book_id SERIAL;
ALTER TABLE books ADD PRIMARY KEY (book_id);
Last, add a foreign key to the “books” relation so that its column id will depend on the values of the author_2nf relation.
ALTER TABLE books ADD CONSTRAINT author_foreign_key FOREIGN KEY (author_id) REFERENCES author_2nf(id) ON UPDATE CASCADE ON DELETE CASCADE;
Finally, check out the results.
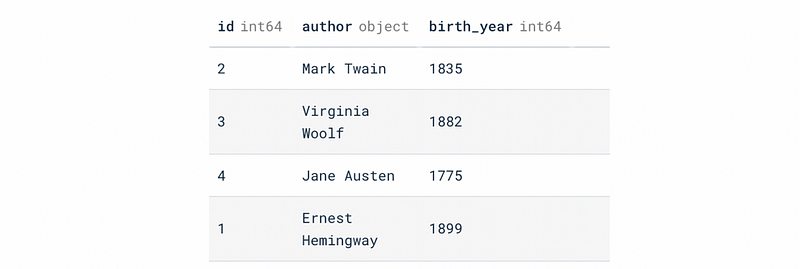
SELECT * FROM author_2nf;
SELECT * FROM books;

- Join the two split relations to create the original one.
SELECT author_2nf.*, books.book
FROM author_2nf
LEFT JOIN books
ON author_2nf.id = books.author_id;
- With the 2NF result, how to change this relation to 3NF?
TD: id → author; id → birth_year; author → birth_year.
So we have to split the 2NF relation for a 3NF result. First, let’s create two new relations,
DROP TABLE IF EXISTS author_3nf, author_birth_year;
CREATE TABLE author_3nf
(
id INTEGER PRIMARY KEY,
author VARCHAR
);
CREATE TABLE author_birth_year
(
id INTEGER PRIMARY KEY,
birth_year INTEGER
);
Then, let’s split the author_2nf relation,
INSERT INTO author_3nf (
SELECT id, author
FROM author_2nf
);
INSERT INTO author_birth_year
(
SELECT id, birth_year
FROM author_2nf
);
Third, we don’t have to assign primary keys to all of them (for 1NF purpose), this is because the newly created relations will inherit the PRIMARY KEY from the 2nf relation automatically. For example, if we try,
ALTER TABLE author_3nf ADD PRIMARY KEY (id);
ALTER TABLE author_birth_year ADD PRIMARY KEY (id);
Then there will be errors for us,
multiple primary keys for table "author_3nf" are not allowed
multiple primary keys for table "author_birth_year" are not allowed
Fourth, add a foreign key to the author_birth_year so that its id will depend on the id from the author_3nf (for 2NF purpose),
ALTER TABLE author_birth_year ADD CONSTRAINT birth_year_foreign_key FOREIGN KEY (id) REFERENCES author_3nf(id) ON UPDATE CASCADE ON DELETE CASCADE;
Also, we have to update the foreign key for the “books” relation,
ALTER TABLE books DROP CONSTRAINT author_foreign_key;
ALTER TABLE books ADD CONSTRAINT author_foreign_key FOREIGN KEY (author_id) REFERENCES author_3nf(id) ON UPDATE CASCADE ON DELETE CASCADE;
Finally, we can check them out,
SELECT * FROM author_3nf;
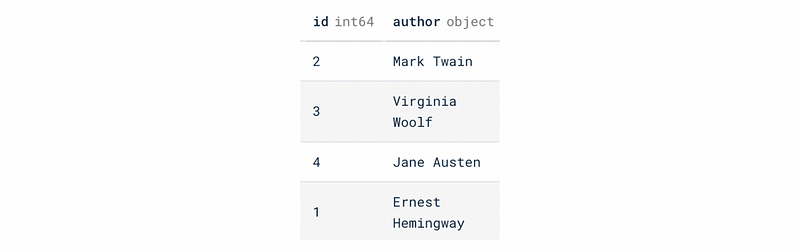
SELECT * FROM author_birth_year;
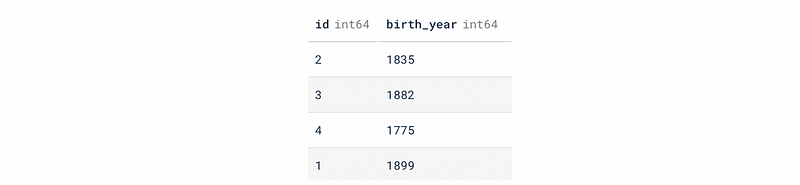
SELECT * FROM books;
- Join the three split relations of 3NF to create the original relationship.
SELECT author_3nf.*, author_birth_year.birth_year, books.book
FROM author_3nf
LEFT JOIN author_birth_year
ON author_3nf.id = author_birth_year.id
LEFT JOIN books
ON author_3nf.id = books.author_id;