Software Development Process 12 | Black-Box Testing
Software Development Process 12 | Black-Box Testing

- Black-Box Testing
(1) The Definition of Black-Box Testing
As we said at the end of the previous section, black-box testing (aka. functional testing) is the testing of the software when we look at it as a black box, as a closed box, without looking at it inside, without looking at the code.
(2) Advantages of Using Black-Box Testing
- Focus on the input domain: we can make sure we are actually covering this domain, that we are actually covering the important behaviors of the software.
- No need for the codes: you can start designing and writing your test cases, even before writing your code, so that when the code is ready, we can test it right away. This means that we can do an early test design.
- Catches logic defects: black-box testing can catch logic defects because it focuses on the description of what the software should do, and therefore on its logic.
- Applicable at all granularity levels: we can use black-box testing in unit testing, integration testing, system testing, and so on. So we can basically use it at all levels.
(3) Systemic Functional Testing Approach
Black box testing starts from a description of the software called a functional specification. The final result of black-box testing is a set of test cases, a set of actual inputs and corresponding outputs that we can use to exercise our code and to try to find defects in our code.
Going from this description to a concrete set of tests is a very complex analytical process. So what we want to do is to have a systematic approach to derive test cases from a functional specification, which will simplify the overall problem by dividing the process into elementary steps as follows,
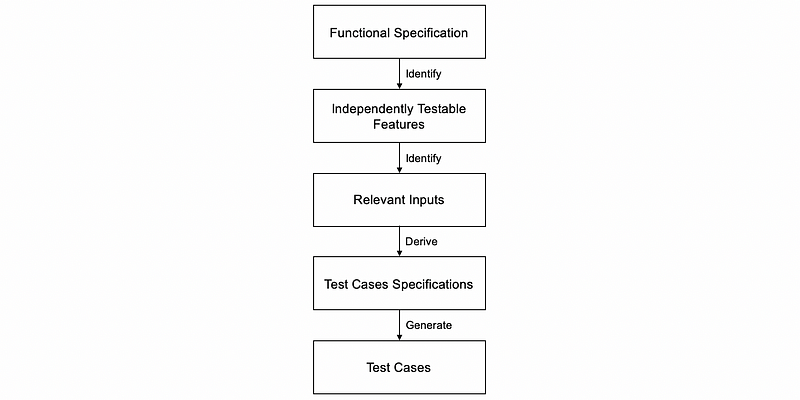
In particular, in the diagram shown above, we have to perform three main steps,
- Identify independently testable features (ITFs), which are the individual features in the software that we can test.
- Identify what are the relevant inputs, which are the inputs or the behaviors that are worth testing for these features.
- Derive test specifications, which are descriptions of the test cases that we can then use to generate actual test cases.
The systemic approach in this way has many advantages,
- It allows for dividing brain intensive steps from steps that can be automated
- It allows you for monitoring the testing process.
(4) Identify ITF Examples
For simple function printSum(int a, int b) used to add and print two numbers, there is only one feature that we can test for adding two numbers.
For the Microsoft Excel spreadsheet, there are many ITFs we can test,
- Cell Merging
- Chart Creation
- Statistical Function
- etc.
(5) Test Data Selection
Once we have identified independently testable features, the next step is to identify the relevant inputs for each one of these features. The problem of identifying relevant inputs for some software or some feature of it is called test data selection and can be expressed as followed. As usual, we have,
- Input domain: the set of inputs for all the software
- Output domain: the set of corresponding outlets for these inputs
So the question here is, how can we select a meaningful set of inputs in my domain? There are basically some ideas,
- Exhaustive Testing: one possible idea is to test them all. We can do all the inputs if we have powerful machines or if we have a lot of computational power in the cloud. For example, if we want to do exhaustive testing on the function
printSum(int a, int b), we have to take all the integer combinations into the consideration and it’s going to take 600 years for a modern computer. So the bottom line here is that we just can’t do exhaustive testing. - Random Testing: random testing means that we pick the inputs to test just as we pick a number by rolling a set of dice randomly. There are some benefits of this idea, (1) we pick inputs uniformly; (2) all inputs considered equal; (3) no designer bias, which is the developer’s assumption or preference on the user’s behaviors. However, in practice, we don’t do random testing because it is like we are looking for a needle in a haystack, and failing inputs are generally very sparse in the input domain.
- Partition Testing: Fortunately not all is lost, there is a silver lining. We can actually leverage the fact that the failures are dense in some subdomains. The domain is naturally split into partitions where partitions are areas of the domain that are treated homogeneously by the software. So rather than picking inputs randomly, we want to do two things: (1) identify partitions of our domain; (2) select inputs from each partition. By doing so, we can dramatically increase our chances to reveal faults in the code.
(6) Partition Testing Example
Let’s see the following function for splitting a string,
split(String str, int size)
Basically, we can have the following partitions,
- size < 0
- size = 0
- size > 0
- str.length ≤ size
- size < str.length ≤ size * 2
- str.length > size * 2
- etc.
(7) Boundary Values
Errors tend to occur at the boundary of a domain, or a sub-domain because these are the cases that are less understood by the developers. For example,
- the last iteration of a loop
- a special value like zero for integers
- etc.
So what is complementary to partition testing is that we want to select inputs at these boundaries. Let’s view back to the split functional example, now we can have some possible inputs,
size = -1size = 0size = 1string.length = size - 1string.length = sizestring.length = size * 1.5- etc.
(8) Deriving Test Case Specifications
Once we have identified the values of interest, we derive test case specifications for these values. And the test case specification defines how the values should be put together when actually testing the system. For example, the split function now has several test cases and we can actually put some of them together. For example,
size = -1, str.length = -2(doesn't make sense)size = -1, str.length = -1(doesn’t make sense)size = -1, str.length = 0size = 1, str.length = 0- etc.
(9) Category-Partition Method
The following step is to use these test case specifications to generate actual test cases. And this is normally a fairly mechanical step in the sense that we just have to instantiate what is in the test case specification as actual test cases.
The Category-Partition Method was defined by Ostrand & Balcer in 1988 in an article to the peer-reviewed magazine Communications of the ACM. So this is a method for going from a specification (i.e. a description of the system) to a set of test cases (e.g. any other black-box testing approach) by following six steps,
- Step 1. Identify independently testable features
- Step 2. Identify categories (i.e. characteristics of each input element): For the example of
splitfunction, the categories forstrislengthandcontent, and the category forsizeis itsvalue. - Step 3. Partition categories into choices (i.e. interesting cases or subdomains): For example,
length = 0, size-1, size, ...,content = " ", "<special characters>", ...,value = -1, 0, 1, maxInt, ... - Step 4. Identify constraints among choices: we have to do this because we need to eliminate meaningless combinations of inputs and reduce the number of test cases. There are three types of properties: a. Pair property…if… (e.g. we should have
str.length != 0if we want to test special characters); b. Error properties (e.g. we should throw an error forsize value < 0); c. Single properties (e.g. should be tested only once and should have no combination with the other test cases). - Step 5. Produce/Evaluate test case specifications: this is a step that can be completely automated given the results of the previous steps, and the final result of this step is the production of a set of test frames where a test frame is the specification of a test. For example, a test frame can be,
Test Frame #36
input str
length = size - 1
content = special characters
input size
value > 1
- Step 6. Generate test cases from test case specifications: This step mainly consists of a simple instantiation of frames and its final result is a set of concrete tests. For the test frame #36 example, we can have,
Test Case #36
str = "ABCC!\n\tΦ"
size = 10
(10) Model-Based Testing
The systemic functional testing approach is not the only way for generating the test cases, and another popular one is called the model-based testing approach.
A model is an abstract representation of the software under test. In model-based testing, the way in which we go from specifications to test cases is through the construction of a model. Also, in this case, there are many possible models, that we can use, but here in this section, we will only focus on the finite state machines (FSM) model.
(11) Finite State Machine (FSM)
At a high level, a state machine is a graph in which nodes represent states of the system. Edges represent transitions between states. And finally, the labels on the edges represent events and actions. So how do we build such a final state machine starting from a specification?
- Start from the specifications
- Identify the system’s boundaries and the I/O to the system
- Identify the relevant states and transitions within the boundaries of the system
- Refine it into several states
- Identify how the system can go from one state to another, including which inputs cause which transition, and which result in outputs we can obtain
Here are some important considerations for FSM,
- Applicability: FSM is a very general approach and we can apply the technique to state charts in UML
- Abstraction: we have to find the right abstraction of the system
- Other approaches: we can use many other models rather than FSM. For example, the decision tables, the flow graphs, and even the historical models