Software Development Process 13 | White-Box Testing
Software Development Process 13 | White-Box Testing

- White-Box Testing
(1) The Definition of White-Box Testing
As we said at the end of the previous section, white-box testing (aka. functional testing) is the testing of the software when we look inside the program, and we actually test it based on its code. And there is one basic assumption behind the idea of white-box testing, and the assumption is that executing the faulty statement is a necessary condition for revealing a fault. In other words, if there is a bug in the program there is no way for us to find this bug or this fault if we don’t execute the statement that contains it.
(2) Advantages of Using White-Box Testing
- Based on the code: So the quality of white-box testing can be measured objectively compared with black-box testing when many test cases are subjective decisions. Also, because white-box testing is based on the code, it can be measured automatically. So we can build tools and there are tools that can measure the level of white-box testing which can be achieved in a fully automated way.
- Can be used to compare test suites: if you have two alternative sets of tests that you can use to assess the quality of your software, white-box testing techniques can tell you which one of these two test suites is likely to be more effective in testing your code.
- Allows for covering the coded behavior: if there is some mistake in the code and is not obvious by looking at the specification of the code, white box testing might be able to catch it because it tries to exercise the code.
(3) Types of White-Box Testing
There are many different kinds of white-box testing, such as,
- Control-flow based techniques
- Data-flow based techniques
- Fault based techniques
In this section, we will talk about white-box testing by focusing mainly on control-flow based testing techniques.
(4) Code printSum Example
Now let’s start our lesson on white docs testing by considering again the program printSum.
printSum(int a, int b) {
int result = a + b
if (result > 0)
printcol("red", result)
else if (result < 0)
printcol("blue", result)
}In this function, it will first take two integers a and b, and produces the sum of the two. This programmer was kind of creative because instead of just adding the two numbers and printing them, he or she also decided to print them in a specific color by printcol depending on whether they were positive numbers or negative numbers. So positive results are printed in red and negative results are printed in blue.
(5) The Definition of Coverage Criteria
Coverage criteria are defined in terms of test requirements, where test requirements are the elements, the entities in the code, that we need to exercise or execute in order to satisfy the criteria.
Normally, when you apply a coverage criterion, they will result in,
- Test specifications: they are basically descriptions, or specifications, of how the tests should be in order to satisfy the requirements.
- Test cases: they are instantiations of the test specifications.
And again this is exactly analogous to what we saw when we were talking about black-box testing.
(6) Statement Coverage
Statement coverage is a specific coverage criterion and this criterion is characterized by two aspects,
- Test Requirements: for statement coverage, the test requirements are all the statements in the program.
- Coverage Measure: a good measure of how well we exercise the code, is the ratio of the number of executed statements.
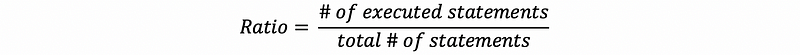
An example here is the printSum function we have mentioned. Suppose we have two test cases,
TC #1
a = 3
b = 9
TC #2
a = -5
b = -8
When we run test case #1, we actually execute the following lines in bold, and we have 5 tested lines. So the statement coverage should be 5/7 = 71%.
printSum(int a, int b) {
int result = a + b
if (result > 0)
printcol("red", result)
else if (result < 0)
printcol("blue", result)
}Then we continue to run test case #2. After running, all the statements are covered, so we are able to say that statement coverage is now 7/7 = 100%.
printSum(int a, int b) {
int result = a + b
if (result > 0)
printcol("red", result)
else if (result < 0)
printcol("blue", result)
}Normally, a company uses statement coverage criterion in the industry for targeting 80% ~ 90% of testings. And this is because the statement testing can only test the conditions included in the statements.
(7) Control Flow Graphs (CFG)
Let’s look at the code for printSum in a slightly different way by making something explicit. If we go through the code, we can see that the code does something if the result is greater than zero, does something else if the result is less than zero, and otherwise in the case in which neither of these two conditions is true, nothing really happens.
printSum(int a, int b) {
int result = a + b
if (result > 0)
printcol("red", result)
else if (result < 0)
printcol("blue", result)
[else do nothing]
}The code does nothing, in this case, where it should do something. With the help of statement coverage, we can never reach this point for either of the test cases even if we have a coverage rate of 100%. So in order to express this, we have to introduce a very useful concept of control flow graphs.
The control flow graph is just a representation of the code that is very convenient when we run our reason about the code and its structure. And it’s a fairly simple one that represents statements with nodes and the flow of control within the code with edges.
(8) Branch Coverage
Now we can leverage our knowledge of CFG by introducing the branch coverage. Again, this coverage is characterized by two aspects,
- Test Requirements: for branch coverage, the test requirements are all the branches in the program.
- Coverage Measure: a good measure of how well we exercise the code, is the ratio of the number of executed branches.
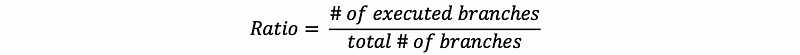
(9) Branch Coverage Example
Now let’s look back to our example,
printSum(int a, int b) {
int result = a + b
if (result > 0)
printcol("red", result)
else if (result < 0)
printcol("blue", result)
[else do nothing]
}The CFG of this program should be,
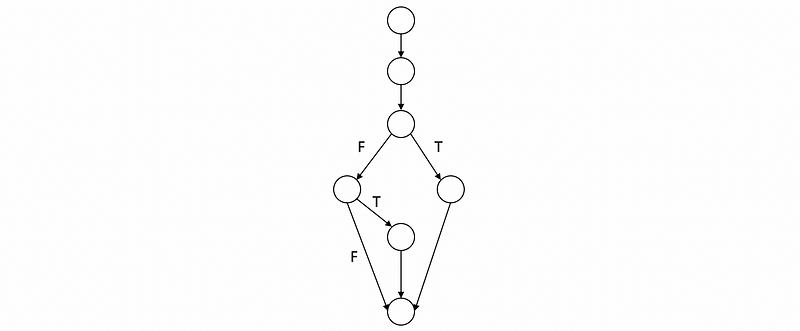
In this case, we have three branches. If we have the two cases we have mentioned the statement coverage part, we will not cover all the branches. So what happens is that we’re missing one branch.
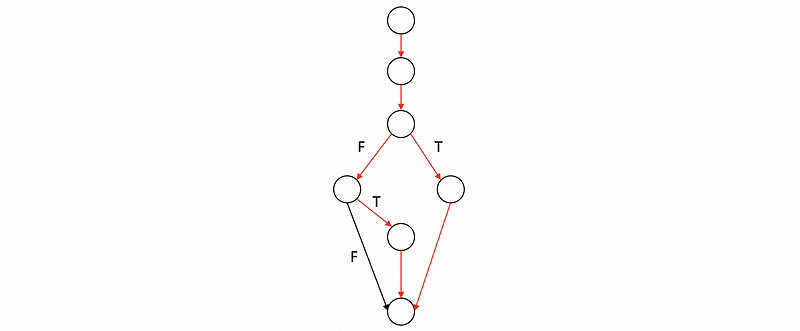
So in order to cover all the branches, the simplest possibility, in this case, is the test case for which a is equal to zero and b is equal to zero. So now if we execute this test case our execution again followed these paths, will reach our 100% branch coverage.
TC #3
a = 0
b = 0
(10) Test Criteria Subsumption
If we identify a test suite that achieves 100% branch coverage the same test suite will also necessarily achieve 100% statement coverage. That’s what happened in general because branch coverage is a stronger criterion than statement coverage.
In this case, we have a subsumption relation on branch coverage subsumes statement coverage. It also means that it is more expensive to receive branch coverage than to achieve statement coverage because achieving branch coverage requires the generation of a larger number of test cases.
(11) Branch Coverage Problem
Now, let’s think about another program example,
void main() {
float x, y;
read(x);
read(y);
if (X == 0 || y > 0)
y = y / x;
else
x = y + 2;
write(x);
write(y);
}In this case, we have the following CFG
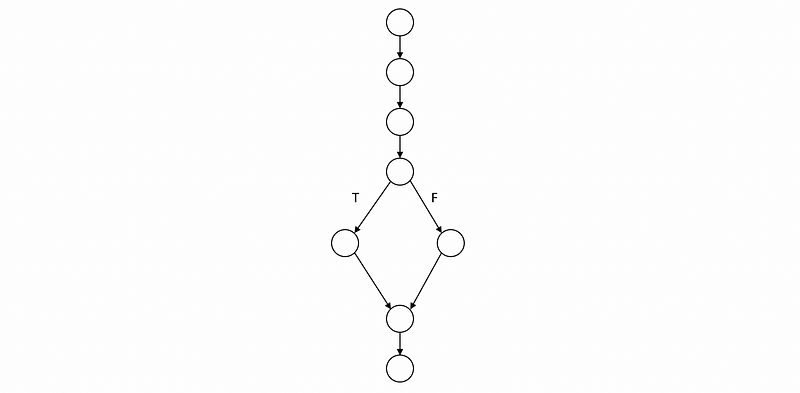
If we have the following two test cases,
TC #1
x = 5, y = 6
TC #2
x = 5, y = -5
Then we can see that these two test cases actually cover all the branches. However, we do have a case when x equals 0 and it can be an error, but we never include it in our test case even we have a 100% branch coverage. This problem brings us to the concept of condition coverage.
(12) Condition Coverage
The answer is that we can make each condition true and false instead of just considering the whole predicate here, and that’s exactly what is required by condition coverage.
- Test Requirements: for branch coverage, the test requirements are all the individual conditions in the program.
- Coverage Measure: a good measure of how well we exercise the code, is the ratio of the number of conditions that are both true and false.
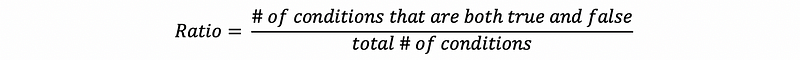
Keep in mind that the condition coverage doesn’t imply branch coverage.
(13) Branch and Condition Coverage (aka. Decision and Condition Coverage)
So normally we will have two coverage criteria we just saw, the branch coverage and the condition coverage, and this is also called the decision and condition coverage.
(14) Modified Condition/Decision Coverage (aka. MC/D Coverage or MC/DC)
Because we have to consider all the possible combinations of conditions, and they are extremely expensive to the point of being impractical. So, instead of defining that B&CC criterion, we’re going to find another one that finds a good tradeoff between the thoroughness of the tests and their cost. And this criterion is called Modified Condition/Decision Coverage.
The key idea is to test only the important combinations of conditions instead of all of them and limit the testing cost by excluding the other combinations. And the way in which it works is by extending branch and decision coverage with the requirement that each condition should affect the decision outcome independently.
You should also know that MC/DC criterion is stronger than branch and condition coverage because it requires every single condition to be true and false. And it also requires every predicate to be true and false and therefore, this section is branch coverage. In addition, it’s got the additional requirements that the true and false values, all the conditions have to also decide the overall value of the predicate.
(15) Other Criteria
We also have many other coverage criteria and we are not going to explain them all here. Here is a list of them and probably you can search for more details online. For relevant papers on this topic, you can check this out.
- Path coverage
- Data-flow coverage
- Mutation coverage